



 雷达卡
雷达卡




[size=0.76em]Modeler 中 EXCEL 数据处理
[size=0.76em]白杨, 软件工程师, IBM
[size=0.76em]转载自:http://www.ibm.com/developerworks/cn/data/library/techarticle/dm-1107baiy/
[size=0.76em]简介: 本文主要介绍 IBM SPSS Modeler 的日常应用。Modeler 不只是一款可以用于复杂数据挖掘的贵族型软件,更是一款可以在简单办公室工作中帮助大家节约时间智慧工作的平民型软件。本文通过 Modeler 帮一个高级 HR 工作人员从重复性手动操作处理 EXCEL 文件到组建串流自动处理着手,让读者跟容易的了解 Modeler 在数据处理方面的广泛应用。
[size=0.76em]发布日期: 2011 年 7 月 14 日
级别: 初级
访问情况 : 3397 次浏览
评论: 0 (查看 | 添加评论 - 登录)
 平均分 (6个评分)
平均分 (6个评分)为本文评分
[size=0.76em]Alice 是公司的一个人力资源专员。 像每个在跨国企业人力资源部工作的普通人员一样,她每天都需要和这个公司上万人员的资料数据打交道。对于一个非编程技术人员,使用 EXCEL 只可以完成一些简单的排序工作。 不会写程序,只能通过手动一条条的把自己需要的数据资料从成千上万行 excel 数据中挑选出来,分成不同的,适合不同用途的 Excel 文档是一个既浪费时间又浪费人力的体力活。这些繁琐的重复性劳动每天都占用了 Alice 大量的时间。更不要说人力劳动可能出现的小小纰漏,常常使 Alice 无可奈何的接受领导的批评。 本文将会通过对 IBM SPSS MODELER 产品基础功能的简单描述,让也许和 ALICE 有着一样困惑的您在最短的时间内之内将这些数据分割成任何你可能会需要的文件。也希望这篇对 Modeler 应用小技巧的文章,增加大家对 Modeler 产品的了解和发展 Modeler 产品的应用。
[size=0.76em]本文的数据文件是以人力资源部的员工文件为脚本,在更改了员工姓名,经理 NoteID 和部门信息等资料后选取了有代表性的 49 行资料来分析处理。这些数据包括员工姓, 名, 性别, 年龄, 工作地点,经理 Note ID, 婚姻状态 和部门等不同信息。
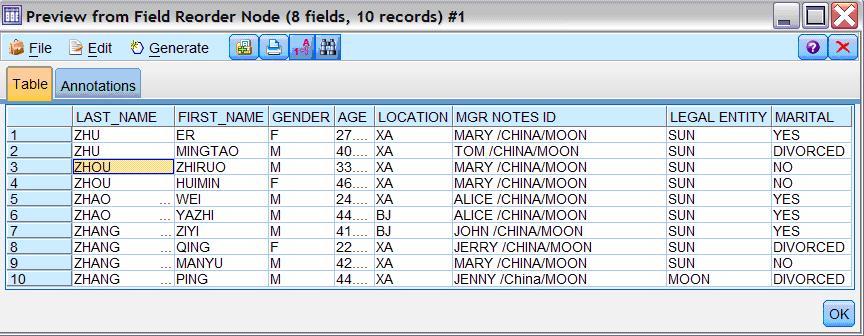
