


 雷达卡
雷达卡



2025年12月4日,Nvidia正式发布了CUDA 13.1版本。据官方介绍,这是自CUDA平台诞生二十年以来最为全面且规模最大的一次更新[1]。此次发布不仅带来了核心功能的升级,还配套推出了一份全新的面向开发者的CUDA编程指南[2]。
本文基于上述两项资料,对CUDA的基本原理及其最新版本的核心变化进行梳理与总结。
理解CUDA:并行计算的核心平台
CUDA是Nvidia构建的一套并行计算生态系统,其设计初衷是让开发者能够利用Nvidia GPU执行通用计算任务,而不仅限于传统的图形渲染处理。
作为一个完整的开发平台,CUDA涵盖了从底层硬件交互到高层优化支持的全链条能力:
- 工具链支持:包括NVCC编译器、Nsight系列调试与性能分析工具等
- 高性能库集成:如用于线性代数运算的cuBLAS、深度学习加速的cuDNN、稀疏矩阵操作的cuSPARSE等
- 运行时管理机制:负责GPU资源调度、内存分配以及任务执行控制
要深入掌握CUDA的工作方式,首先需要了解GPU在架构层面与CPU的本质差异。
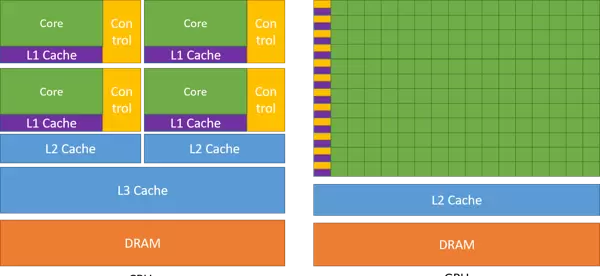
GPU与CPU的设计哲学差异
CPU专注于快速执行串行任务,擅长处理复杂的逻辑流程,并能并发运行几十个线程;而GPU则以大规模并行为目标,可同时调度成千上万个线程,通过牺牲单线程效率来换取整体吞吐量的最大化。
这种设计体现在硬件布局上:GPU将更多晶体管用于数据处理单元,以增强并行计算能力;相比之下,CPU则将大量晶体管用于缓存和流程控制单元,以提升单线程响应速度。
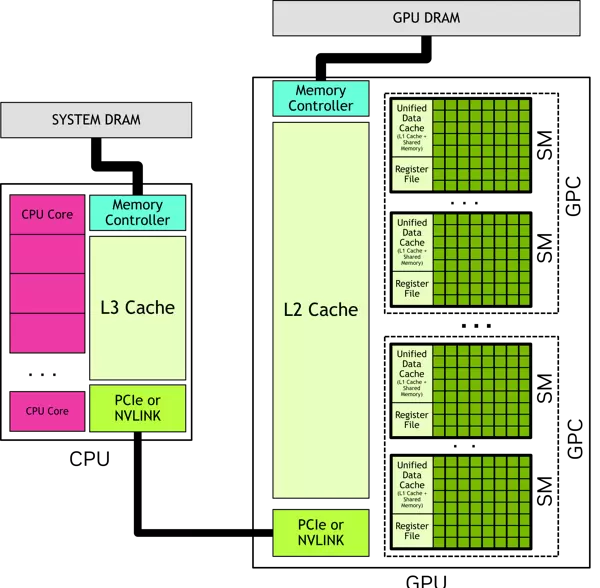
CUDA编程模型解析
CUDA采用异构计算模型,将计算任务划分为由CPU和GPU协同完成的部分。其中,CPU主导程序的控制流和串行逻辑,GPU则承担高密度并行计算任务。
运行在主机端(CPU)的代码可通过CUDA API实现以下操作:
- 在主机内存与GPU设备内存之间传输数据
- 启动GPU上的内核函数执行
- 同步等待数据传输或计算完成
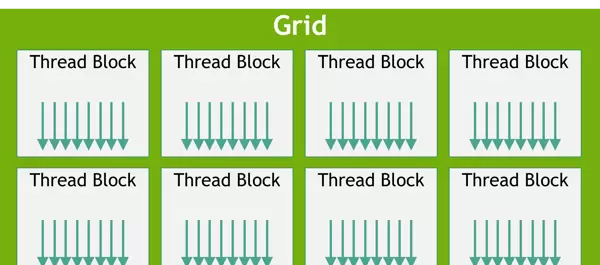
三层线程组织结构
CUDA使用层次化的线程结构来组织并行任务:
- 线程(Thread):最小的执行单位
- 线程块(Block):一组线程的集合,块内线程可共享内存并进行同步
- 网格(Grid):包含所有线程块的整体结构,对应一次内核调用的完整并行任务
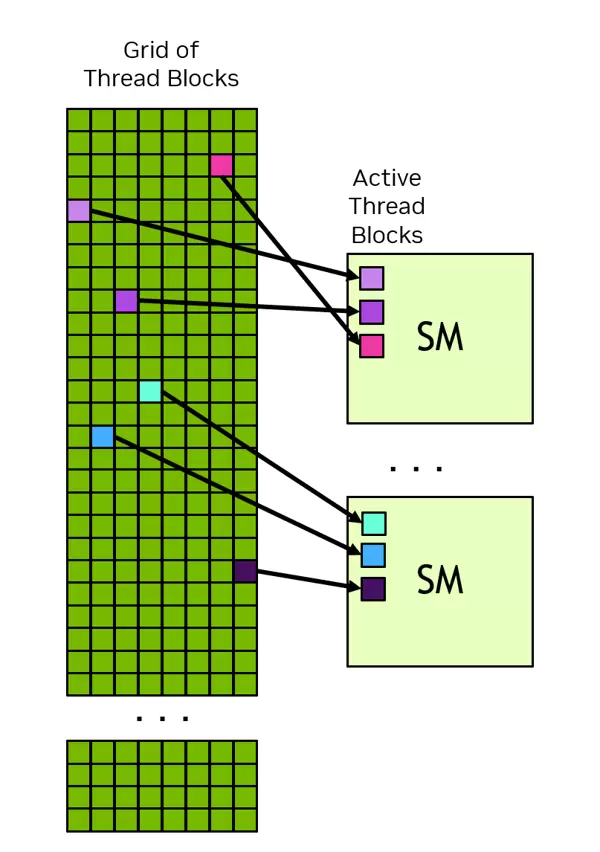
实际运行时,通常会有数百万个线程被组织成多个线程块,再进一步构成一个网格。网格中的所有线程块具有相同的尺寸规格。
每个线程块会被调度至一个流式多处理器(SM)中执行。这样的设计使得同一块内的线程可以高效地共享片上高速内存,并实现低延迟的通信与同步。
不同线程块则分布在可用的多个SM之间,彼此独立运行,执行顺序不固定。
线程集群(Clusters):更高层级的协作机制
