



 雷达卡
雷达卡
















Introduction
Natural language processing (NLP) is all about creating systems that process or “understand” language in order to perform certain tasks. These tasks could include
- Question Answering (What Siri, Alexa, and Cortana do)
- Sentiment Analysis (Determining whether a sentence has a positive or negative connotation)
- Image to Text Mappings (Generating a caption for an input image)
- Machine Translation (Translating a paragraph of text to another language)
- Speech Recognition
- Part of Speech Tagging
- Name Entity Recognition
The traditional approach to NLP involved a lot of domain knowledge of linguistics itself. Understanding terms such as phonemes and morphemes were pretty standard as there are whole linguistic classes dedicated to their study. Let’s look at how traditional NLP would try to understand the following word.

Let’s say our goal is to gather some information about this word (characterize its sentiment, find its definition, etc). Using our domain knowledge of language, we can break up this word into 3 parts.

We understand that the prefix “un” indicates an opposing or opposite idea and we know that “ed” can specify the time period (past tense) of the word. By recognizing the meaning of the stem word “interest”, we can easily deduce the definition and sentiment of the whole word. Seems pretty simple right? However, when you consider all the different prefixes and suffixes in the English language, it would take a very skilled linguist to understand all the possible combinations and meanings.
How Deep Learning Fits In
Deep learning, at its most basic level, is all about representation learning. With CNNs, we see the composition of different filters that are used to classify objects into categories. Here, we’re going to take a similar approach with creating representations of words through large datasets.
Overview of This Post
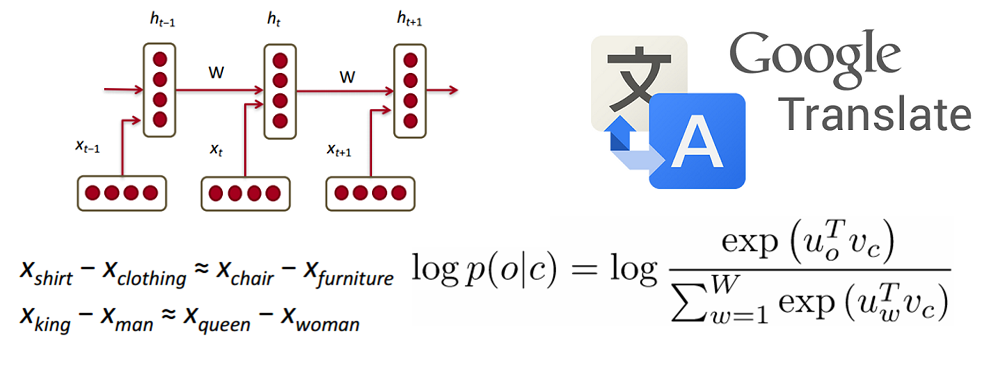
This post will be structured in a way where we’ll go through the basic building blocks of building deep networks for NLP and then go into talking about some applications through recent research papers. It’ll feel normal to not exactly know why we’re using RNNs or why an LSTM is helpful, but hopefully by the end of the research papers, you’ll have a better sense of why deep learning techniques have helped NLP so much.
Word Vectors
Since deep learning loves math, we’re going to represent each word as a d-dimensional vector. Let’s use d = 6.
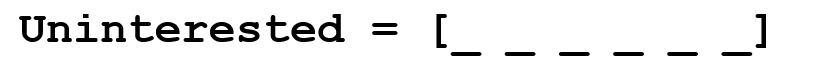
Now let’s think about how to fill in the values. We want the values to be filled in such a way that the vector somehow represents the word and its context, meaning, or semantics. One method is to create a coocurence matrix. Let’s say that we have the following sentence.
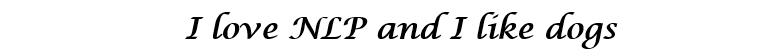
From this sentence, we want to create a word vector for each unique word.
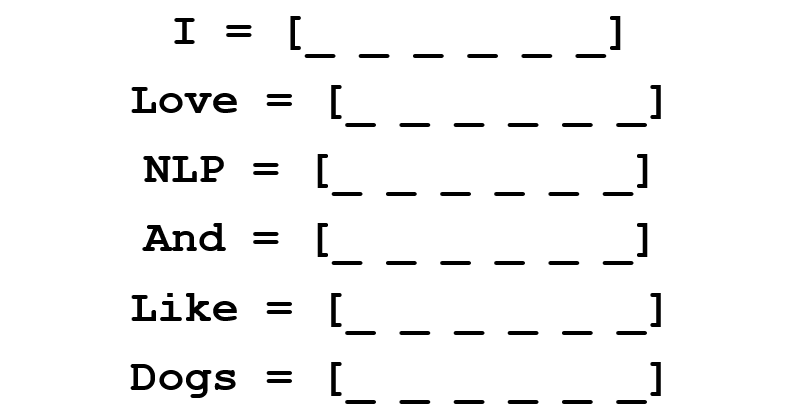
A coocurence matrix is a matrix that contains the number of counts of each word appearing next to all the other words in the corpus (or training set). Let’s visualize this matrix.
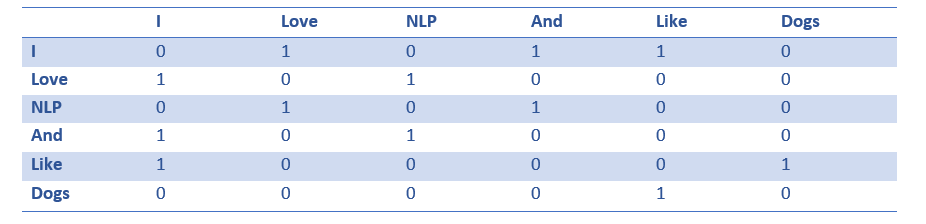
Extracting the rows from this matrix can give us a simple initialization of our word vectors.

