相关日志
-
-
分享
1章:数据库概念(5)
-
芐雨 2014-8-21 16:52
-
数据与表现分离 数据应独立于演示;你******。例如:当你收到一个公司的财务数据,你不认为这财务数据的来源是真实的,这只是一个演示的数据。它可以在图表或其它网站的方式呈现给你,但这样的演示是不真实的。
-
个人分类: excel商业智能|0 个评论
-
-
分享
1章:数据库概念(4)
-
芐雨 2014-8-21 16:29
-
灵活的分析 excel最吸引人的一个特点就是它的灵活性。单元格可以是文本,数字,公式,或其它自定义的格式。实际上,这也构成了excel作为数据分析的一种有效工具。你可以使用命名区域,公式,和宏来创建一个复杂的运算,加上单元格,摘要等,共同创造一个最终的分析。 问题是,灵活度太大,也不利于建立一个统一的表格标准。常常会出现,拿到别人的excel表格,没办法理清其中的公式,宏等运算关系。数据库跟Excel相比,就显得更加 刚性的,严格的,规则。 然而 ,适量的 刚度是 有 好处 。 在数据库中,你可以更容易地明白查询或存储过程。如数据集的建立,编辑,或受影响的分析过程,你都可以很容易地在查询语法或代码中看到。事实上,在关系数据库,你永远也不会遇到隐藏公式,隐藏单元格或自定义区域等。
-
个人分类: excel商业智能|0 个评论
-
-
分享
1章:数据库概念(3)
-
芐雨 2014-8-19 10:46
-
可扩展性 可扩展性是一个应用开发是否灵活地满足增长和复杂性的要求的能力。在Excel中,可扩展性主要是指Excel的能力来处理不断增加的大量的数据。大多数的Excel迷们很快指出:Excel 2007后,单一的Excel工作表处理行数达到了1048576行。这是从65536行的限制,巨大的增长。然而,仅仅增加容量并不能解决所有的可扩展性问题。 想象一下,你在一个小公司工作,用Excel来分析你的日常事务。随着时间的推移,你建立了一个强大的报表,利用公式,数据透视表,还有VBA。 当你的数据不断的增长,你会开始注意到性能问题。您的电子表格加载得非常缓慢,计算也非常缓慢。这是为什么呢?这是Excel处理内存的方式。当一个Excel文件被加载时,整个文件会加载到RAM中,这使得Excel能快速的数据处理和存取。但这种行为方式的缺点是,当你的电子表格有新的变化,都会影响RAM中的整个电子表格。一个大的电子表格需要大量的RAM,即使是最小的变化过程。最终,你的巨大的工作表的每一个动作将导致痛苦的等待。 使用数据透视表,将需要更大的缓存(内存容器),这样工作簿的大小几盘翻了一翻。最终,你的工作簿奖变得太大并且不易分配。你甚至需要考虑拆分成更小的工作簿(分地区)。这使你的工作又重复了。 有时候,你的工作表数据会超出1048576行。那接着会怎么样?你要重新建立一个新工作表?你怎样分析两个不同的工作表的数据?公式还能用吗?VBA要重新写吗? 这些都是需要解决的问题? 当然,你可能会找到各种巧妙的方法来避开这些限制。虽然这都是变通的方法。最终你使数据变得“适合”excel,你会认为excel是足够灵活的,你可以让大部分的事情“适合"excel就行了。但这会让excel限制了你。 关系数据库(如Access或SQL Server)是一个不错的选择。大部分的数据库并没有限制行而且数据量对性能影响不大。这就使你可以先处理或准备大数据集,以后才放到Excel中处理。同时,它的升级和扩展在一个关系型数据库中也是比较容易的。
-
个人分类: excel商业智能|0 个评论
-
-
分享
三个流行MySQL分支
-
Lisrelchen 2014-8-4 21:52
-
