


 雷达卡
雷达卡



0 前言
近年来,毕业设计与答辩的标准逐步提高,传统选题因缺乏创新性和技术亮点,往往难以满足评审要求。不少同学反馈,自己完成的系统项目在功能或深度上达不到指导老师期望,同时又难以找到完整、可参考的学习资料。
为帮助大家高效通过毕业设计环节,减少不必要的重复劳动,学长特此分享一个高质量的毕设案例供学习借鉴:
基于大数据的招聘与租房信息分析及可视化系统
综合评分(每项满分5分):
难度系数:3分
工作量:4分
创新点:5分
1 课题项目介绍
本项目由学长主导设计,采用 Python 编写网络爬虫程序,从主流招聘平台(如拉勾网)和房产租赁网站(如链家)中采集相关数据。获取的数据经过清洗、结构化处理后存储至数据库,并搭建 Web 可视化平台,对招聘信息中的薪资水平、岗位分布以及租房市场的区域、朝向、价格等关键因素进行统计分析与图形化展示。

2 相关技术概述
2.1 网络爬虫技术
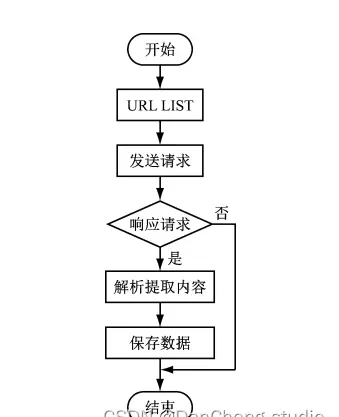
网络爬虫是一种遵循预设规则,自动抓取互联网内容的程序或脚本。它能够访问指定站点,若响应正常则下载页面内容,并通过解析模块提取其中的超链接,作为后续抓取任务的目标地址。整个过程无需人工干预,实现全自动运行。当某URL无法访问时,爬虫将依据设定策略跳转至下一个目标。
在执行过程中,爬虫支持异步请求处理,提升数据抓取效率。用户可在运行前配置代理服务器、伪造请求头信息(User-Agent、Cookies等),以增强数据获取能力,规避反爬机制。
爬虫工作流程如下图所示:
2.2 Ajax 技术原理
Ajax 是一种独立于服务器端的技术,主要用于浏览器端实现异步通信。其核心对象为 XMLHttpRequest,通过 JavaScript 向服务器发起请求并接收响应,且不会阻塞用户操作,也不需要刷新整个页面即可更新局部内容。
前端将所需参数封装成 JSON 字符串,使用 GET 或 POST 方法发送请求至服务端;后端接收请求后执行相应查询逻辑,并将结果以 JSON 格式返回;前端接收到数据后进行判断处理,动态更新页面显示内容。
示例代码如下:
$.ajax({
url: 'http://127.0.0.1:5000/updatePass',
type: "POST",
data: JSON.stringify(data.field),
contentType: "application/json; charset=utf-8",
dataType: "json",
success: function(res) {
if (res.code == 200) {
layer.msg(res.msg, {icon: 1});
} else {
layer.msg(res.msg, {icon: 2});
}
}
})
3 Echarts 数据可视化工具
ECharts(Enterprise Charts)是由百度开源的一款强大的数据可视化库,底层基于轻量级 Canvas 库 ZRender 构建。该工具兼容绝大多数主流浏览器,适用于 PC 端和移动端应用开发。
ECharts 支持多种图表类型,包括但不限于折线图、柱状图、条形图、散点图、气泡图、K线图、饼图、环形图等。开发者可通过引入 JS 文件,在 Java Web 或其他前端项目中快速集成并实现个性化图表展示,极大提升了数据分析的表现力与交互性。
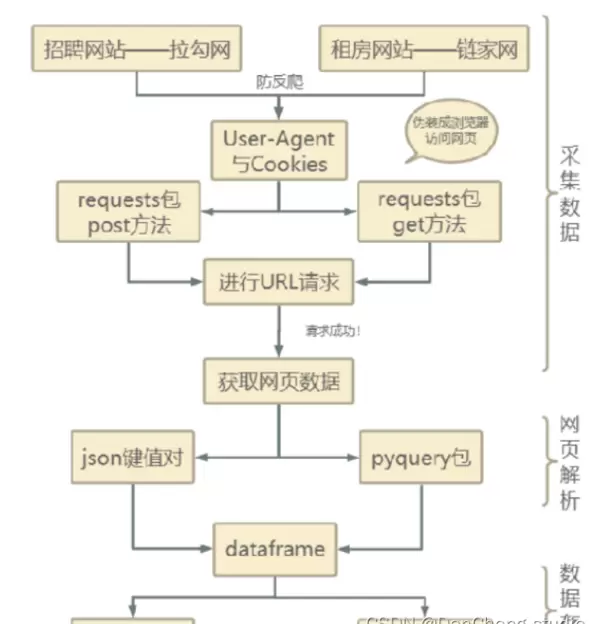
4 数据采集与处理
本系统使用 Python 的 requests 库结合 BeautifulSoup 工具,从拉勾网、链家等多个平台成功抓取了九个主要城市的招聘与租房数据。
4.1 整体数据获取流程
数据采集的整体流程包含:目标网站分析、请求构造、数据提取、清洗转换、存储入库等步骤,确保原始数据转化为结构化可用信息。
4.2 招聘数据采集方法
由于拉勾网设置了较为严格的反爬策略,因此在爬取过程中需模拟真实浏览器行为。具体做法是通过设置 User-Agent 和 Cookies 来伪装请求头,利用 requests 库的 post 方法发送请求。
请求成功后,服务器返回 JSON 格式的字符串,可通过字典形式直接解析,提取出所需的 Python 开发岗位信息。根据总职位数量与每页显示数量,计算出总页数,再通过循环逐页抓取,最终汇总所有数据,并导出为 CSV 文件,同时写入本地 MySQL 数据库中。
import requests import math import time import pandas as pd import pymysql from sqlalchemy import create_engine
5 数据可视化实现
在完成数据采集与存储之后,系统基于 Flask 搭建前后端交互架构,利用 ECharts 实现多维度的数据可视化展示,涵盖职位分布、薪资趋势、城市对比、房源特征等多个方面。
6 系统功能与展示效果
6.1 招聘与租房数据总体概览
系统首页展示两大模块的核心统计数据,包括招聘岗位总数、热门行业分布、平均薪资水平、租房挂牌总量、主要城区房源占比等关键指标,帮助用户快速掌握整体市场情况。
6.2 用户个人中心功能
提供基础的用户管理界面,支持查看收藏岗位、浏览历史、个性化推荐设置等功能,增强系统的交互体验。
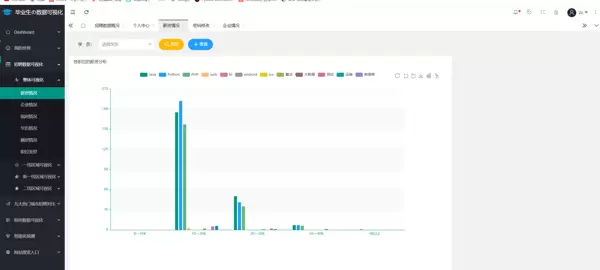
6.3 招聘信息可视化分析
通过柱状图、饼图等形式展示不同城市、行业、经验要求下的岗位数量与薪资分布,揭示就业市场结构性特征。
6.4 城市间招聘信息对比图
采用横向对比图表,直观呈现多个城市在薪资水平、岗位需求量、学历要求等方面的差异,辅助求职者做出合理决策。
