



 雷达卡
雷达卡
















By Timon Ruban, Co-founder of Luminovo
Every problem worth solving needs great tools for support. Deep learning is no exception. If anything, it is a realm in which good tooling will become ever more important over the coming years. We are still in the relatively early days of the deep learning supernova, with many deep learning engineers and enthusiasts hacking their own way into efficient processes. However, we are also observing an increasing number of great tools that help facilitate the intricate process that is deep learning, making it both more accessible and more efficient. As deep learning is steadily spreading from the work of researchers and pundits into a broader field of both DL enthusiasts looking to move into the field (accessibility), and growing engineering teams that are looking to streamline their processes and reduce complexity (efficiency), we have put together an overview of the best DL tools.
A closer look at the deep learning lifecycle
To better evaluate tools that can foster accessibility and efficiency in deep learning, let’s first take a look at what the process actually looks like.
The lifecycle of a typical (supervised) deep learning application consists of different steps, starting from raw data and ending with predictions in the wild.
[size=-1]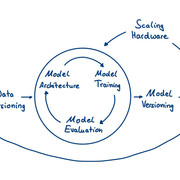 [size=-1]
[size=-1]
A typical deep learning lifecycle © 2018 Luminovo
Data Sourcing
The first step towards any deep learning application is sourcing the right data. Sometimes you are lucky and have historical data readily available. Sometimes you need to search for open-source datasets, scrape the web, buy the raw data or use a simulated dataset. Since this step is often very specific to the application at hand we did not include it in our tooling landscape. Please note, however, that there are websites like Google’s Dataset Search or Fast.ai datasets that can mitigate the problem of finding the right data.
Data Labeling
Most supervised deep learning applications deal with images, videos, text or audio, and before you train your model you need to annotate this raw data with ground-truth labels. This can be a cost-intensive and time-consuming task. In an ideal setup, this process is interwoven with model training and deployment and tries to leverage your trained deep learning models (even if their performance is not perfect yet) as much as possible.
Data Versioning
The more your data evolves over time (let’s say you set up a smart labeling process and keep retraining your models as your dataset grows) the more important it becomes to version your datasets (just as you should always version your code and your trained models).
Scaling Hardware
This step is relevant for both model training and deployment: getting access to the right hardware. When moving from local development to large-scale experiments during model training, your hardware needs to scale appropriately. The same goes for scaling according to user demand when your model is deployed.
Model Architecture
To start training your model you need to choose the model architecture of your neural network.
Note: If you have a standard problem (e.g. recognizing cats in Internet memes), this often means no more than copy-pasting the latest available state-of-the-art model from an open-source GitHub repository, but occasionally you will want to get your hands dirty and tweak the architecture of your model to improve performance. With newer approaches like Neural Architecture Search (NAS), choosing the right model architecture becomes more and more subsumed under the model training phase, but as of 2018 for most applications the marginal increase in performance of NAS is not worth the added computational cost.
This step is what people often think of when they think of coding deep learning applications, but as you can see it is just one of many and often not the most important.
Model Training
During model training you feed the labeled data to your neural network and iteratively update the model weights to minimize the loss on your training set. Once you’ve chosen your one metric (see Model Evaluation) you can train your model with many different sets of hyperparameters (e.g. which combination of learning rate, model architecture and set of preprocessing steps to choose) in a process called hyperparameter tuning.
Model Evaluation
There would be no point in training a neural network if you could not distinguish between a good and a bad model. During model evaluation you usually choose one metric to optimize for (while possibly observing many others). For this metric you try to find the best performing model that generalizes from your training data to the validation data. This involves keeping track of the different experiments (with possibly differing hyperparameters, architectures and datasets) and their performance metrics, visualizing outputs of the trained models and comparing experiments to each other. Without the right tooling, this can quickly become convoluted and confusing especially when collaborating with multiple engineers on the same deep learning pipeline.
Model Versioning
A tiny step (but still worth mentioning) between final model evaluation and model deployment: tagging your models with different versions. This allows you to easily roll back to a model version that worked well, when you discover that your newest model version does not live up to your expectations.
Model Deployment
If you have a version of your model that you are happy to put into production, you need to deploy it in a way that your users (this can be people or other applications) can talk to your model: send requests with data and get back the model’s predictions. Ideally, your tooling for model deployment supports gradual switching between different model versions, so that you can anticipate the effects of having a new model in production.
Monitoring Predictions
Once your model is deployed, you will want to keep a keen eye on the predictions it makes in the real world and get alerted to shifting data distributions and degrading performance before your users come knocking on your door, complaining about your service.
Note: The flowchart already hints at the circular nature of the typical deep learning workflow. In fact, treating the feedback loop between deployed models and new labels (often called human-in-the-loop) as a first-class citizen in your deep learning workflow can be one of the most important success factors for many applications. In real-life deep learning work things are often more complicated than the flowchart suggests. You will find yourself jumping over steps (e.g. when you are working with a pre-labeled dataset), going back several steps (model performance isn’t accurate enough and you need to source more data) or go back and forth in crazy loops (Architecture => Training => Evaluation => Training => Evaluation => Architecture).

Our Favourite Deep Learning Tools
At Luminovo, we work hard to create tools that make our engineers more efficient, as well as leverage the powerful tools that brilliant deep learning folks out there have created. Great code is meant to be shared, so the following graph presents an overview of the most promising deep learning tools currently in the market. From DL engineers for DL engineers and all those keen to learn more about creating awesome deep learning applications.
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡




 京公网安备 11010802022788号
京公网安备 11010802022788号







