



 雷达卡
雷达卡
















By Charles H Martin, Calculation Consulting.
The naive interpretation is that these are highly non-convex methods, and therefore should not scale at all. I will address this issue since this is critical to understanding scaling.
(This is different than making things go fast or making solvers converge better, and I don’t address this)
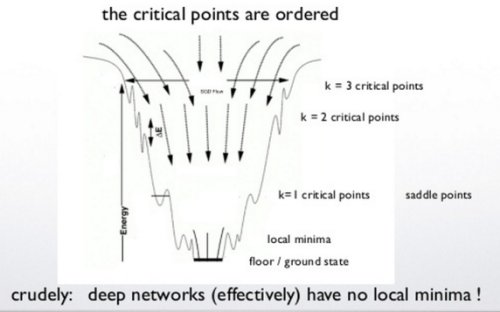
A common theme today is that the energy functions on very large dimensional spaces have no low lying local minima, except those very close to the ground state.
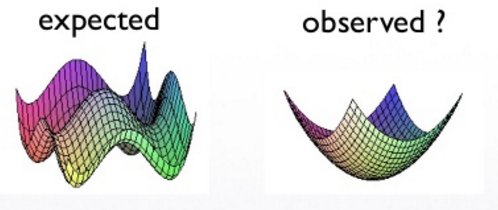
This has been recently popularized by LeCun
The Loss Surfaces of Multilayer Networks (2015)
https://arxiv.org/pdf/1412.0233v...
and by Bengio and others, using methods like Hessian Free solvers
This is justified from computations at Google & Stanford
Qualitatively Characterizing Neural Network Optimization Problems
http://arxiv.org/pdf/1412.6544v4...
And indeed, it appears to be the case for many systems.
Theoretically, this might be justified using some recent analytic results on the p-spin spherical glass
Note that this the general idea has been suspected for a very long time—at least 15 years. See, for example, section 6.4.4 of the book Pattern Classification, 2nd Edition (2000)
See Google books: Pattern Classification
So it has always been suspected deep networks would scale—what is puzzling is that deep neural nets do not overtrain.
An old, common belief is simply that deep nets find the local minima, and that any local minima may do. Furthermore, if we run a solver for too long, we would reach the ground state, and this is a state of overtraining. So we have no local minima, and we want to apply early stopping. Add some regularization to avoid overfitting, and this is why deep nets scale.
This is the standard picture; it has been around 15–20 years.
This is somewhat unsatisfying to me, mainly because I find that these things are really hard to build and train without a lot of human inspection.
A neural network, like a deep MLP, will readily overtrain a small data set. But on larger data sets, it is chaotically unstable.
Indeed, it is pretty easy to make a network totally diverge (test and training accuracy) by simply running for a very long time. Other methods, like SVMs, may perform poorly, but they rarely behave like this (except in cases when, say, the variance explodes)
Here is an example of an exploding network, using a naive 5-layer MLP, trained with TensorFlow, using the infiminist data set.
CalculatedContent/big_deep_simple_mlp
Of course, we know that gradients can explode in simple networks, and it is necessary to damp the gradients to prevent this. But it is not exactly automated. This is what I mean by unstable.
To address this, I have been working on this, with some collaborators at UC Berkeley, on a general theory for Why Deep Learning Works
CC mmds talk 2106 (video coming soon)
The new idea is that, when a Deep Network is being trained, if it is designed properly, it behaves like a Spin Glass of Minimal Frustration (first postulated to explain protein folding)
Therefore, the energy landscape not only lacks local minima, but it also forms an n-dimensional funnel-like shape during training, which causes the energy landscape to acquire a strong attractor. This attractor works analogously to a critical point in statistical mechanics, described using renormalization group equations
Why Deep Learning Works II: the Renormalization Group
Indeed, it seems that RBMs at least looks like it is solving a form of the variational renormalization group equations, in a rough sense.
This means deep networks are operating a sub-critical point, balanced between order and chaos. This also means that any generalization bound has to be strongly data dependent, and that the VC approach is not so useful.
These ideas are supported by looking at recent dynamical simulations and analysis using statistical mechanics
Exponential expressivity in deep neural networks through transient chaos (2016)
https://arxiv.org/pdf/1606.05340...
This would also suggest that deep networks would do well when they are self-similar, as self-similar solutions solve the RG equations. And, indeed, recent work suggests that very deep networks can be trained when they are self similar
FractalNet: Ultra-Deep Neural Networks without Residuals (2016)
Furthermore, recent work shows that real systems like textual / nlp datasets also display long tail correlations in the mutual information. This is characteristic of critical / subcritical behavior
Critical Behavior from Deep Dynamics: A Hidden Dimension in Natural Language (2016)
I believe I am the first to characterize why deep nets work using the strongly correlated Random Energy Model. That is, I extend the approach by LeCun, which uses the p-spherical spin glass, by extending the spin glass model to include strong correlations, induced by the data itself. This gives a very different, new picture of why deep learning works.
Good networks behave very well; bad networks diverge. That means that when say we don’t have enough regularization, we can haveboth the test accuracy and the training accuracy diverge. And this is quite different than the VC description, where overtraining is a problem, not complete divergence. And there is no notion of dynamical stability in VC theory, which is critical for deep networks to function.
So why do deep nets scale well with training data ? My hypothesis: A deep net, when trained on a lot of well labelled data, behaves like a spin glass of minimal frustration. There is a trade off between the Energy to match the training data and the inherent Entropy of the network itself. A good training set will modify the Energy Landscape , which is otherwise wide and degenerate, causing it become punctuated with deep wells, acting like chaotic dynamical attractors.
Furthermore, the stable attract is analogous to a subcritical point in a physical system, and the deep layers renormalize the free energy at each layer, with each layer keeping the others ‘in balance’. Regularization acts like a temperature control, keeping the system from collapsing into a glassy state , where overtraining occurs.
Bio: Charles H Martin, PhD, is a Data Scientist & Machine Learning Expert in San Francisco Bay Area, currently with Calculation Consulting.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡




 京公网安备 11010802022788号
京公网安备 11010802022788号