6.5 租房市场数据可视化
对房源数据进行地理分布热力图、价格区间饼图、户型占比条形图等多角度展示,反映各区域租金水平与供给状况。
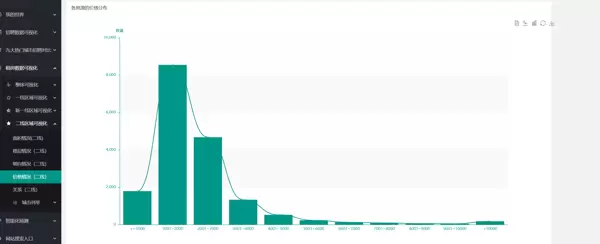
6.6 薪资预测模型
基于历史招聘数据构建简单回归模型,结合岗位类别、工作经验、所在城市等因素,对特定职位的预期薪资进行初步预测,为用户提供参考依据。
通过指定的 URL 发送请求,利用 requests 库结合自定义请求头与请求体来获取网页中的数据信息。
初始页面链接为:
https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=
请求所使用的 headers 包含以下关键字段:
- User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36
- Host:www.lagou.com
- Referer:https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=
- X-Anit-Forge-Code:0
- X-Anit-Forge-Token:None
- X-Requested-With:XMLHttpRequest
该配置主要用于模拟浏览器行为,确保能够成功访问目标接口并获取所需的数据内容。
上述内容为一段浏览器 Cookie 信息,包含多个键值对,用于记录用户会话、行为分析、登录状态及网站追踪等用途。这些数据通常由网站在用户访问时自动设置,以维持登录状态、统计访问来源、定位城市、记录操作行为等功能。
其中涉及的主要字段包括:
- user_trace_token:用户唯一标识,用于跟踪用户行为路径。
- LGUID / LGSID / LGRID:拉勾网系统生成的用户会话与请求标识符。
- login / LG_HAS_LOGIN:标记用户是否已登录。
- JSESSIONID:服务器端会话 ID,用于维持当前用户的会话状态。
- index_location_city:记录用户当前选择的城市,默认为“全国”。
- Hm_lvt_... / Hm_lpvt_...:百度统计相关的时间戳记录,用于统计页面访问频率和停留时间。
- _ga / _gid / _gat:Google Analytics(GA)分析工具使用的用户识别与请求控制参数。
- sensorsdata2015session / sensorsdata2015jssdkcross:神策数据 SDK 所用的会话与跨页面追踪信息。
- X_MIDDLE_TOKEN / X_HTTP_TOKEN:防CSRF攻击或接口鉴权用的令牌。
- SEARCH_ID / TG-TRACK-CODE:搜索行为追踪与流量来源标记。
该 Cookie 内容未包含任何敏感明文信息,但若泄露可能被用于会话劫持等安全风险,因此需通过安全机制保护传输过程(如 HTTPS)。开发或测试过程中应避免直接暴露此类信息。
def get_json(url, num):
"""
发送请求获取拉勾网职位数据的JSON响应
:param url: 请求地址
:param num: 页码
:return: 返回解析后的JSON数据
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Referer': 'https://www.lagou.com/jobs/list_BI%E5%B7%A5%E7%A8%8B%E5%B8%88'
}
url1 = "https://www.lagou.com"
data = {
'first': 'true',
'pn': num,
'kd': 'BI工程师'
}
# 建立会话并获取Cookies
s = requests.Session()
print('建立session:', s, '\n\n')
s.get(url=url1, headers=headers, timeout=3)
cookie = s.cookies
print('获取cookie:', cookie, '\n\n')
# 使用携带Cookie的POST请求获取职位数据
res = requests.post(url, headers=headers, data=data, cookies=cookie, timeout=3)
res.raise_for_status()
res.encoding = 'utf-8'
page_data = res.json()
print('请求响应结果:', page_data, '\n\n')
return page_data
def get_page_num(count):
"""
根据总职位数计算需抓取的页数(拉勾网最多显示30页,每页15条)
:param count: 职位总数
:return: 需要爬取的页数(最多29页)
"""
page_num = math.ceil(count / 15)
if page_num > 29:
return 29
else:
return page_num
def get_page_info(jobs_list):
"""
提取每页中各个职位的关键信息
:param jobs_list: 当前页的所有职位列表
:return: 包含所有职位详细信息的二维列表
"""
page_info_list = []
for i in jobs_list:
job_info = []
job_info.append(i['companyFullName']) # 公司全称
job_info.append(i['companyShortName']) # 公司简称