图 1. 原始数据样本
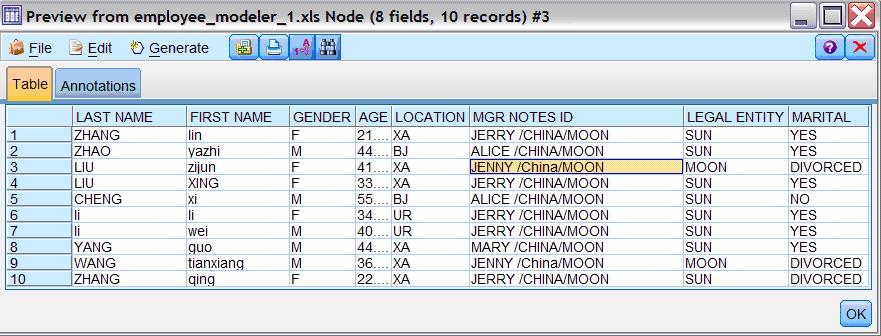
[size=0.76em]通过数据, 你会发现这些员工资料杂乱不堪,有些姓名大写输入,有些姓名小写输入。这一行是乌鲁木齐员工的资料,下一行确是北京员工的资料。整个文档没有任何顺序排列可言。您不用详细的看这份文件,只要简单操作, Modeler 就可以把这个文件变得整齐有序。您需要建一个简单的串流 (stream)。首先,打开 IBM SPSS Modeler, 在软件下方的 sources 选择一个符合条件的数据源节点。鉴于我们的源文件是 EXCEL,从左到右排第九的 Excel 节点最符合条件。
图 2. Modeler Source Node Palette

[size=0.76em]我们将 EXCEL 节点拖到 Modeler 操作屏幕中,双击。 在 import file 的地方输入 EXCEL 文件的路径, 如下图所示,现在您的数据源就是您要修改的文件了。单击 OK。
图 3. Modeler Excel Source Node Configure Window
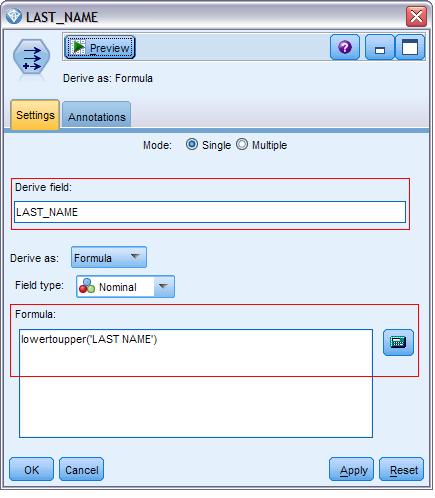
[size=0.76em]紧接着,我们从 Field Ops tab 下,将排在第二个的 Type 节点拖到 Excel 数据源节点后面,按右键,选择 connect 链接两个节点。下来,将同样在 Fields Opts tab 下排第四位的 Derive 节点用同样的方式,和 Type 节点连接起来。双击点开 Derive 节点。 作如下红框所标设置。这个设置的作用是将所有的 last name 输入值统一变成大写字母。 在拖入一个 Derive 节点,对 first name 做同样的设置。现在, 我们所有有关姓名的输入都应该统一成大写字母了。
图 4. Modeler Derive Node Configure Window
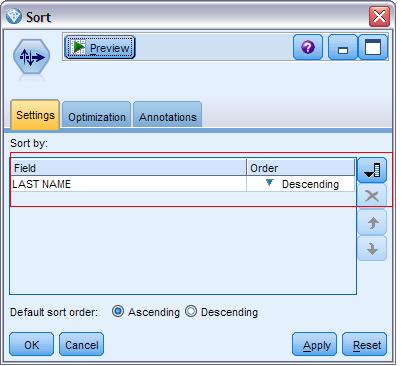
[size=0.76em]接着, 在 Record Tab 下, 选择排在第六个的 sort 节点。 连接 First_Name derive 节点和 sort 节点。双击 sort 节点来打开设置页面, 按右面的下拉按键, 选择您需要排序的数据列, 做如下设置。
图 5. Modeler Sort Node Configure Window