对于计算能力(compute capability)达到9.0及以上的GPU,CUDA引入了“线程集群”这一可选的组织层级。
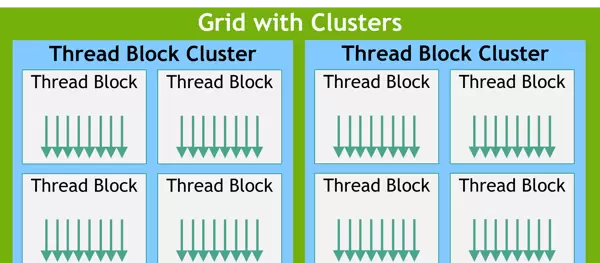
线程集群允许多个线程块在硬件层面被捆绑执行,共享片上内存资源,并支持跨块的通信与同步操作。这一特性有效解决了传统模型中线程块之间无法直接交互的问题,提升了复杂并行算法的实现灵活性。
线程束(Warp)与SIMT执行模式
在线程块内部,硬件会自动将线程按每组32个划分为“线程束”(warp),这是GPU调度和执行的基本单位。
线程束采用单指令多线程(SIMT)模式运行:所有32个线程在同一周期执行相同指令,但各自处理不同的数据。
当线程束中的线程因条件判断进入不同的分支路径(如if/else)时,硬件必须分阶段执行各分支,其余线程在此期间被屏蔽——这种情况称为“线程束发散”,会导致显著的性能下降。
如下图所示,在发生分支时:
- 先执行偶数索引线程,奇数线程被屏蔽
- 再执行奇数索引线程,偶数线程被屏蔽
因此,为了最大化GPU利用率,应尽量保证同一个线程束内的线程遵循一致的执行路径。

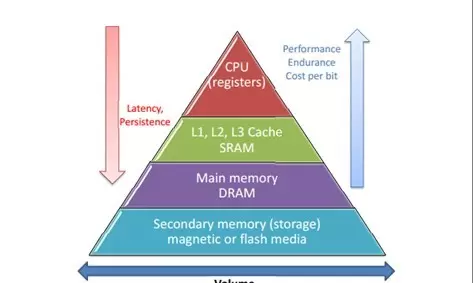
GPU内存体系结构
相较于CPU,GPU拥有更为复杂的内存层级结构。根据访问速度和物理位置,主要可分为三类:
- 片上内存(On-Chip):访问速度最快,容量有限,如寄存器和共享内存
- 片外内存(Off-Chip):访问较慢但容量大,如全局内存
- 专用缓存:如常量缓存、纹理缓存等,性能介于前两者之间
寄存器(Registers)
寄存器是GPU上最快的存储资源,每个线程独享一组寄存器空间,主要用于存放局部变量。其访问延迟为单周期,几乎无开销。
然而,寄存器总量受限。若单个线程占用过多寄存器,将减少同一SM上可并发运行的线程数量,从而降低占用率(occupancy),影响整体性能。
本地内存(Local Memory)
当线程所需的寄存器超过硬件限制时,溢出的数据会被移至本地内存。尽管名为“本地”,其实质属于全局内存的一部分,位于片外DRAM中,因此访问速度远慢于寄存器。
全局内存(Global Memory)
全局内存是GPU中容量最大、用途最广的内存区域,所有线程均可对其进行读写操作。但由于其位于片外,访问延迟较高。
其性能表现高度依赖于内存访问模式,尤其是是否满足内存合并(memory coalescing)的要求——即相邻线程应尽可能访问连续的内存地址,以提高带宽利用率。
在 GPU 编程中,全局内存的访问模式对内核性能具有决定性影响。当一个 warp 中的 32 个线程以连续地址进行内存访问时,硬件能够将这些访问合并为一次大容量读写操作,从而实现极高的访问效率。
反之,若线程访问的地址分布不连续或跨度较大,则该访问会被拆分为多次独立的内存事务,导致显著的性能下降。
共享内存(Shared Memory)
共享内存位于芯片上的 SRAM 中,其访问速度接近寄存器级别,但容量远小于全局内存。它被同一个线程块内的所有线程共享,适用于需要频繁数据交换或重复访问相同数据的计算场景。