导读:尽管MySQL是最受欢迎的程序之一,但是许多开发人员认为有必要将其拆分成其他项目,并且每个分支项目都有自己的专长。该需求以及Oracle对核心产品增长缓慢的担忧,导致出现了许多开发人员感兴趣的子项目和分支。本文将讨论受人们关注的三个流行MySQL分支:Drizzle、MariaDB和Percona Server(包括XtraDB引擎)。文中简要介绍每个分支出现的原因及其目标,以及是否可在您自己的生产环境中使用它们。 文章内容如下: 简介 MySQL是历史上最受欢迎的免费开源程序之一。它是成千上万个网站的数据库骨干,并且可以将它(和Linux)作为过去10年里Internet呈指数级增长的一个有力证明。 那么,如果MySQL真的这么重要,为什么还会出现越来越多的核心MySQ产品的高端衍生产品?这是因为MySQL是免费的开源应用程序,所以开发人员总是可以获得其代码,并按照自己的想法修改代码,然后再自行分发代码。在很长的一段时间里,在开发人员自己的生产环境中,没有任何值得信任的MySQL分支。但是,这种情况很快就发生了改变。有几个分支引起了许多人的关注。 为什么要进行分支? 为什么需要对MySQL进行分支?这是一个非常合理的问题。成千上万的网站依赖于MySQL,并且对许多人来说,它似乎是一个很好的解决方案。但是,通常就是这样,适合许多人并不一定适合所有人。这促使一些开发人员想要根据自己的需要开发出更好的解决方案。还有什么能比将良好的解决方案转换为完美的解决方案更好的呢?。 下面我们将介绍这些分支寻求改变的更多细节。一些分支认为MySQL变得太臃肿了,提供了许多用户永远不会感兴趣的功能,牺牲了性能的简单性。如果人们对更精简的MySQL 4特别满意,那么为什么还要在MySQL 5中添加额外的复杂性呢?对于此分支来说,更好的MySQL分支应该更简单、更快捷,因此提供的功能也较少,但这样会使这些功能极其迅速地发挥作用,并且牢记目标受众,在本例中,目标受众是高可用性网站。 对于其他分支来说,MySQL并没有提供足够多的新功能,或者是添加新功能的速度太慢了。他们可能认为MySQL没有跟上高可用性网站的目标市场的发展形势,这些网站运行于具有大量内存的多核处理器之上。正如熟悉MySQL的人所知道的那样,MySQL提供了两种存储引擎:MyISAM和InnoDB。这一分支认为这两种存储引擎都没有提供他们所需的内容,因此他们创建了一种非常适合其目标的新存储引擎。 此外,一些分支的最高目标是成为MySQL的替代产品,在这些产品中,您可以轻松地访问它们的分支,无需更改任何代码。该分支使用与MySQL相同的代码和界面,因此使过渡变得非常容易。但是,另一个分支声称它与MySQL不兼容,需要更改代码。每个分支的成熟度各不相同,一些分支声称已经准备就绪可以投入生产,而另外一些则声称目前自己还远达不到这一最高目标。 最后,关于MySQL在Oracle下将如何发展仍不太确定。Oracle收购了Sun,也收购了MySQL,现在Oracle控制MySQL产品本身,并领导开发社区开发新的成品。由于Oracle已经有了一个商业数据库,因此人们担心他们可能没有足够的资源来使MySQL保持其领先地位。因此,许多分支也是这些潜在担心所产生的结果,他们担心MySQL作为领先的免费开源数据库提供的功能可能太少、发布周期太慢并且支持费用更昂贵。 XtraDB XtraDB是一款独立的产品,但它仍被认为是MySQL的一个分支。XtraDB实际上是基于MySQL的数据库的一个存储引擎。XtraDB被认为是已成为MySQL一部分的标准MyISAM和InnoDB的一个额外存储引擎。MySQL 4和5使用默认的MyISAM存储引擎安装每个表。InnoDB也是一个相对较新的存储引擎选择,在建立数据库时,数据库管理员和开发人员可以基于每个表选择存储引擎类型。两个存储引擎的主要区别是:MyISAM没有提供事务支持,而InnoDB提供了事务支持。其他差别是许多细微的性能差别,与MyISAM相比,InnoDB提供了许多细微的性能改进,并且在处理潜在的数据丢失时提供了更高的可靠性和安全性。似乎InnoDB是用于未来改进的更适合的存储引擎,因此从版本5.5开始,MySQL已将默认存储引擎从MyISAM更改为InnoDB。 基于这些优势,InnoDB存储引擎本身拆分出了一个分支,一个名为XtraDB的更新的存储引擎。这个存储引擎有多新呢?它3年前由Percona首次发布,因此它相对较新。它是专门针对在现代服务器上运行的现代高可用性网站设计的。它被设计为在具有十几个或更多核心和大内存(32GB及更多)的服务器上运行。任何公司都可以从服务器管理公司购买这些类型的服务器,因此应将数据库设计为能够充分利用这些服务器。 