[size=0.76em]现在我们的数据里姓名列已经全部大写了, 然后根据 last name( 姓 ) 进行了排序。我们只需要再做两步简单的设置就可以得到一个排列整齐有规律的 Excel 文件了。
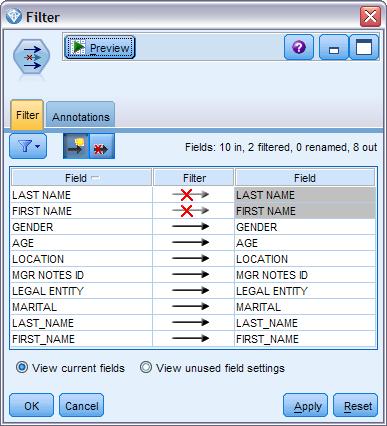
[size=0.76em]现在,我们在 sort 节点后面加入一个在 Field Opts tab 下排名第三的 Filter 节点。 Filter 节点可以帮我们简化数据。如果你有 20 列不同的数据,但是在一个文件中有 10 列不需要,您可以通过 filter 节点将其删掉。在这条串流中,因为我们通过 Derive 节点生成了两个新的数据列, Last_name 和 First_name,所以原来的字母有大写有小写的姓名数据列,现在需要被删掉。在 filter 节点中,你只需要在箭头上点一下,箭头上就会出现一个红 X,这条数据列就会被自动删除, 如下图所示。
图 6. Modeler Filter Node Configure Window
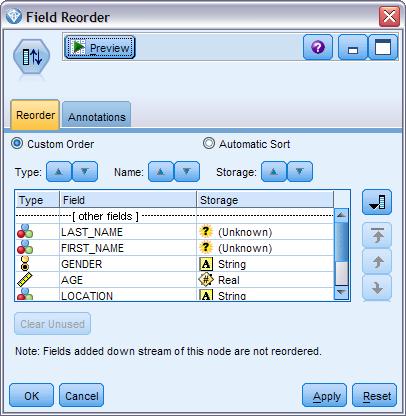
[size=0.76em]现在我们的输出数据基本符合我们最初的要求了。 只是数据列的顺序比较乱。 这个时候我们可以连接一个位于 Field Ops 最后一个的 Field Reorder 节点。这个节点可以让我们为数据列手动排序。 像这种数据,我们一般会把姓放成第一列,名放做第二列,等等。
[size=0.76em]具体设置如下图所示:
图 7. Modeler Field Reorder Node Configure Window
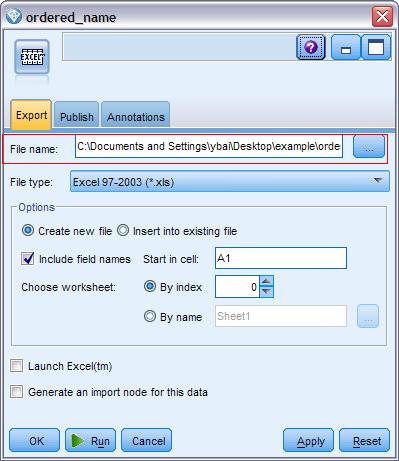
[size=0.76em]最后我们连接一个输出节点讲所有的数据输出成我们喜欢的文件类型。 本文以 EXCEL 为例,双击打开位于 Export tab 下的 Excel 节点,在文件姓名里填入你希望输出的文件路径和文件名。 点击 Run,该串流就开始自动运行。具体设置如下:
图 8.Modeler Excel Export Node Configure Window
[size=0.76em]这个串流就建好了, 整体效果图如下:
图 9. 创建好的 Modeler Stream
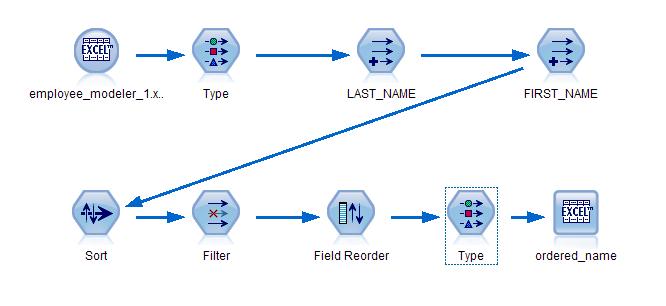