Notice that through this simple matrix, we’re able to gain pretty useful insights. For example, notice that the words ‘love’ and ‘like’ both contain 1’s for their counts with nouns (NLP and dogs). They also have 1’s for the count with “I”, thus indicating that the words must be some sort of verb. With a larger dataset than just one sentence, you can imagine that this similarity will become more clear as ‘like’, ‘love’, and other synonyms will begin to have similar word vectors, because of the fact that they are used in similar contexts.
Now, although this a great starting point, we notice that the dimensionality of each word will increase linearly with the size of the corpus. If we had a million words (not really a lot in NLP standards), we’d have a million by million sized matrix which would be extremely sparse (lots of 0’s). Definitely not the best in terms of storage efficiency. There have been numerous advancements in finding the most optimal ways to represent these word vectors. The most famous of which is Word2Vec.
Word2Vec
The basic idea behind word vector initialization techniques is that we want to store as much information as we can in this word vector while still keeping the dimensionality at a manageable scale (25 – 1000 dimensions is ideal). Word2Vec operates on the idea that we want to predict the surrounding words of every word. Let’s take our previous sentence “I love NLP and I like dogs”. We’re going to look at the first 3 words of this sentence. 3 is thus going to be our window size m.

Now, our goal is to take the center word, ‘love’, and predict the words that come before and after it. How do we do this? By maximizing/optimizing a function of course! Formally, our function seeks to maximize the log probability of any context word given the current center word.
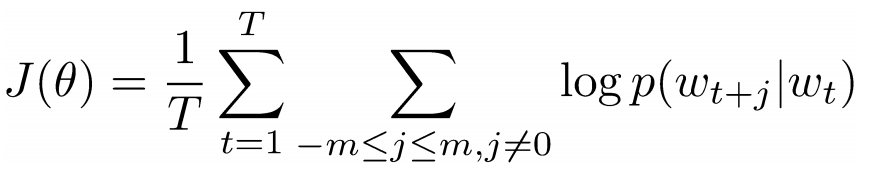
Let’s dig deeper into this. The above cost function is basically saying that we’re going to add the log probabilities of ‘I’ and ‘love’ as well as ‘NLP’ and ‘love’ (where ‘love’ is the center word in both cases). The variable T represents the number of training sentences. Let’s look closer at that log probability.
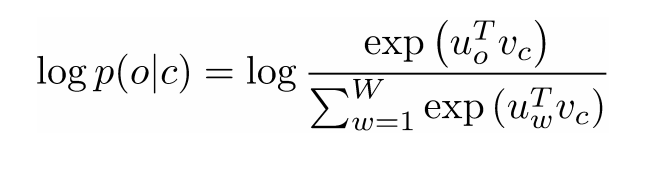
Vc is the word vector of the center word. Every word has two vector representations (Uo and Uw), one for when the word is used as the center word and one for when it’s used as the outer word. The vectors are trained with stochastic gradient descent. This is definitely one of the more confusing equations to understand, so if you’re still having trouble visualizing what’s happening, you can go here and here for additional resources.
One Sentence Summary: Word2Vec seeks to find vector representations of different words by maximizing the log probability of context words given a center word and modifying the vectors through SGD.
(Optional: The authors of the paper then go into more detail about how negative sampling and subsampling of frequent words can be used to get more precise word vectors. )
Arguably, the most interesting contribution of Word2Vec was the appearance of linear relationships between different word vectors. After training, the word vectors seemed to capture different grammatical and semantic concepts.
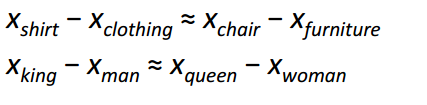
It’s pretty incredible how these linear relationships could be formed through a simple objective function and optimization technique.
Bonus: Another cool word vector initialization method: GloVe (Combines the ideas of coocurence matrices with Word2Vec)
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡



 京公网安备 11010802022788号
京公网安备 11010802022788号