XtraDB分支有另一个目标,即成为InnoDB存储引擎的简单替代,这样用户就可以轻松地切换其存储引擎,无需更改任何现有的应用程序代码。XtraDB必须能够向后兼容InnoDB,以提供它们想要添加的所有新功能和改进。它们实现了此目标。 XtraDB的速度有多快?我找到的一个性能测试表明:与内置的MySQL 5.1 InnoDB 引擎相比,它每分钟可处理2.7倍的事务。(请参见参考资料)。速度显然是一个不可以忽略的因素,在考虑替代产品时更是如此。 Percona 与内置的MySQL存储引擎相比,XtraDB提供了一些极大的改进,但它不是一款独立产品,也无法轻松放入现有MySQL安装。因此,如果您想使用这款新引擎,则必须使用提供它的产品。 Percona Server就是这样一款产品,由领先的MySQL咨询公司Percona发布。Percona Server是一款独立的数据库产品,为用户提供了换出其MySQL安装并换入Percona Server产品的能力。通过这样做,就可以利用XtraDB存储引擎。Percona Server声称可以完全与MySQL兼容,因此从理论上讲,您无需更改软件中的任何代码。这确实是一个很大的优势,适合在您寻找快速性能改进时控制质量。因此,采用Percona Server的一个很好的理由是,利用XtraDB引擎来尽可能地减少代码更改。 此外,他们是XtraDB存储引擎的原作者。Percona将此代码用作开源代码,因此您可以在其他产品中找到它,但引擎的最初创建者与编写此产品的是同一个人,所以您可以随心所欲地使用此信息。 下面是Percona Server的声明,该声明来自它们自己的网站: 可扩展性:处理更多事务;在强大的服务器上进行扩展 性能:使用了XtraDB的Percona Server速度非常快 可靠性:避免损坏,提供崩溃安全(crash-safe)复制 管理:在线备份,在线表格导入/导出 诊断:高级分析和检测 灵活性:可变的页面大小,改进的缓冲池管理 Percona团队的最终声明是“Percona Server是由Oracle发布的最接近官方MySQL Enterprise发行版的版本”,因此与其他更改了大量基本核心MySQL代码的分支有所区别。Percona Server的一个缺点是他们自己管理代码,不接受外部开发人员的贡献,以这种方式确保他们对产品中所包含功能的控制。 MariaDB 另一款提供了XtraDB存储引擎的产品是MariaDB产品。它与Percona产品非常类似,但是提供了更多底层代码更改,试图提供比标准MySQL更多的性能改进。MariaDB直接利用来自Percona的XtraDB引擎,由于它们使用的是完全相同的引擎,因此每次使用存储引擎时没有显著的差别。 此外,MariaDB提供了MySQL提供的标准存储引擎,即MyISAM和InnoDB。因此,实际上,可以将它视为MySQL的扩展集,它不仅提供MySQL提供的所有功能,还提供其他功能。MariaDB还声称自己是MySQL的替代,因此从MySQL切换到MariaDB时,无需更改任何基本代码即可安装它。 最后可能也是最重要的一点是,MariaDB的主要创建者是Monty Widenius,也是MySQL的初始创建者。Monty成立了一家名为Monty Program的公司来管理MariaDB的开发,这家公司雇佣开发人员来编写和改进MariaDB产品。这既是一件好事,也是一件坏事:有利的一面在于他们是Maria功能和bug修复的佼佼者,但公司不是以赢利为目的,而是由产品驱动的,这可能会带来问题,因为没有赢利的公司不一定能长久维持下去。 Drizzle 本文介绍的最后一款产品是Drizzle。与之前介绍的两款产品不同,Drizzle与MySQL有很大差别,甚至声称它们不是MySQL的替代产品。他们期望对MySQL进行一些重大更改,想要提供一种出色的解决方案来解决高可用性问题,即使这意味着要更改我们已经习惯了的MySQL的各个方面。 在公司的FAQ页面,阅读其中提供的问题时就会发现,Drizzle进一步地强调了其基本目标。他们不满意MySQL 4.1版本之后对MySQL代码进行的一些更改,声称许多开发人员不想花费额外的钱。他们承认其产品与SQL关系数据库甚至是不兼容的。