



 雷达卡
雷达卡
















In the on-going series of posts about the IMDB dataset, from Kaggle, I have so far looked at several of the scraped variables, including the number of faces on movie posters (1, 2), plot keywords (3), and movie rating by title year (4).
In this post, I tackle the variables resulting from a data merge between IMDB and Facebook. These columns have names like "Director Facebook Likes", "Actor 1 Facebook Likes", etc. I didn't investigate exactly how they did this merging. Presumably, they matched the names of the actors and directors to their official fan pages on Facebook, and took the Like counts. (I suppose identifying the right pages is not a trivial task.)
There is clearly a "theory" behind computing these variables: star power. So we should expect that movies directed by famous directors, or starring famous actors or actresses would be correlated with bigger box office receipts. The number of Facebook likes is a proxy measure for the concept of "star power" or "fame" or "popularity".
Proxies are necessary when dealing with quantities that are hard or impossible to measure directly. But be careful to choose proxies that describe the underlying quantities properly.
Facebook likes as a proxy for star power has a host of problems. For example:
- Not all actors and directors use social media, or favor social media. If they do, Facebook may not be their chosen platform. In the extreme case, some countries like China block Facebook so obviously, a Chinese actor or actress would not be investing in a Facebook presence.
- The Facebook like count is a snapshot. What is captured is count on the day on which the data was compiled. What you want is the Facebook like count in the days or weeks prior to the release of the respective movie!
- Not only the protagonists but also the fans have preference for social media platforms. Actors and directors with older followers will have different Facebook statistics than those followed by younger generations.
- All famous directors or actors have a breakthrough movie. They were nobodies before this movie, and became stars after this movie. The Facebook like count is a summary of the entire career of each person.
A quick glimpse of the data should give the analyst a pause.
[color=rgb(255, 255, 255) !important]
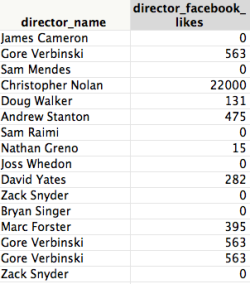
Christopher Nolan with 22,000 likes dwarfs anybody else in this snippet but James Cameron with zero? Bryan Singer, zero? Sam Mendes, zero? (This could be a data merge error, or it could be a structural problem.)
Actors are not much more telling either, as this list of the top actors shows:
[color=rgb(255, 255, 255) !important]
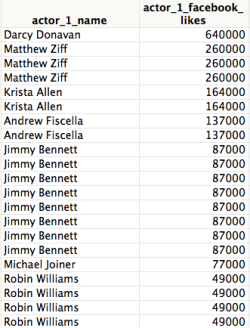
Darcy Donavan is 13 times more "famous" than Robin Williams (RIP) according to this metric. Darcy is primarily a TV actress so that's yet another issue with using Facebook likes to predict movie receipts.
Let's get back to the basic premise. We hypothesize that the Facebook like count of the director and/or top-billed actors and actresses is predictive of the movie's box office. But as you can see from Robin Williams's various entries, the Facebook like count for a given actor is invariant so if this factor is deemed useful to the model, it will contribute equally to each of Robin's movies throughout his career. When this model is used to predict revenues for early-career movies, it is using information that is out of bounds - the model in effect learned that Robin Williams would become a superstar in the future.
***
The lesson here is that proxies have lives of their own. There are a whole host of factors that drive the value of the proxy metrics. Understanding those issues and how they muddle the picture of your primary metric is essential to constructing a meaningful model.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡





 京公网安备 11010802022788号
京公网安备 11010802022788号