job_info.append(i['companySize']) # 公司规模
job_info.append(i['financeStage']) # 融资阶段
job_info.append(i['district']) # 所在区域
job_info.append(i['positionName']) # 职位名称
job_info.append(i['workYear']) # 工作经验要求
job_info.append(i['education']) # 学历要求
job_info.append(i['salary']) # 薪资范围
job_info.append(i['positionAdvantage']) # 职位亮点
job_info.append(i['industryField']) # 行业领域
job_info.append(i['firstType']) # 一级分类
job_info.append(",".join(i['companyLabelList']))# 公司标签
job_info.append(i['secondType']) # 二级分类
job_info.append(i['city']) # 城市
page_info_list.append(job_info)
return page_info_list
def unique(old_list):
"""
去除列表中的重复元素,保持原有顺序
:param old_list: 原始列表
:return: 不包含重复项的新列表
"""
newList = []
for x in old_list:
if x not in newList:
newList.append(x)
return newList
def main():
"""
主函数:执行爬虫逻辑,包括获取页数、逐页抓取数据、提取信息并准备入库
"""
# 数据库连接配置
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format("root", "123456", "localhost", "3306", "20_lagou")
engine = create_engine(connect_info)
# 初始请求URL
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# 获取第一页数据以确定总职位数量
first_page = get_json(url, 1)
total_page_count = first_page['content']['positionResult']['totalCount']
# 计算需要请求的页数
num = get_page_num(total_page_count)
# 存储所有职位信息
total_info = []
# 设置请求间隔,避免被封IP
time.sleep(10)
# 循环请求每一页的数据
for page in range(1, num + 1):
# 获取当前页的JSON响应
page_data = get_json(url, page)
# 提取该页的所有职位信息
jobs_list = page_data['content']['positionResult']['result']
df = pd.DataFrame(data=unique(total_info),
columns=['companyFullName', 'companyShortName', 'companySize', 'financeStage',
'district', 'positionName', 'workYear', 'education',
'salary', 'positionAdvantage', 'industryField',
'firstType', 'companyLabelList', 'secondType', 'city'])
# 将去重后的总数据转换为DataFrame,并分别保存至CSV文件与数据库
df.to_csv('bi.csv', index=True)
print('职位信息已保存本地')
df.to_sql(name='demo', con=engine, if_exists='append', index=False)
print('职位信息已保存数据库')
time.sleep(20)
total_info += page_info
print('已经爬取到第{}页,职位总数为{}'.format(num, len(total_info)))
page_info = get_page_info(jobs_list)
4.3 爬取租房房源相关信息
import pymysql
from sqlalchemy import create_engine
import pandas as pd
import random
import time
from fake_useragent import UserAgent
import requests
from pyquery import PyQuery as pq
UA = UserAgent()
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6'
}
lianjia_uuid=6383a9ce-19b9-47af-82fb-e8ec386eb872; UM_distinctid=1777521dc541e1-09601796872657-53e3566-13c680-1777521dc5547a; _smt_uid=601dfc61.4fcfbc4b; _ga=GA1.2.894053512.1612577894; _jzqc=1; _jzqckmp=1; _gid=GA1.2.1480435812.1614959594;