这确实与MySQL有很大的不同。 与习惯的MySQL有如此大的变化,我们为什么还要考虑这款产品呢?准确地讲,原因与上面的是相同的,Drizzle是MySQL引擎的一次重大修改,它清除了一些表现不佳和不必要的功能,将很多代码重写,对它们进行了优化,甚至将所用语言从C换成了C++,以获得所需的代码。此外,Drizzle并没有就此结束修改,该产品在设计时就考虑到了其目标市场,即具有大量内容的多核服务器、运行Linux的64位机器、云计算中使用的服务器、托管网站的服务器和每分钟接收数以万计点击率的服务器。这是一个相当具体的市场。它太具体了吗?请记住这些类型的公司目前在其数据库方面投入的资金,如果他们可以安装Drizzle而不是MySQL,那么他们的服务器成本将削减一半,可以节省很多钱! 那么,是不是所有人都应该使用Drizzle呢?等等,正如Drizzle反复指出的那样,它与MySQL不兼容。因此,如果您现在使用的是MySQL平台,那么需要重写大量代码,才能使Drizzle在您的环境中正常工作。 尽管需要额外的工作才能让它运行,但它并不像Percona或MariaDB那样快速且易于使用。我之所以介绍Drizzle,是因为尽管目前它可能不是您的选择,但几年之后,它很可能会成为一些人的选择。因为本文的目标是提高您对未来使用的工具的认识,所以这是向您介绍此产品的好机会。许多领先的DB专家相信Drizzle将成为未来5年内高可用性数据库安装的选择。 Drizzle是完全开源的产品,公开接受开发人员的贡献。它不像MariaDB那样有支持其开发的公司,也不像Percona那样有大量外部开发人员为其提供贡献。Drizzle有很好的成长空间并会提供一些新功能,但可能需要重写大部分MySQL代码。 对比图 下面是本文中介绍的三款MySQL分支产品的概述。 结束语 本文介绍了MySQL产品的三个新分支,旨在解决它们使用MySQL时遇到的一些问题。这三个分支都是免费的开源产品。在使用时,您需要根据MySQL已提供的功能来权衡它们的优缺点。我相信,对于阅读本文的大多数人来说,MySQL将仍然是满足数据库需求的首选。我很怀疑阅读本文的大多数读者都是每小时拥有1,000,000点击率的网站的所有者。我想再次强调的是,MySQL仍然是一款非常出色的产品,是一个非常适合大多数使用情况的数据库。 但是,对于那些认为自己的网站需要比目前MySQL所能提供的更高的可用性、可扩展性和性能的人来说,这3款产品中的任意一款产品都可能为您提供所需的解决方案。更进一步地说,如果您认为您的网站将成为能获得很多利润的网站,那么可以考虑使用三款产品中的一款产品,在问题出现之前解决它们。 最后,出现这些MySQL分支的根本原因是:一些创作者想更改MySQL的一些基本功能,因为他们无法等到MySQL自己完成这些工作。此外,Oracle的现状威胁到了MySQL的未来,并且许多开发人员(包括MySQL的原始开发人员)都担心该产品的未来,他们还担心Oracle是否会投入精力保持该产品的领先数据库的地位。这些担忧在我看来都是合理的,因此在我们迈向未来时要牢记这些产品。 作者简介: Michael Abernethy在Michael Abernethy的12年技术生涯中,他与各种不同的技术和客户打交道。他现在专注于构建更好和更为复杂的Web应用程序、测试运行这些应用程序所在的浏览器的限制,同时也在尝试解决如何让Web应用程序更容易创建和维护。他空闲时,会陪伴他的孩子们。 转自 http://www.csdn.net/article/2011-12-29/309890
-
个人分类: SQL|204 次阅读|0 个评论
-
-
分享
数据库构建和数据分析
-
Alfred_G 2014-7-31 16:01
-
做基础的数据库构建和数据库分析确实是两种不同的事情。数据库构建要搭平台,C,C++,Java,Pathyon,SQL至少懂得至少一两种方法。但数据分析就是统计学了,其实,无论是stata,SAS,R,凡是用到统计的,也无非就是做描述(频数、频率、分布、离散、集中等),画图,建模,其实也都差不多。话说回来,千里之行,始于足下。继续打基础,好好学吧。面壁勉励自己!