[size=0.76em]这个串流读入了原始的 EXCEL 数据,使用一个 type 节点进行了数据准备, 然后通过两个 derive 节点把所有姓名变成统一的大写字体,接着用一个 sort 节点把所有的姓按从 Z 到 A 的顺序 ( 也可以用从 A 到 Z) 排列了出来,下面通过一个 field reorder 节点把所有的列按照重要性进行排序,最后通过一个输出节点产生了新的 EXCEL 文件, 我们通过这个串流把此文件命名为 ordered_name.xls。详细 EXCEL 文件请参考附件, ordered_names.xls 。现在看起来是不是整齐多了!局部选样如下:
图 10. 经过 Modeler 处理过的数据结果选样
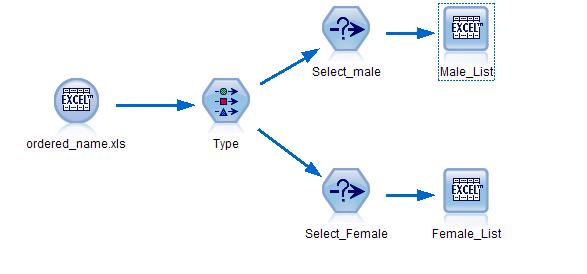
[size=0.76em]一年一度的三八妇女节到了, 每位在公司工作的女性员工都可以获得一份节日礼品。采用如下的串流(stream), Modeler 会根据性别不同自动把一个 EXCEL 文件分成两份不同的 EXCEL 文件。在这里,我们采用上段整理过的 EXCEL 文件作为源文件。
图 11. Modeler Stream 实现
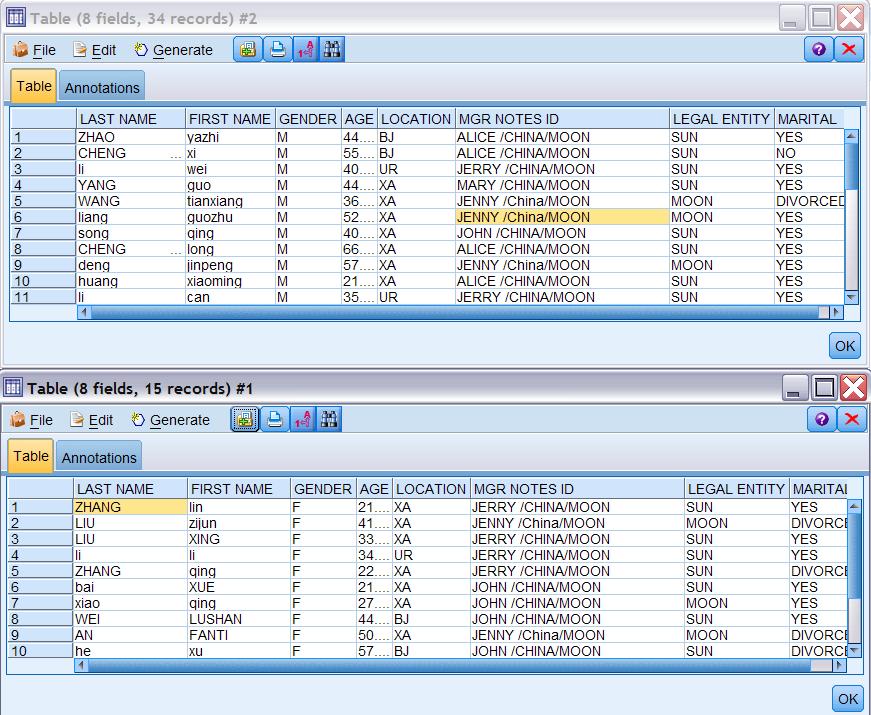
[size=0.76em]在 Modeler 使用中, select 节点常常被用来把大量的数据按照不同的特性分成不同的文件。在这个例子中, 我们使用 select 节点把文件中的男女分成两个 EXCEL 文件。 这样对男女有别的公司活动,我们可以直接根据不同的 EXCEL 文件来制作邮件通讯组或者人数统计等不同应用
图 12. 图 11 Stream 输出结果的样本,上图为男性员工资料截图,下图为女性员工资料截图
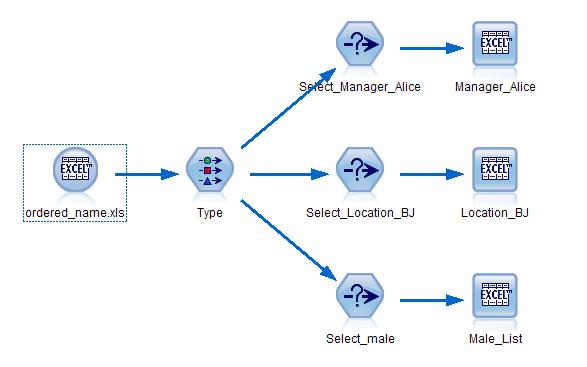
[size=0.76em]这种区分男女的方法的串流通过微小的改变还可以应用到根据婚姻状况来分文件, 根据部门地点来分文件,根据直属经理来分文件等等不同应用,大大方便了我们的统计整理工作。案例如下:
图 13. Modeler Stream 实例
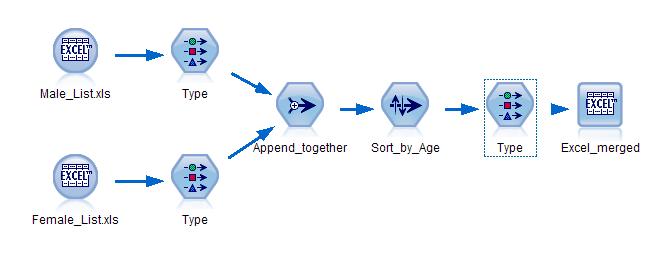
[size=0.76em]不论您的资料文件有几万行,几十列, 只要您明确的知道自己想要如何去分类这些文件,Modeler 都可以简单直观的帮您做到。您的资料可以在最短的时间内被区分成成百上千个不同的资料。然而 Modeler 对于资料整理的作用不止如此。您可以用 Modeler 把大文件分成小文件, 您同样可以使用 Modeler 方便简洁的把小文件合并成大文件。在下面这个串流里面,我们利用 modeler 把两个分开的文件合并到了一起。