Hm_lvt_9152f8221cb6243a53c83b956842be8a=1614049202,1614959743; csrfSecret=lqKM3_19PiKkYOfJSv6ldr_c; activity_ke_com=undefined; ljisid=6383a9ce-19b9-47af-82fb-e8ec386eb872; select_nation=1; crosSdkDT2019DeviceId=-kkiavn-2dq4ie-j9ekagryvmo7rd3-qjvjm0hxo;
Hm_lpvt_9152f8221cb6243a53c83b956842be8a=1615004691; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221777521e37421a-0e1d8d530671de-53e3566-1296000-1777521e375321%22%2C%22%24device_id%22%3A%221777521e37421a-0e1d8d530671de-53e3566-1296000-1777521e375321%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_referrer_host%22%3A%22www.baidu.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_utm_source%22%3A%22guanwang%22%2C%22%24latest_utm_medium%22%3A%22pinzhuan%22%2C%22%24latest_utm_campaign%22%3A%22wybeijing%22%2C%22%24latest_utm_content%22%3A%22biaotimiaoshu%22%2C%22%24latest_utm_term%22%3A%22biaoti%22%7D%7D; lianjia_ssid=7a179929-0f9a-40a4-9537-d1ddc5164864;
_jzqa=1.3310829580005876700.1612577889.1615003848.1615013370.6; _jzqy=1.1612577889.1615013370.2.jzqsr=baidu|jzqct=%E9%93%BE%E5%AE%B6.jzqsr=baidu; select_city=440300;
srcid=eyJ0Ijoie1wiZGF0YVwiOlwiZjdiNTI1Yjk4YjI3MGNhNjRjMGMzOWZkNDc4NjE4MWJkZjVjNTZiMWYxYTM4ZTJkNzMxN2I0Njc1MDEyY2FiOWMzNTIzZTE1ZjEyZTE3NjlkNTRkMTA2MWExZmIzMWM5YzQ3ZmQxM2M3NTM5YTQ1YzM5OWU0N2IyMmFjM2ZhZmExOGU3ZTc1YWU0NDQ4NTdjY2RiMjEwNTQyMDQzM2JiM2UxZDQwZWQwNzZjMWQ4OTRlMGRkNzdmYjExZDQwZTExNTg5NTFkODIxNWQzMzdmZTA4YmYyOTFhNWQ2OWQ1OWM4ZmFlNjc0OTQzYjA3NDBjNjNlNDYyNTZiOWNhZmM4ZDZlMDdhNzdlMTY1NmM0ZmM4ZGI4ZGNlZjg2OTE2MmU4M2MwYThhNTljMGNkODYxYjliNGYwNGM0NzJhNGM3MmVmZDUwMTJmNmEwZWMwZjBhMzBjNWE2OWFjNzEzMzM4M1wiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCJhYWEyMjhiNVwifSIsInIiOiJodHRwczovL20ubGlhbmppYS5jb20vY2h1enUvc3ovenVmYW5nL3BnJTdCJTdELyIsIm9zIjoid2ViIiwidiI6IjAuMSJ9
class Lianjia_Crawer:
def __init__(self, txt_path):
super(Lianjia_Crawer, self).__init__()
self.file = str(txt_path)
self.df = pd.DataFrame(
columns=['title', 'district', 'area', 'orient', 'floor', 'price', 'city'])
def run(self):
'''启动脚本'''
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(
"root", "123456", "localhost", "3366", "lagou")
engine = create_engine(connect_info)
for i in range(100):
url = "https://sz.lianjia.com/zufang/pg{}/".format(str(i))
self.parse_url(url)
time.sleep(random.randint(2, 5))
print('正在爬取的 url 为 {}'.format(url))
print('爬取完毕!!!!!!!!!!!!!!')