-
0 个评论
-
-
分享
1章:数据库概念(2)
-
芐雨 2014-7-24 16:14
-
本章中所涉及的主题 解释了: 概念和技术,怎么 使用 数据库 提供你所需要 的数据规范 、 计划和实施有效的 表的 技巧 。 如果你已经熟悉参与数据库设计的概念,你可能想跳过本章。 如果你是新到 的 数据库的世界 , 花一些时间在 本章 深入了解 这些重要的议题 。 Excel的限制和如何数据库来突破 经理,会计师,分析师们不得不接受一个简单事实: Excel已经无法满足 他们的分析需求。 他们都 遇到了 根本性的问题, 源于一个 或多个 Excel 的 三个问题: 可扩展性 , 分析过程 的透明度 , 以及 数据与表现 分离 。
-
个人分类: excel商业智能|0 个评论
-
-
分享
目录一
-
芐雨 2014-7-22 12:06
-
第一部分: Excel 的商业智能 1章: 数据库的重要 概念 2章: 数据透视表 原理 3章:认识 Power Pivot 4章: 用 Power Pivot处理数据 5章:用 Power View 创建 仪表板 6章:添加 地图Power Map 7章:通过Power Query添加数据
-
个人分类: excel商业智能|0 个评论
-
-
分享
常用stata命令2
-
xingyun1688 2014-4-28 11:35
-
(续) 前面说的都是对单个数据库的简单操作,但有时我们需要改变数据的结构,或者抽取来自不同数据库的信息,因此需要更方便的命令。这一类命令中我用过的有:改变数据的纵横结构的命令reshape,生成退化的数据库collapse,合并数据库的命令append和merge。 纵列(longitudinal)数据通常包括同一个行为者(agent)在不同时期的观察,所以处理这类数据常常需要把数据库从宽表变成长表,或者相反。所谓宽表是以每个行为者为一个观察,不同时期的变量都记录在这个观察下,例如,行为者是厂商,时期有2000、2001年,变量是雇佣人数和所在城市,假设雇佣人数在不同时期不同,所在城市则不变。宽表记录的格式是每个厂商是一个观察,没有时期变量,雇佣人数有两个变量,分别记录2000年和2001年的人数,所在城市只有一个变量。所谓长表是行为者和时期共同定义观察,在上面的例子中,每个厂商有两个观察,有时期变量,雇佣人数和所在城市都只有一个,它们和时期变量共同定义相应时期的变量取值。 在上面的例子下,把宽表变成长表的命令格式如下: reshape long (雇佣人数的变量名), i((标记厂商的变量名)) j((标记时期的变量名)) 因为所在城市不随时期变化,所以在转换格式时不用放在reshape long后面,转换前后也不改变什么。相反地,如果把长表变成宽表则使用如下命令 reshape wide (雇佣人数的变量名), i((标记厂商的变量名)) j((标记时期的变量名)) 唯一的区别是long换成了wide。 collapse的用处是计算某个数据库的一些统计量,再把它存为只含有这些统计量的数据库。用到这个命令的机会不多,我使用它是因为它可以计算中位数和从1到99的百分位数,这些统计量在常规的数据描述命令中没有。如果要计算中位数,其命令的语法如下 collapse (median) ((变量名)), by((变量名)) 生成的新数据库中记录了第一个括号中的变量(可以是多个变量)的中位数。右面的by选项是根据某个变量分组计算中位数,没有这个选项则计算全部样本的中位数。 合并数据库有两种方式,一种是增加观察,另一种是增加变量。第一种用append,用在两个数据库的格式一样,但观察不一样,只需用append空格using空格(文件名)就可以狗尾续貂了。简单明了,不会有什么错。另一种就不同了,需要格外小心。如果两个数据库中包含共同的观察,但是变量不同,希望从一个数据库中提取一些变量到另一个数据库中用merge。完整的命令如下: use (文件名) sort (变量名) save (文件名), replace use (文件名) sort (变量名) merge (变量名) using (文件名), keep((变量名)) ta _merge drop if _merge==2 drop merge save (文件名), replace 讲到这里似乎对于数据的生成和处理应该闭嘴了。大家可能更想听听估计、检验这些事情。但我并不想就此止住,因为实际中总是有一些简单套用命令无法轻易办到的特殊要求。