



 雷达卡
雷达卡
















This post looks a little deeper and examines the associations between different tools, their relationship to Big Data and Deep Learning, and regional patterns. At the end of the post there is a link to anonymized dataset, so that you can do your own analysis (and let me know about the results in comments below).
The question asked in KDnuggets Poll was
What software you used for Analytics, Data Mining, Data Science, Machine Learning projects in the past 12 months?
Thus, if tools are used together by the same voter it does not imply that they are used on the sameproject, but we can assume some affinity between those tools, since data scientists tend to use their favorite tool combinations on many projects.
First, we looked at associations between the top 10 tools.
There are many ways to measure how significant is associations between two nominal or binary features, like chi-square or T-test, but as we did in our 2015 analysis (Which Big Data, Data Mining, and Data Science Tools go together?), we used a simple measure we call "Lift", defined as
Lift (X & Y) = pct (X & Y) / ( pct (X) * pct (Y) )
where pct(X) is the percent of users who selected X.
Lift (X&Y) > 1 indicates that X&Y appear together more than expected if they were independent,
Lift=1 if X & Y appear with frequency expected if they are independent, and
Lift < 1 if X & Y appear together less than expected (negatively correlated)
Fig. 1 below shows the pairwise lift between the top 10 tools. The diagonal is left blank, since we don't need a lift between a tool and itself.
Note that the chart is symmetric relative to the diagonal, since the lift measure is symmetric:
Lift (X & Y) = Lift (Y & X).
However we show both upper and lower triangles of the chart to make it easier to see patterns across rows and columns.
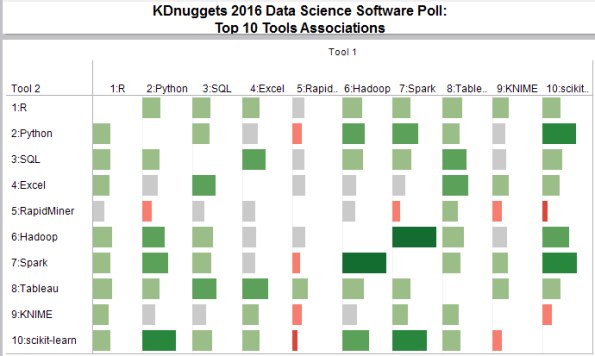
Fig. 1: KDnuggets Data Science Software Poll Top 10 tools, Pairwise lift
We note R and Python generally "play" well with other tools except RapidMiner, SQL and Excel go well with Tableau, RapidMiner is used less with other tools than average, while Hadoop and Spark used more with other tools. Not surprisingly, scikit-learn is used most with Python, but interestingly, also with Spark.
Spark and Hadoop have the highest lift=2.66, while RapidMiner and scikit-learn have the lowest lift=0.59.
Here is the same chart with lift values shown.
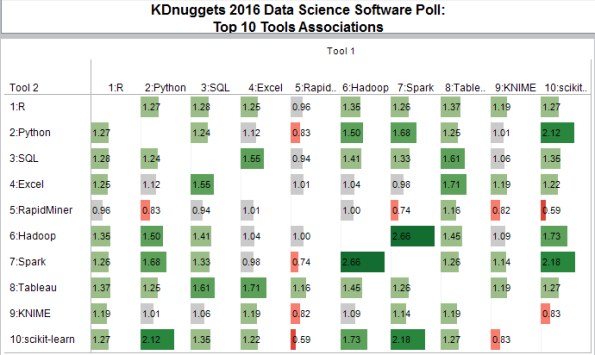
Fig. 1b: KDnuggets Data Science Software Poll Top 10 tools, Pairwise lift
Next we look at associations between top 5 commercial and top 5 free tools.
We note that R, Tableau and MATLAB "play" well with other tools, while RapidMiner users use less other tools than average.
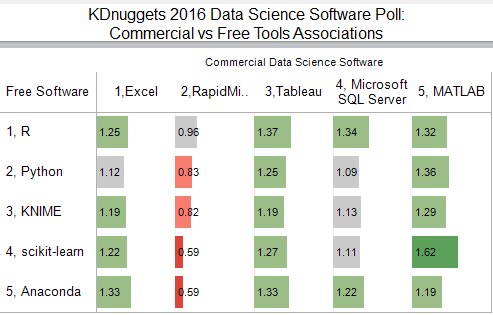
Fig. 2: KDnuggets Data Science Software Poll
Top 5 Commercial vs Top 5 Free Tools, pairwise lift
We can use a similar approach to measure the affinity of tools to R vs Python.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡






 京公网安备 11010802022788号
京公网安备 11010802022788号