self.df.to_csv(self.file, encoding='utf-8')
print('租房信息已保存至本地')
self.df.to_sql(name='house', con=engine,
if_exists='append', index=False)
print('租房信息已保存数据库')
def parse_url(self, url):
headers['User-Agent'] = UA.chrome
res = requests.get(url, headers=headers)
# 声明pq对象
doc = pq(res.text)
for i in doc('.content__list--item .content__list--item--main'):
try:
pq_i = pq(i)
# 房屋标题
title = pq_i('.content__list--item--title a').text()
# 具体信息
houseinfo = pq_i('.content__list--item--des').text()
# 行政区
address = str(houseinfo).split('/')[0]
district = str(address).split('-')[0]
# 房屋面积
full_area = str(houseinfo).split('/')[1]
area = str(full_area)[:-1]
# 朝向
orient = str(houseinfo).split('/')[2]
# 楼层
floor = str(houseinfo).split('/')[-1]
# 价格
price = pq_i('.content__list--item-price').text()
# 城市
city = '深圳'
data_dict = {'title': title, 'district': district, 'area': area,
'orient': orient, 'floor': floor, 'price': price, 'city': city}
self.df = self.df.append(data_dict, ignore_index=True)
print([title, district, area, orient, floor, price, city])
except Exception as e:
print(e)
print("索引提取失败,请重试!!!!!!!!!!!!!")
if __name__ == "__main__":
txt_path = "test.csv"
Crawer = Lianjia_Crawer(txt_path)
启动爬虫程序,执行 Crawer.run() 方法以开始数据抓取流程。
爬虫运行过程中,系统将自动采集目标网站的相关信息。
采集完成的数据会同时保存至两个位置:一是生成 CSV 格式的文件进行本地存储;二是导入到本地的 MySQL 数据库中,便于后续管理与分析。
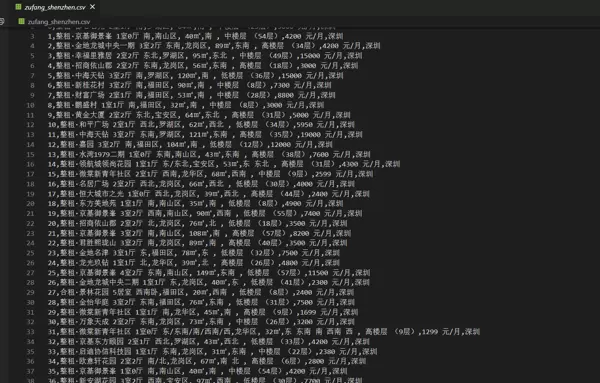
数据库设计方面,共创建三张数据表,分别用于独立存储用户信息、租房信息以及招聘信息,确保数据结构清晰、分类明确。

在连接数据库时,使用如下配置信息建立与 MySQL 的连接:
connect_info = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format("root", "123456", "localhost", "3306","my_db")
engine = create_engine(connect_info)
5 数据可视化实现
本系统采用 ECharts 工具对数据进行可视化展示,通过图形化界面更直观地呈现毕业生相关的招聘与租房信息。
项目前端目录结构设计如下:
其中,“js” 文件夹存放 ECharts 所需的 JavaScript 资源文件,可从 ECharts 官网下载所需版本。主页面 index.html 的部分代码如下所示:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1">
<link href="./assets/images/logo.png" rel="icon">
<title>毕业生の招聘+租房数据可视化系统</title>
<link rel="stylesheet" href="./assets/libs/layui/css/layui.css"/>
<link rel="stylesheet" href="./assets/module/admin.css?v=315"/>
<!--[if lt IE 9]>
<script src="https://oss.maxcdn.com/html5shiv/3.7.3/html5shiv.min.js"></script>
<script src="https://oss.maxcdn.com/respond/1.4.2/respond.min.js"></script>
<![endif]-->
</head>
<body class="layui-layout-body">
<div class="layui-layout layui-layout-admin">
<!-- 头部 -->
<div class="layui-header">
<div class="layui-logo">
<img src="./assets/images/logo.png"/>
<cite> 毕业生の数据可视化</cite>
</div>
<ul class="layui-nav layui-layout-left">
<li class="layui-nav-item" lay-unselect>
<a ew-event="flexible" title="侧边伸缩"><i class="layui-icon layui-icon-shrink-right"></i></a>
</li>
<li class="layui-nav-item" lay-unselect>
<a ew-event="refresh" title="刷新"><i class="layui-icon layui-icon-refresh-3"></i></a>
</li>
</ul>
<ul class="layui-nav layui-layout-right">
<li class="layui-nav-item" lay-unselect>
<a ew-event="message" title="消息">
<i class="layui-icon layui-icon-notice"></i>
<span class="layui-badge-dot"></span>
</a>
</li>
 zz
zz
6 实现效果
6.5 租房数据可视化
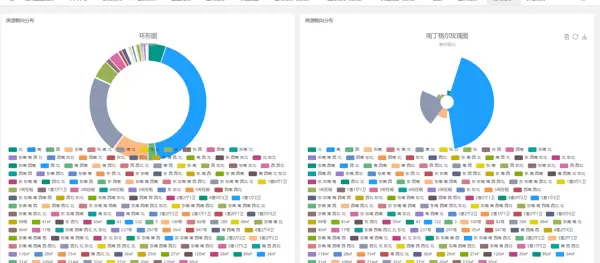
6.6 薪资预测
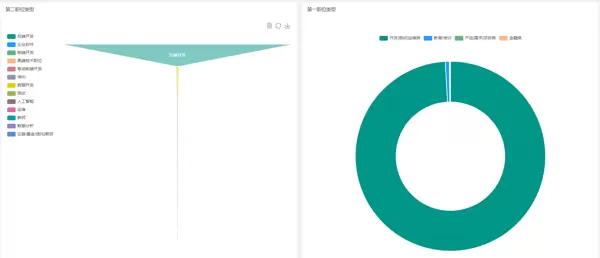
6.3 招聘信息可视化
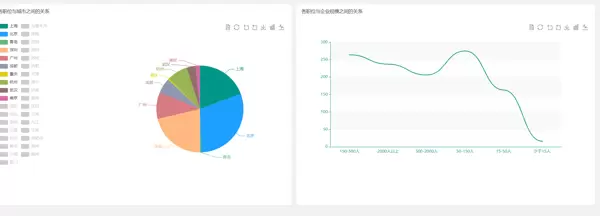

6.4 招聘信息城市之间对比图
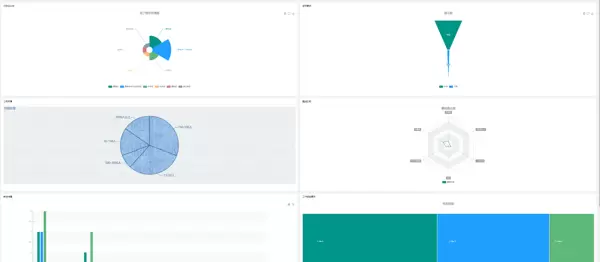
6.1 招聘数据和租房数据概况
支持根据学习背景与职位类型进行筛选和查询操作。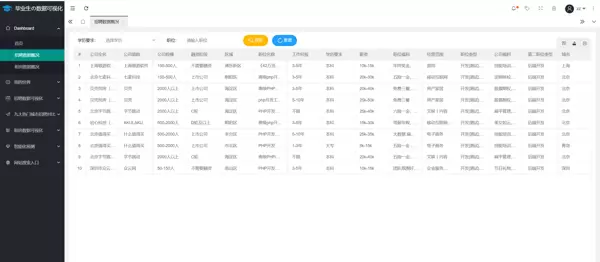
6.2 个人中心
用户可在此页面更新个人基本资料及密码信息。

 京公网安备 11010802022788号
京公网安备 11010802022788号