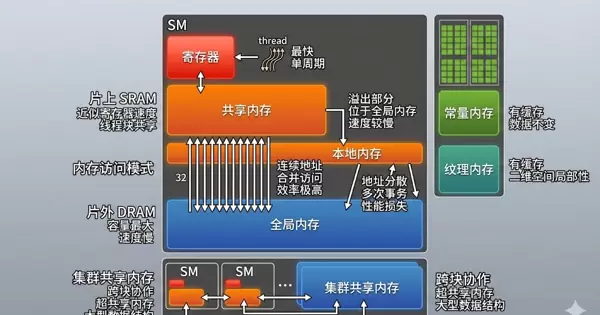
常量内存(Constant Memory)
常量内存位于片外,但配备了专用的缓存机制——常量缓存(constant cache),因此对于在内核执行期间保持不变的数据而言,访问效率较高。这类内存适合存储如权重、参数表等只读数据。
纹理内存(Texture Memory)
同样部署于片外,纹理内存配有独立的纹理缓存(texture cache),特别适用于具备二维空间局部性的访问模式,例如图像处理和网格计算等应用中表现优异。
集群共享内存(Cluster Shared Memory)
在支持线程集群架构的 GPU 上,多个线程块可将其各自的共享内存资源整合为一个更大的分布式共享内存(Distributed Shared Memory),也称为“超共享内存”。
这种机制适用于跨线程块协作的大规模并行任务,典型应用场景包括:
- 超大 tile 的矩阵运算
- 多块联合执行的并行算法
- 跨 block 的生产者-消费者数据流模型
该特性显著增强了 GPU 在处理大规模并行算法时的数据协同与共享能力。
CUDA 13.1 新特性概览
基于上述内存模型的理解,接下来介绍 CUDA 13.1 版本带来的关键更新内容。
CUDA Tile:提升编程抽象层级
CUDA Tile 是本次版本中最核心的新增功能,引入了一种基于 Tile 的编程范式,旨在提高代码的抽象程度与跨平台可移植性。
开发者可通过编写高层级的 GPU Tile 内核(Tile kernels),无需深入管理 Tensor Core 等底层专用硬件细节。
该功能包含两个主要组件:
- CUDA Tile IR:一种全新的虚拟指令集架构(ISA),用于描述 Tile 级别的操作,类似于 SIMT 模型中的 PTX(Parallel Thread Execution)中间表示。
- cuTile Python DSL:一种专为数组与 Tile 运算设计的领域特定语言(DSL),允许开发者直接使用 Python 编写高性能内核逻辑。
这一改进大幅降低了开发门槛,使 Python 成为 CUDA 开发的新选择。
需要注意的是,CUDA Tile 当前仅限于 NVIDIA Blackwell 架构(计算能力 10.x 和 12.x)设备支持,其他型号暂未兼容。
开发者工具与库的增强
CUDA 13.1 在核心库和工具链方面也进行了多项性能优化与功能扩展:
cuBLAS:新增实验性 API,支持 Blackwell GPU 上的 Grouped GEMM(分组通用矩阵乘法),同时加强了对 FP8 和 BF16 等低精度数据类型的支持,有助于加速 AI 推理与训练工作负载。
cuSPARSE:推出了新的稀疏矩阵向量乘法接口 SpMVOp,相比旧有的 CsrMV 实现,在多种稀疏结构下展现出更优的运行效率。
cuFFT:新增可在 C++ 头文件中查询或生成设备功能代码及数据库元数据的 API,专为 cuFFTDx 库服务。通过调用 cuFFT 查询接口,可自动生成可链接至 cuFFTDx 应用程序的高效代码块,进一步提升 FFT 计算性能。
