



 雷达卡
雷达卡
















当经济学家还陶醉于 “经济学帝国主义”,沉迷在 “无计量不学术” 之时,一个真正的学术明星,正以几乎横扫一切学科与业界之势冉冉升起,犹如明日之太阳,光芒不可限量。这个学术明星就是“机器学习”(Machine Learning,简记ML)。
当计量经济学的影响力几乎不出校门时,机器学习正迅速进入大众视野,并悄然改变着我们的日常生活(比如,网络搜索、网购等背后均有机器学习的算法支持)。你或许感到奇怪,计量经济学与机器学习有可比性吗?当然有!
机器学习也称 “统计学习”(Statistical Learning),由此可知主要使用统计方法;而计量经济学也大量使用统计学方法。机器学习的从业者被高大上地称为 “数据科学家”(data scientist);而计量经济学家与实证研究者每天也与数据打交道,怎么我们就不是数据科学家?为何一母(统计学)生两子(计量经济学、机器学习),二者的境遇如此不同?要回答这个问题,首先要知道什么是机器学习。
事实上,不同的学科对于机器学习有着不同的理解。如果你去哈佛经济系听 ML 的课,你会发现主要讲 ML 的思想与应用。如果你去波士顿大学数学统计系上 ML 的课,则几乎全是数学,包括泛函分析(functional analysis),甚至Reproducing Kernel Hilbert Space……而如果你观看听斯坦福计算机教授、百度首席科学家吴恩达(Andrew Ng)的 ML 公开课,则主要介绍各种算法(algorithm),甚至连线性回归的 OLS 问题也要用 “梯度下降法”(Gradient Descent)进行求解。
Hard Coding vs. Learning
那么,究竟什么是机器学习?的理解方法是从一个例子开始。机器学习的一个早期成功案例是过虑垃圾邮件(spam filtering)。随着电子邮件的兴起,垃圾邮件也越来越多。如何自动地过虑掉垃圾邮件(spam),而不错杀正常邮件?
一种传统方法是人为制定一个判定垃圾邮件的规则(比如,某些词汇在垃圾邮件中出现频率更高),将此规则进行计算机编程,然后用于新收到的邮件。这种方法被形象地称为 “hard coding”,因为它让计算机遵循人类预先制定的死规则进行邮件分类。但 hard coding 方法的实践效果并不好,因为人类虽能直观判断何为垃圾邮件,但很难将其准确提炼为可操作的规则(邮件中可能出现的词汇何其多啊)。
一个突破性的想法是引入“学习”(Learning),即不由人类告诉计算机何为垃圾邮件,而让计算机通过学习大量的数据自行判断何为垃圾邮件。具体来说,给予计算机大量的邮件,其中每封邮件都事先由人类识别并标注为 “正常邮件” 或 “垃圾邮件”。根据海量邮件的大数据(big data),计算机可以统计出不同词汇在正常邮件或垃圾邮件的出现频率。
比如,假设垃圾邮件经常出现 “代开发票” 一词,则一封包含 “代开发票” 的邮件就更可能是垃圾邮件。更地,根据贝叶斯规则(Bayes rule)可算出,给定包含 “代开发票” 一词,该邮件为垃圾邮件的条件概率。
当然,一封邮件通常包含很多词汇,故需用数学方法将这些信息综合起来,最终算出此邮件为 spam 的概率。最后,如果此概率超过某临界值(比如 0.9),则归类为垃圾邮件。这种方法称为 “Bayes spam filtering”,在实践中取得巨大成功。
从此例可见,计算机判断垃圾邮件的能力正是通过学习大量数据而获得,故名 “机器学习”(Machine Learning)。而上述 “Bayes spam filtering” 即为一种 “学习机器”(learning machine)或 “学习器”(learner)。
大数据与机器学习
不难看出,机器学习的效果依赖于大数据。数据量越大,则学习的效果越好。而且,机器学习的能力还可以根据的数据不断地动态更新。反之,如果只给计算机提供100封邮件(小数据),可以想象机器学习的效果会很差。
事实上,有些机器学习的算法出现得很早,比如 “人工神经网络”(artificial neural network)早在60年代就提出了,但当时既无大数据,也无高速计算机,故生不逢时停滞不前,直至近年来才复兴,成为炙手可热的 “深度学习”(deep learning)。
由于样本数据主要用于训练计算机获得学习能力,故一般称为 “训练数据”(training data)。事实上,在进行机器学习时,通常将所有数据分为两类,其中大部分数据构成“训练数据”,而少量数据则作为 “测试数据”(test data)或 “保留数据”(hold-out data)。测试数据仅用于检验机器学习的效果(相当于out-of-sample test),以避免出现 “过拟合”(overfit),即样本内拟合效果虽好,但外推预测效果差的情形。
机器学习的术语
当计量经济学家或实证研究者进入机器学习领域,难免感觉这个领域既熟悉又陌生,或许 “恍如隔世”。比如,这里也有线性回归(OLS)与逻辑回归(Logit),以及作为非参数估计的 K 近邻法(K Nearest Neighbors)等等。但似乎这一切又是用不同的术语包装起来的。
比如,计量经济学称
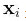 为 “自变量” 或 “解释变量”,但机器学习则称为 “表征” 或 “特征”(features)。计量经济学称
为 “自变量” 或 “解释变量”,但机器学习则称为 “表征” 或 “特征”(features)。计量经济学称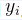 为 “因变量” 或 “被解释变量”,而机器学习则称为“响应”(response)。计量经济学称第
为 “因变量” 或 “被解释变量”,而机器学习则称为“响应”(response)。计量经济学称第 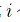 个数据为 “观测值”(observation),而机器学习则直接称为 “案例”(example)。
个数据为 “观测值”(observation),而机器学习则直接称为 “案例”(example)。不得不承认,机器学习的有些术语比较接地气(别人家的术语?)。显然,作为强势学科,机器学习的术语有望日益流行。
机器学习的分类
大致来说,机器学习可分为两大类,即 “监督学习”(supervised learning)与 “无监督学习”(unsupervised learning)。
所谓 “监督学习”,其实就是有目标的学习;而“无监督学习”自然就是无目标的学习。具体来说,对于监督学习,数据可以写为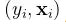 ,而我们的任务是用 来预测。
,而我们的任务是用 来预测。
比如,在上述过虑垃圾邮件的例子中,不同词汇在一封邮件中出现的频率,而则为虚拟变量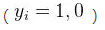 ,表示此封邮件是否为垃圾邮件。在监督学习中,由于目标很明确,就是预测,故起着监督与指导学习过程的作用,故名 “监督学习”。
,表示此封邮件是否为垃圾邮件。在监督学习中,由于目标很明确,就是预测,故起着监督与指导学习过程的作用,故名 “监督学习”。
反之,对于无监督学习,数据只是,并没有明确的,而学习过程就是为了识别的某种模式(pattern recognition)或规律。常见的无监督学习方法包括 “主成分分析”(principal component analysis)与 “聚类分析”(cluster analysis)等。
对于监督学习,还可以根据的性质进一步细分。如果为连续变量,则称为 “回归”(regression)。反之,如果为离散变量(比如,虚拟变量),则称为 “分类”(classification)。
学习理论(Learning Theory)
大多数的机器学习问题都是监督学习,因为许多问题都可纳入到此框架中。
比如,人脸识别(facial recognition)。首先,可将传感器捕捉到的人脸相片转换为像素(pixel)的矩阵,其中每个像素用一个数字表示其灰度(grayscale,假设为黑白相片)。

