



 雷达卡
雷达卡
















Learn how to implement recursive neural networks in TensorFlow, which can be used to learn tree-like structures, or directed acyclic graphs.
By Alireza Nejati, University of Auckland.
For the past few days I’ve been working on how to implement recursive neural networks in TensorFlow. Recursive neural networks (which I’ll call TreeNets from now on to avoid confusion with recurrent neural nets) can be used for learning tree-like structures (more generally, directed acyclic graph structures). They are highly useful for parsing natural scenes and language; see the work of Richard Socher (2011) for examples. More recently, in 2014, Ozan İrsoy used a deep variant of TreeNets to obtain some interesting NLP results.<The best way to explain TreeNet architecture is, I think, to compare with other kinds of architectures, for example with RNNs:
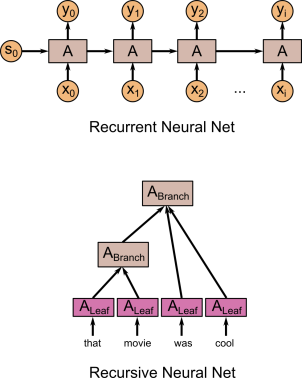
In RNNs, at each time step the network takes as input its previous state s(t-1) and its current input x(t) and produces an output y(t) and a new hidden state s(t). TreeNets, on the other hand, don’t have a simple linear structure like that. With RNNs, you can ‘unroll’ the net and think of it as a large feedforward net with inputs x(0), x(1), …, x(T), initial state s(0), and outputs y(0),y(1),…,y(T), with T varying depending on the input data stream, and the weights in each of the cells tied with each other. You can also think of TreeNets by unrolling them – the weights in each branch node are tied with each other, and the weights in each leaf node are tied with each other. The TreeNet illustrated above has different numbers of inputs in the branch nodes. Usually, we just restrict the TreeNet to be a binary tree – each node either has one or two input nodes. There may be different types of branch nodes, but branch nodes of the same type have tied weights.The advantage of TreeNets is that they can be very powerful in learning hierarchical, tree-like structure. The disadvantages are, firstly, that the tree structure of every input sample must be known at training time. We will represent the tree structure like this (lisp-like notation):(S (NP that movie) (VP was) (ADJP cool))
In each sub-expression, the type of the sub-expression must be given – in this case, we are parsing a sentence, and the type of the sub-expression is simply the part-of-speech (POS) tag. You can see that expressions with three elements (one head and two tail elements) correspond to binary operations, whereas those with four elements (one head and three tail elements) correspond to trinary operations, etc.The second disadvantage of TreeNets is that training is hard because the tree structure changes for each training sample and it’s not easy to map training to mini-batches and so on.Implementation in TensorFlow
There are a few methods for training TreeNets. The method we’re going to be using is a method that is probably the simplest, conceptually. It consists of simply assigning a tensor to every single intermediate form. So, for instance, imagine that we want to train on simple mathematical expressions, and our input expressions are the following (in lisp-like notation):1(+ 1 2)(* (+ 2 1) 2)(+ (* 1 2) (+ 2 1))
Now our full list of intermediate forms is:a = 1b = 2c = (+ a b)d = (+ b a)e = (* d b)f = (* a b)g = (+ f d)
For example, f = (* 1 2), and g = (+ (* 1 2) (+ 2 1)). We can see that all of our intermediate forms are simple expressions of other intermediate forms (or inputs). Each of these corresponds to a separate sub-graph in our tensorflow graph. So, for instance, for *, we would have two matrices W_times_l andW_times_r, and one bias vector bias_times. And for computing f, we would have:f = relu(W_times_l * a + W_times_r * b + bias_times)
Similarly, for computing d we would have:d = relu(W_plus_l * b + W_plus_r * a + bias_plus)
The full intermediate graph (excluding input and loss calculation) looks like:a = W_input * [1, 0]b = W_input * [0, 1]c = relu(W_plus_l * a + W_plus_r * b + bias_plus)d = relu(W_plus_l * b + W_plus_r * a + bias_plus)e = relu(W_times_l * d + W_times_r * b + bias_times)f = relu(W_times_l * a + W_times_r * b + bias_times)g = relu(W_plus_l * f + W_plus_r * d + bias_plus)output1 = sigmoid(W_output * a)output2 = sigmoid(W_output * c)output3 = sigmoid(W_output * e)output4 = sigmoid(W_output * g)
For training, we simply initialize our inputs and outputs as one-hot vectors (here, we’ve set the symbol 1 to [1, 0] and the symbol 2 to [0, 1]), and perform gradient descent over all W and bias matrices in our graph. The advantage of this method is that, as I said, it’s straightforward and easy to implement. The disadvantage is that our graph complexity grows as a function of the input size. This isn’t as bad as it seems at first, because no matter how big our data set becomes, there will only ever be one training example (since the entire data set is trained simultaneously) and so even though the size of the graph grows, we only need a single pass through the graph per training epoch. However, it seems likely that if our graph grows to very large size (millions of data points) then we need to look at batch training.Batch training actually isn’t that hard to implement; it just makes it a bit harder to see the flow of information. We can represent a ‘batch’ as a list of variables: [a, b, c]. So, in our previous example, we could replace the operations with two batch operations:[a, b] = W_input * [[1, 0], [0, 1]][c, d, g] = relu(W_plus_l * [a, b, f] + W_plus_r * [b, a, d] + bias_plus)[e, f] = relu(W_times_l * [d, a] + W_times_r * [b, b] + bias_times)output = sigmoid(W_output * [a, c, e, g])
You’ll immediately notice that even though we’ve rewritten it in a batch way, the order of variables inside the batches is totally random and inconsistent. This is the problem with batch training in this model: the batches need to be constructed separately for each pass through the network. If we think of the input as being a huge matrix where each row (or column) of the matrix is the vector corresponding to each intermediate form (so [a, b, c, d, e, f, g]) then we can pick out the variables corresponding to each batch using tensorflow’s tf.gather function. So for instance, gathering the indices [1, 0, 3] from [a, b, c, d, e, f, g]would give [b, a, d], which is one of the sub-batches we need. The total number of sub-batches we need is two for every binary operation and one for every unary operation in the model.For the sake of simplicity, I’ve only implemented the first (non-batch) version in TensorFlow, and my early experiments show that it works. For example, consider predicting the parity (even or odd-ness) of a number given as an expression. So 1would have parity 1, (+ 1 1) (which is equal to 2) would have parity 0, (+ 1 (* (+ 1 1) (+ 1 1))) (which is equal to 5) would have parity 1, and so on. Training a TreeNet on the following small set of training examples:1[+,1,1][*,1,1][*,[+,1,1],[+,1,1]][+,[+,1,1],[+,1,1]][+,[+,1,1],1 ][+,1,[+,1,1]]
Seems to be enough for it to ‘get the point’ of parity, and it is capable of correctly predicting the parity of much more complicated inputs, for instance:[+,[+,[+,1,1],[+,[+,1,1],[+,1,1]]],1]
Correctly, with very high accuracy (>99.9%), with accuracy only diminishing once the size of the inputs becomes very large. The code is just a single python file which you can download and run here. I’ll give some more updates on more interesting problems in the next post and also release more code.Bio: Al Nejati is a research fellow at the University of Auckland. He completed his PhD in engineering science in 2015. He is interested in machine learning, image/signal processing, Bayesian statistics, and biomedical engineering.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡




 京公网安备 11010802022788号
京公网安备 11010802022788号







