




 雷达卡
雷达卡
















一、Nutch
简介:Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
尽管Web搜索是漫游Internet的基本要求, 但是现有web搜索引擎的数目却在下降. 并且这很有可能进一步演变成为一个公司垄断了几乎所有的web搜索为其谋取商业利益.这显然 不利于广大Internet用户.
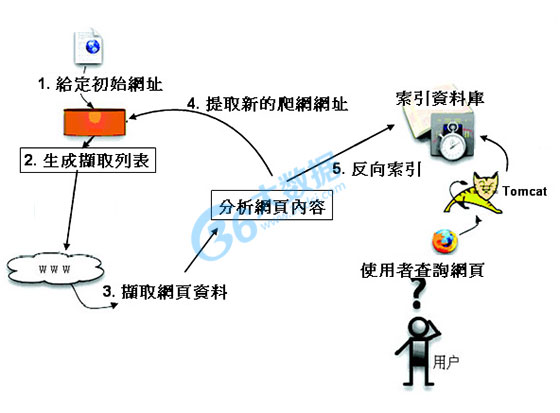
Nutch为我们提供了这样一个不同的选择. 相对于那些商用的搜索引擎, Nutch作为开放源代码 搜索引擎将会更加透明, 从而更值得大家信赖. 现在所有主要的搜索引擎都采用私有的排序算法, 而不会解释为什么一个网页会排在一个特定的位置. 除此之外, 有的搜索引擎依照网站所付的 费用, 而不是根据它们本身的价值进行排序. 与它们不同, Nucth没有什么需要隐瞒, 也没有 动机去扭曲搜索的结果. Nutch将尽自己最大的努力为用户提供最好的搜索结果.
Nutch目前最新的版本为version v2.2.1。
二、Lucene
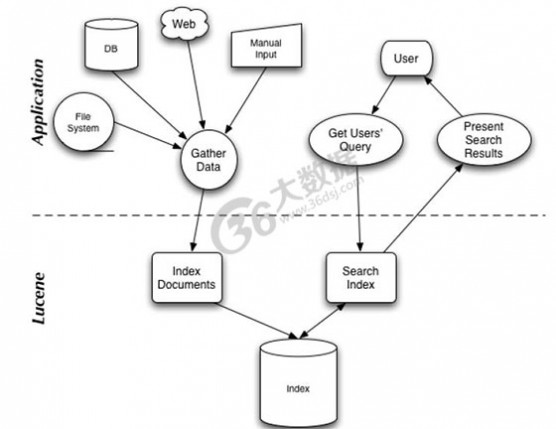
简介:Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
三、SolrCloud
简介:SolrCloud是Solr4.0版本以后基于Solr和Zookeeper的分布式搜索方案。SolrCloud是Solr的基于Zookeeper一种部署方式。Solr可以以多种方式部署,例如单机方式,多机Master-Slaver方式。
原理图:
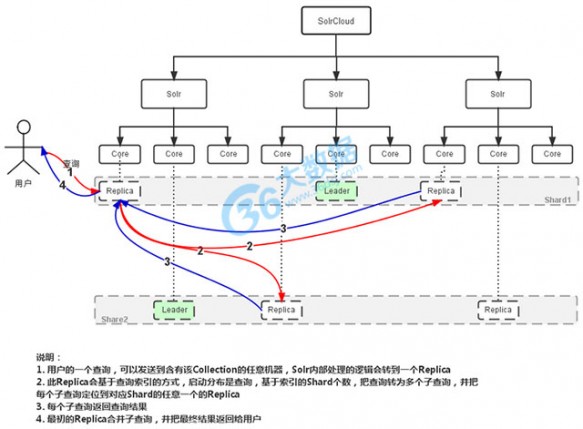
SolrCloud有几个特色功能:
集中式的配置信息使用ZK进行集中配置。启动时可以指定把Solr的相关配置文件上传
Zookeeper,多机器共用。这些ZK中的配置不会再拿到本地缓存,Solr直接读取ZK中的配置信息。配置文件的变动,所有机器都可以感知到。另外,Solr的一些任务也是通过ZK作为媒介发布的。目的是为了容错。接收到任务,但在执行任务时崩溃的机器,在重启后,或者集群选出候选者时,可以再次执行这个未完成的任务。
自动容错SolrCloud对索引分片,并对每个分片创建多个Replication。每个Replication都可以对外提供服务。一个Replication挂掉不会影响索引服务。更强大的是,它还能自动的在其它机器上帮你把失败机器上的索引Replication重建并投入使用。
近实时搜索立即推送式的replication(也支持慢推送)。可以在秒内检索到新加入索引。
查询时自动负载均衡SolrCloud索引的多个Replication可以分布在多台机器上,均衡查询压力。如果查询压力大,可以通过扩展机器,增加Replication来减缓。
自动分发的索引和索引分片发送文档到任何节点,它都会转发到正确节点。
事务日志事务日志确保更新无丢失,即使文档没有索引到磁盘。
四、Solr
简介:Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。

Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
五、ElasticSearch
简介:ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二最流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
六、Sphinx
简介:Sphinx是一个基于SQL的全文检索引擎,可以结合MySQL,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。Sphinx特别为一些脚本语言设计搜索API接口,如PHP,Python,Perl,Ruby等,同时为MySQL也设计了一个存储引擎插件。
Sphinx单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需 3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
七、SenseiDB
简介:SenseiDB是一个NoSQL数据库,它专注于高更新率以及复杂半结构化搜索查询。熟悉Lucene和Solor的用户会发现,SenseiDB背后有许多似曾相识的概念。SenseiDB部署在多节点集群中,其中每个节点可以包括N块数据片。Apache Zookeeper用于管理节点,它能够保持现有配置,并可以将任意改动(如拓扑修改)传输到整个节点群中。SenseiDB集群还需要一种模式用于定义将要使用的数据模型。
从SenseiDB集群中获取数据的唯一方法是通过Gateways(它 没有“INSERT”方法)。每个集群都连接到一个单一gateway。你需要了解很重要的一点是,由于SenseiDB本身没法处理原子性 (Atomicity)和隔离性(Isolation),因此只能通过外部在gateway层进行限制。另外,gateway必须确保数据流按照预期的方 式运作。内置的gateway有以下几种形式:
- 来自文件
- 来自JMS队列
- 通过JDBC
- 来自Apache Kafka
- (来自小象学院)
 的时候,雨也是晴;心雨
的时候,雨也是晴;心雨 的时候,晴也是雨!
的时候,晴也是雨!

 京公网安备 11010802022788号
京公网安备 11010802022788号