此时至少有两条路可以通向罗马:一是找到更高级的命令一步到位;二是利用已知简单命令多绕几个圈子达到目的。 下面讲一个令我刻骨铭心的经历,这也是迄今我所碰到的生成新数据中最繁复的了。原始数据中包含了可以识别属于同一个家庭中所有个人的信息和家庭成员与户主关系的信息。目的是利用这些信息建立亲子关系。初步的构想是新数据库以子辈为观察,找到他们的父母,把父母的变量添加到每个观察上。我的做法如下: use a1,clear keep if gender==2agemos=96a8~=1line10 replace a5=1 if a5==0 keep if a5==1|a5==3|a5==7 ren h hf ren line lf sort wave hhid save b1,replace keep if a5f==1 save b2,replace use b1,clear keep if a5f==3|a5f==7 save b3,replace use a3,clear sort wave hhid merge wave hhid using CHNS01b2, keep(hf lf) ta _merge drop if _merge==2 sort hhid line wave by hhid line wave: egen x=count(id) drop x _merge save b4,replace use a4,clear sort wave hhid merge wave hhid using CHNS01b3, keep(a5f a8f schf a12f hf agemosf c8f lf) ta _merge drop if _merge==2 sort hhid line wave by hhid line wave: egen x=count(id) gen a=agemosf-agemos drop if a216x==3 gen xx=x gen xxx=x gen y=lf if x==1 replace y=lf if x==2xx==1 replace y=lf if x==2xxx==1 keep if x==1|(lf==yx==2) drop a x xx xxx y _merge save b5,replace log close exit,clear 我的方法是属于使用简单命令反复迂回地达到目的那一类的,所以非常希望有更简便的方法来替代。不过做实证时往往不是非常追求程序的漂亮,常常也就得过且过了。曾经有人向我索要过上面的处理方法,因为一直杂事缠身,就没有回复。现在公开了,希望对需要的人能有所帮助,我也懒得再去一一答复了。 stata强大的功能体现在它可以方便地回归微观数据。而回归也是微观实证中最重要的方法。下面就开始讲stata中和回归有关的常用命令。 基本回归方法有两种:线性设定下的最小二乘法(OLS)和两阶段最小二乘法(2SLS)。他们在实证分析中应用广泛,十分详细地掌握这两种方法是实证研究的基本要求。讲解的顺序是先依次介绍如何在stata中实现OLS和2SLS估计,然后再分析如何在实际问题中选择合理的方法。后一部分受JoshuaAngrist教授的影响很大,因此,在后面引用他的思想时会详细注明。 假设你已经清楚地了解待估计方程的形式,那么回归命令的基本格式就十分简单明了: reg(被解释变量)(解释变量1)(解释变量2)…… 方程中的相应变量可以简单地放在reg的后面。执行上面的命令后,stata会出现两个表格,分别报告一些方差分析和回归的参数估计结果。我们最关心的是参数的大小和显著性,这在第二个表格中列出。表格的最左边一栏列出了解释变量,在它的右边是相应的系数估计值,然后依次是估计值的标准误,t比率,原假设为系数的真实值等于零时错误地拒绝该假设的概率——p值,以及该估计值的置信度为(1-5%)的置信区间。 我看到回归结果的第一眼是瞄着最关心的解释变量的符号、大小和显著性。看看解释变量影响的方向和大小是不是符合理论的预期,是不是合乎常识,以及这个估计值是不是显著。标记显著性的统计量是t统计量,在经典假设下,它服从t分布。t分布和标准正态分布形状很相似,但它的“尾巴”要比标准正态分布的“肥”一些,在样本量比较小的时候尤其明显,当样本量趋于无穷时,t分布的极限分布是标准正态分布。大家对标准正态分布的分布函数上一些关键点比较熟悉,比如,1.96是97.5%的关键点,1.64是95%的关键点,所以,我们希望知道什么时候可以安全地使用标准正态分布。