CCCL 3.1 (CUB):新增两种浮点运算确定性选项,帮助开发者在结果可重现性与执行性能之间灵活权衡。
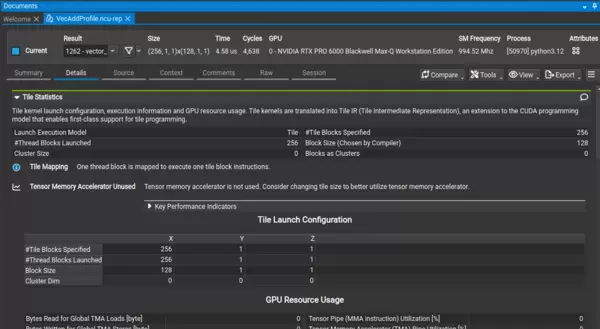
Nsight Compute:针对 Tile 内核提供了更强的性能分析支持,新增“Tile 统计(Tile Statistics)”面板,便于深入洞察 Tile 级别的资源使用情况。
MPS 增强(多进程服务):引入 Static SM Partitioning(静态流式多处理器分区)功能。在多用户或多任务共用 GPU 的环境中(如云计算平台),该功能可实现计算资源的隔离,确保各任务获得稳定的 SM 资源配额,避免相互干扰,提升服务质量。
运行时与编译器更新
本版本还对底层系统机制进行了优化,以增强稳定性与执行效率:
Green Context(轻量上下文)支持:运行时现已支持轻量级 GPU 上下文管理。开发者可以定义和控制不同的 GPU 资源分区,实现更精细化的资源配置与调度。
内存局部性优化分区:新增内存优化机制,通过组织数据布局使线程访问的数据尽可能靠近本地存储单元,减少对慢速全局内存的依赖,从而缩短延迟,提升整体吞吐。
编译器优化:NVIDIA Compute Sanitizer 新增对 NVCC 编译时修补(Compile-time Patching)的支持,不仅强化了内存错误检测能力,还提升了编译阶段的整体性能表现。
NVIDIA CUDA 13.1 的发布标志着 GPU 编程进入了一个全新的发展阶段。这一版本引入了多项关键更新,显著提升了开发效率与运行性能,尤其在并行计算和内存管理方面实现了重要突破。
其中,CUDA Tile 技术的进一步优化成为本次升级的核心亮点之一。该技术通过更高效的线程块调度机制,增强了数据局部性与计算密度,使得开发者能够更加便捷地实现高性能内核函数设计。无论是深度学习训练、科学计算还是大规模模拟任务,都能从中获得明显的加速效果。
CUDA 编程模型建立在分层内存架构的基础之上,这种结构从全局内存到共享内存、寄存器,逐级提升访问速度。合理利用这一层级体系,是实现高效 GPU 程序的关键所在。例如,将频繁访问的数据放置于共享内存中,可大幅减少延迟,提高吞吐量。
随着对异构计算需求的增长,NVIDIA 不断完善其软件栈支持。CUDA 13.1 在工具链层面也进行了增强,包括编译器优化、调试能力改进以及对新硬件特性的适配,为开发者提供了更稳定的编程环境。
此外,cuTile Python 接口的推出,使得 Python 开发者也能以更简洁的方式使用 Tile 编程范式。这一接口封装了底层复杂性,允许用户通过高级语法表达高性能计算逻辑,从而降低 GPU 编程门槛,拓展应用场景。
总体来看,NVIDIA 通过持续迭代 CUDA 平台,不仅强化了现有功能,还积极引入创新编程模型,推动 GPU 计算向更高层次发展。未来,随着更多领域对算力需求的激增,这类技术进步将在实际应用中发挥越来越重要的作用。

 京公网安备 11010802022788号
京公网安备 11010802022788号







