



 雷达卡
雷达卡
















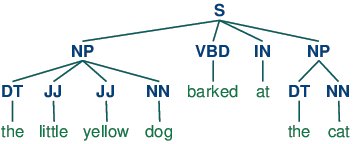
At the intersection of computational linguistics and artificial intelligence is where we find natural language processing. Very broadly, natural language processing (NLP) is a discipline which is interested in how human languages, and, to some extent, the humans who speak them, interact with technology. NLP is an interdisciplinary topic which has historically been the equal domain of artificial intelligence researchers and linguistics alike; perhaps obviously, those approaching the discipline from the linguistics side must get up to speed on technology, while those entering the discipline from the technology realm need to learn the linguistic concepts. It is this second group that this post aims to serve at an introductory level, as we take a no-nonsense approach to defining some key NLP terminology. While you certainly won't be a linguistic expert after reading this, we hope that you are better able to understand some of the NLP-related discourse, and gain perspective as to how to proceed with learning more on the topics herein. So here they are, 18 select natural language processing terms, concisely defined, with links to further reading where appropriate. 1. Natural Language Processing (NLP) Natural language processing (NLP) concerns itself with the interaction between natural human languages and computing devices. NLP is a major aspect of computational linguistics, and also falls within the realms of computer science and artificial intelligence. 2. Tokenization Tokenization is, generally, an early step in the NLP process, a step which splits longer strings of text into smaller pieces, or tokens. Larger chunks of text can be tokenized into sentences, sentences can be tokenized into words, etc. Further processing is generally performed after a piece of text has been appropriately tokenized. 3. Normalization Before further processing, text needs to be normalized. Normalization generally refers to a series of related tasks meant to put all text on a level playing field: converting all text to the same case (upper or lower), removing punctuation, expanding contractions, converting numbers to their word equivalents, and so on. Normalization puts all words on equal footing, and allows processing to proceed uniformly. 4. Stemming Stemming is the process of eliminating affixes (suffixed, prefixes, infixes, circumfixes) from a word in order to obtain a word stem. 5. Lemmatization Lemmatization is related to stemming, differing in that lemmatization is able to capture canonical forms based on a word's lemma. For example, stemming the word "better" would fail to return its citation form (another word for lemma); however, lemmatization would result in the following: It should be easy to see why the implementation of a stemmer would be the less difficult feat of the two. 6. Corpus In linguistics and NLP, corpus (literally Latin for body) refers to a collection of texts. Such collections may be formed of a single language of texts, or can span multiple languages -- there are numerous reasons for which multilingual corpora (the plural of corpus) may be useful. Corpora may also consist of themed texts (historical, Biblical, etc.). Corpora are generally solely used for statistical linguistic analysis and hypothesis testing. 7. Stop Words Stop words are those words which are filtered out before further processing of text, since these words contribute little to overall meaning, given that they are generally the most common words in a language. For instance, "the," "and," and "a," while all required words in a particular passage, don't generally contribute greatly to one's understanding of content. As a simple example, the following panagram is just as legible if the stop words are removed: 8. Parts-of-speech (POS) Tagging POS tagging consists of assigning a category tag to the tokenized parts of a sentence. The most popular POS tagging would be identifying words as nouns, verbs, adjectives, etc. 9. Statistical Language Modeling Statistical Language Modeling is the process of building a statistical language model which is meant to provide an estimate of a natural language. For a sequence of input words, the model would assign a probability to the entire sequence, which contributes to the estimated likelihood of various possible sequences. This can be especially useful for NLP applications which generate text. 10. Bag of Words Bag of words is a particular representation model used to simplify the contents of a selection of text. The bag of words model omits grammar and word order, but is interested in the number of occurrences of words within the text. The ultimate representation of the text selection is that of a bag of words (bag referring to the set theory concept of multisets, which differ from simple sets). Actual storage mechanisms for the bag of words representation can vary, but the following is a simple example using a dictionary for intuitiveness. Sample text: [size=+2] [size=+2]"There, there," said James. "There, there."本帖隐藏的内容

[size=+2]running → run
[size=+2]better → good
[size=+2]The quick brown fox jumps over the lazy dog.
[size=+2]"Well, well, well," said John.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡




 京公网安备 11010802022788号
京公网安备 11010802022788号