下表列出了一些小自由度下二者的差异(Beyer1987“CRCStandardMathematicalTables,28thed.”;Goulden1956“MethodsofStatisticalAnalysis,2nded.”)。可以看出,自由度超过一百时,二者的差别就已经相当小了。所以,当样本量的数量级是100个或以上时,可以直接认为t比率服从标准正态分布,并以此做检验。 90%95%97.5%99.5% 13.077686.3137512.706263.6567 21.885622.919994.302659.92484 31.637742.353363.182455.84091 41.533212.131852.776454.60409 51.475882.015052.570584.03214 101.372181.812462.228143.16927 301.310421.697262.042272.75000 1001.290071.660231.983972.62589 1.281561.644871.959992.57588 读者读到这里可能会笑话我了,stata不是已经报告了t检验的p值和置信区间了吗?为什么不直接察看这些结果呢?原因在于实证文献往往只报告参数的估计值和标准误,需要读者自己将估计值和标准误相除,计算显著性。而且当你在写实证文章时,也应该报告参数的估计值和标准误。这比报告估计值和它的p值更规范。 伴随回归命令的一个重要命令是predict。回归结束后,使用它可以得到和回归相关的一些关键统计量。语法如下: predict(新变量名),(统计量名) 这里的统计量名是一些选项。常用的选项有:xb(回归的拟合值。这是默认选项,即不加任何选项时,predict赋予新变量前一个回归的拟合值。);residuals(残差);leverage(杠杆值)。下面具一个例子来解释predict的用法。 有时样本中的一个特别的观察值会显著地改变回归结果。这样的观察值可以笼统地分为三类:outliers,leverage和influence。Outliers是针对残差而言的,指那些回归中残差很大的观察;leverage是针对解释变量而言的,是解释变量相对其平均值偏里很大的观察;influence是针对估计结果而言的。如果去掉这个观察会明显地改变估计值,那么这个观察就是一个influence。Influence可以看作outliers和leverage共同作用的结果。异常观察可能是由于样本的特性,也可能是因为录入错误。总之,我们希望找到它们。 回归后的predict命令可以发现这些异常观察(命令来自UCLA的“RegressionwithStata”第二章)。发现outliers,leverage和influence的命令如下: predictrs,rstudent predictl,leverage predictcsd,cooksd predictdf,dfits 这些统计量都有相应的关键值。当统计量(或其绝对值)超过关键值时就应该仔细检查相应的观察,确认是否属于录入错误。rstudent是用来发现outliers的统计量,其关键值是2,2.5和3。leverage是用来发现leverage的统计量,其关键值是(2k+2)/n,其中k解释变量的个数,n是样本量。Cooksd和DFITS是探测influence的统计量。它们都综合了残差和杠杆的信息,而且二者非常类似,只是单位不同,因而给出的结果也差不多。Cooksd的关键值是4/n。DFITS的关键值是2*sqrt(k/n)。 (续) 在使用最小二乘法估计时,两个通常被质疑的问题是数据是否存在多重共线性和异方差。 多重共线性是指解释变量之间的相关性。通常我们假设解释变量之间是相关的,而且允许解释变量存在相关性,并控制可以观察的因素正是OLS的优点。如果把多重共线性看作一个需要解决的问题,那么需要把它解释为相关性“较大”。这样,变量之间没有相关性不好,相关性太大也不好,优劣的分割真是颇费琢磨。而且多重共线性并没有违反任何经典假定,所以,这个问题没有很好的定义。本质上讲,在样本给定时,多重共线性问题无法解决,或者说它是一个伪问题。 先看一下为什么解释变量之间的相关性大会有问题。在OLS回归的经典假设(除正态假设外)下,某个系数的OLS估计值的总体方差与扰动项的方差成正比,与解释变量的总方差(一般地,我们视解释变量为随机变量)成反比,是该变量对其它解释变量回归的拟合优度的增函数。这个拟合优度可以理解为该变量的总变动中可以由其他解释变量解释的部分。