



 雷达卡
雷达卡
















Deep learning has a wide range of applications, from speech recognition, computer vision, to self-driving cars and mastering the game of Go. While the concept is intuitive, the implementation is often heuristic and tedious. We will take a stab at simplifying the process, and make the technology more accessible.
ExampleWe illustrate our approach with the venerable CIFAR-10 dataset. The following code snippet will download the data from its known location to a folder “data/cifar” inside the current working directory. It also creates a data source object for later use.
> library(rpud)> ds <- rpudlCreateDataSource(
+ data.format="cifar10",
+ data.dir="data/cifar"
+ )
The training process requires us to pre-compute the mean value of the training data. The following will save the result to a file “cifar10-data.mean” inside the data source’s directory.
> rpudlFindTrainingDataMean(ds, filename="cifar10-data.mean")We then create a model object using a script named cifar10_quick_train.prototxt. The script is written in Google Protocol Buffers format. There is a local copy of the script in the rpudl folder of the rpud installation directory, which is what we will use below. The script is based on the cifar10 example of the Caffe framework. If interested, you can also find the message type definition “rpudl_model.proto” in the same local folder.
> rpudl.path <- file.path(path.package(package="rpud"), "rpudl")> model <- rpudl(
+ file.path(rpudl.path, "cifar10_quick_train.prototxt"),
+ data.source=ds
+ )
Now we are ready to train the model. The training process takes about 280 seconds on a GTX 660Ti. The result is a new model object with updated parameters. Here, we overwrite the previous model object for simplicity. Should we save the result in a separate model object, we can have a history of the trained models. It reaches about 72% accuracy after 4,000 iterations.
> system.time(model <- rpudlTrain(+ model, batch=100, iter=4000))
....
training @iter 3800, cost 0.535023, accuracy 74%
training @iter 3900, cost 0.689107, accuracy 73%
training @iter 4000, cost 0.655459, accuracy 78%
training ends with average cost of 0.951724, and accuracy 71.78%
user system elapsed
210.04 70.17 279.78
We then resume the training with a smaller learning rate. It takes about 72 seconds for another 1,000 iterations, and improves the accuracy to 75%.
> system.time(model <- rpudlTrain(+ model, batch=100, iter=1000, learning.rate=0.0001)
+ )
....
training @iter 4800, cost 0.416993, accuracy 72%
training @iter 4900, cost 0.43716, accuracy 79%
training @iter 5000, cost 0.456889, accuracy 77%
training ends with average cost of 0.874285, and accuracy 75.43%
user system elapsed
53.97 18.06 71.92
For demonstration purpose, we extract 12 samples from the testing data, and run prediction against the trained model.
> num <- 12> obj <- rpudlGetTestingDataSamples(ds, c(1, num))
> res <- predict(model, obj$x)
> sum((obj$y) == res)
[1] 12
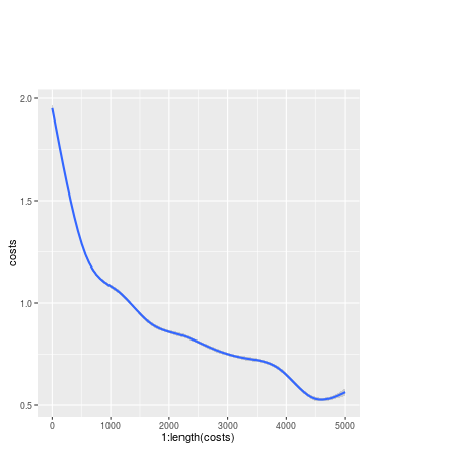
The model object keeps a history of model cost, which we can print out with the qplotmethod from the ggplot2 library.
> library(ggplot2)> costs <- model$cost.log
> qplot(1:length(costs), costs, geom="smooth")
We can also have a picture of the weight parameters of a convolutional layer using a rpudlPlotLayerWeights method.
> weights <- rpudlGetLayerWeights(model, "conv1")> rpudlPlotLayerWeights(weights)

Notes
- Currently, the rpudl methods are accessible even without an active rpudpluslicense.
- There are more examples to try out in the rpudl folder of the rpudinstallation directory.
- The supported data formats are CIFAR, MNIST and LMDB. To train with your own data, you have to export your data to an LMDB database according to the following message type:message Datum {
required bytes data = 1;
required uint32 label = 2;
}
- The current object model consists of a simple processing pipeline. It does not support Long Short-Term Memory (LSTM) or Network-In-Network (NIN) models. We will address these limitations in upcoming releases.
References
- Yangqing Jia, Evan Shelhamer, et al: Caffe - A Deep Learning Frameworkhttp://caffe.berkeleyvision.org.
- Google Research: TensorFlow - An Open Source Software Library for Machine Intelligence https://www.tensorflow.org.
- Deep Learning: Theano - An Open Source Machine Learning Library forPython http://deeplearning.net/software/theano.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡





 京公网安备 11010802022788号
京公网安备 11010802022788号