其次,将此矩阵的每列依次叠放,构成一个很长的列向量。例如,假设此相片的像素为 100 x 100,则表征向量(feature vector)的维度为 10,000 维(高维数据!)。
机器学习的任务就是要判断这个图像是否为人脸
,或是否为某人的脸。显然,使用 hard coding 的方法将行不通,因为虽然我们见到人脸就能马上识别,但却无法告诉计算机究竟怎样的图像才算人脸。据说,早期的计算机专家曾天真地以为人脸识别只是简单的计算机视觉(computer vision)问题,可以在一个暑期就完成(summer project)。事实上,不仅人脸难以识别,即使简单如 0 - 9 的手写数字,如果使用 hard coding 的方法,计算机也力不从心(比如,邮局为了自动分拣而需要识别手写邮编)。这是因为,不同人的手写数字千差万别,你甚至很难告诉计算机,究竟数字 “4” 应该长什么样(参见下图)。当然,对于这些数字,同样可以将其像素转化为表征向量。

真正的突破依然来自于 Machine Learning 的方法,即给予计算机大量的图像,某些包含人脸,而有些不含人脸,让计算机通过学习大量的数据而获得识别人脸的能力。
在数学上,给定一个未知函数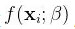 ,机器学习的目标就是通过训练数据
,机器学习的目标就是通过训练数据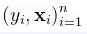 来学习此未知函数其中
来学习此未知函数其中 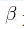 为可能的未知参数。
为可能的未知参数。
具体来说,希望根据训练数据找到一个函数
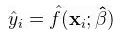
使得所作的预测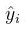 与实际的
与实际的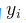 之间的差距最小,比如最小化在测试数据(test data)中的均方误差(Mean Square Errors):
之间的差距最小,比如最小化在测试数据(test data)中的均方误差(Mean Square Errors):
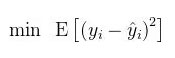
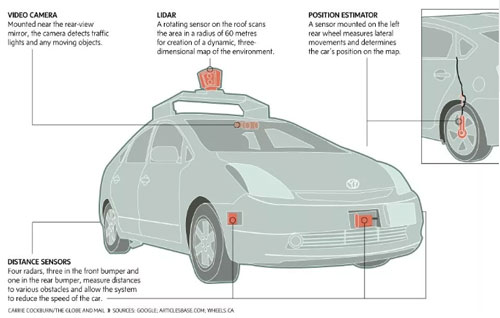
又比如, “无人驾驶汽车”(driverless cars)也可纳入此一般的机器学习框架。此时,表征向量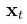 由汽车上各种传感器在时刻
由汽车上各种传感器在时刻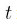 实时输送的各项指标数据所构成(参见下图),而
实时输送的各项指标数据所构成(参见下图),而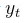 为是否在时刻刹车
为是否在时刻刹车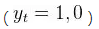 。比如,如果预测
。比如,如果预测 ,则刹车;反之,则不刹车。
,则刹车;反之,则不刹车。
(未完待续,更多精彩,下期推送)
高级计量经济学与Stata现场班(含机器学习与高维回归,北京,十一)
本文为山东大学陈强教授原创,摘自陈强老师微信公众号“econometrics-stata”,转载请注明作者与出处。



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 变色卡
变色卡 抢沙发
抢沙发 千斤顶
千斤顶 显身卡
显身卡





 京公网安备 11010802022788号
京公网安备 11010802022788号