图 14. Modeler Stream 合并文件
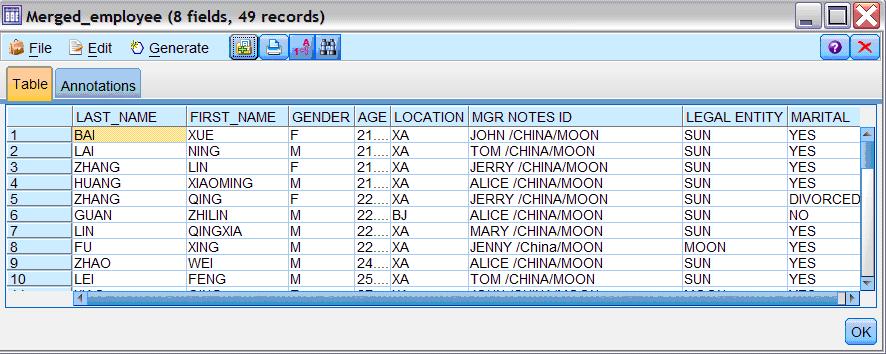
[size=0.76em]生成的 EXCEL 文件将和最初的一样, 把所有不同分类的员工全部放在一起。局部选样如下:
图 15. 输出结果样本
[size=0.76em]这两个 excel 文件就是我们通过上一段制造出来的两个以性别区分员工资料的文档。 如果有一天我们需要全体员工的资料。我们可以把它们和一个 append 节点合并起来。再加上一个 sort 节点,让这些数据按年龄从小到大排列。 最后输出到一个总文件里面。因为这两个数据的数列是一样的,最后我们会得到一个和我们文章最开始的数据一样的 EXCEL 表。当然, Modeler 的应用不仅仅是针对列名一样的 EXCEL 表, 对于有一个有几个或者完全没有公共列的 EXCEL 数据, Modeler 也可以采用 merge 节点进行合并。
[size=0.76em]上面的这些仅仅描述了 Modeler 冰山一角的小小应用。也许您自己写程序, 或者使用其他的软件也可以达到一样的功能。可是 Modeler 简单明了的界面, 立体美观的图形,便于理解的设计,快速准确的结果绝对是用户对数据进行简单处理的绝佳选择。即使您只是一个对技术一窍不通的文职人员,Modeler 也可以让你在最短的时间内学会根据需求处理这些数据。不仅如此,Modeler 还支持包括数据库,可变文件,固定文件,统计文件,Cognos BI 文件,SAS 文件, XML 文件, 用户自主输入文件等种种不同的数据源。 你可以通过样本,平衡,排序,合并等种种方式准备您的数据,然后再通过建模来进行数据分析; 或者简单的像本文所示一样分成或者合并成各种你需要的文件; 又或者让这些数据变成各种您想要的图形。对于普通笔记本电脑无法完成的庞大数据计算,您还可以通过连接包括 DB2, Oracle, SQLserver 等等数据库来帮助计算。希望有兴趣的同事们可以和我一起关注 Modeler 的成长。最后,谢谢您的阅读。
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡





 京公网安备 11010802022788号
京公网安备 11010802022788号