当这个值趋近于1时,OLS估计值的总体方差趋向于无穷大。总体方差大时,样本方差也大的概率就大,t检验就会不准确。尽管多重共线性没有违背任何经典假设,但是OLS方法有时无法准确估计一些参数。这个问题可以理解为数据提供的信息不足以精确地计算出某些系数。最根本的解决方法当然是搜集更大的样本。如果样本给定,也许我们应该修改提出的问题,使我们能够根据样本数据做出更精确的判断。去掉一个解释变量,或者合并一些解释变量可以减少多重共线性。不过要注意的是去掉相关的解释变量会使估计有偏。 实际操作时使用方差膨胀系数衡量解释变量的多重共线性。我们只需在回归之后使用vif命令就可以得到方差膨胀系数。在命令行中敲入vif并回车,stata会报告一个包含所有解释变量的方差膨胀系数的表格,如果方差膨胀系数大于10,这个变量潜在地有多重共线性问题。 异方差是一个更值得关注的问题。首先简单地介绍一下异方差会带来哪些问题。第一、异方差不影响OLS估计的无偏性和一致性。第二、异方差使估计值方差的估计有偏,所以此时的t检验和置信区间无效。第三、F统计量不再服从F分布,LM统计量不再服从渐进卡方分布,相应的检验无效。第四、异方差使OLS不再是有效估计。总之,异方差影响推断是否有效,降低估计的效率,但对估计值的无偏性和一致性没有影响。 知道了异方差作用的原理,很自然地就有了对付它的办法。第一种方法是在不知道是否存在异方差时,通过调整相应的统计量纠正可能带来的偏差。OLS中实现对异方差稳健的标准误很简便。相应的命令是在原来的回归命令后面加上robust选项。如下: reg(被解释变量)(解释变量1)(解释变量2)……,robust White(1980)证明了这种方法得到的标准误是渐进可用(asymptoticallyvalid)的。这种方法的优点是简单,而且需要的信息少,在各种情况下都通用。缺点是损失了一些效率。 另一种方法是通过直接或间接的方法估计异方差的形式,并获得有效估计。典型的方法是WLS(加权最小二乘法)。WLS是GLS(一般最小二乘法)的一种,也可以说在异方差情形下的GLS就是WLS。在WLS下,我们设定扰动项的条件方差是某个解释变量子集的函数。之所以被称为加权最小二乘法,是因为这个估计最小化的是残差的加权平方和,而上述函数的倒数恰为其权重。 在stata中实现WLS的方法如下: reg(被解释变量)(解释变量1)(解释变量2)…… 其中,aweight后面的变量就是权重,是我们设定的函数。 一种经常的设定是假设扰动项的条件方差是所有解释变量的某个线性组合的指数函数。在stata中也可以方便地实现: 首先做标准的OLS回归,并得到残差项; reg(被解释变量)(解释变量1)(解释变量2)…… predictr,resid 生成新变量logusq,并用它对所有解释变量做回归,得到这个回归的拟合值,再对这个拟合值求指数函数; genlogusq=ln(r^2) reglogusq(解释变量1)(解释变量2)…… predictg,xb genh=exp(g) 最后以h作为权重做WLS回归; reg(被解释变量)(解释变量1)(解释变量2)…… 如果我们确切地知道扰动项的协方差矩阵的形式,那么GLS估计是最小方差线性无偏估计,是所有线性估计中最好的。显然它比OLS更有效率。虽然GLS有很多好处,但有一个致命弱点:就是一般而言我们不知道扰动项的协方差矩阵,因而无法保证结果的有效性。 到现在我们已经有了两种处理异方差的方法:一是使用对异方差稳健的标准误调整t统计量,并以此作推断;另一种是设定异方差的形式,使用可行的GLS得到有效估计。下面总结一下标准的OLS估计同上述两种方法的优劣,并结合检验异方差的方法,给出处理异方差的一般步骤。
-
212 次阅读|0 个评论
-
-
分享
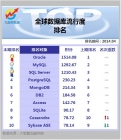
全球数据库流行度 排名
-
大智慧数据 2014-4-21 17:41
-
大数据时代的到来,催生了相关数据产品的发展。最新的数据表明,"Oracle"仍然是全球数据库中流行度最高的数据库软件,"MySQL"与"SQL Server"分别排名排名二、三位。
-
161 次阅读|0 个评论
-
-
分享
stata常用命令精选
-
Joycelyn小乔 2013-12-30 21:33
-
save命令 FileSave As 例1. 表1.为某一降压药临床试验数据,试从键盘输入Stata,并保存为Stata格式文件。 STATA数据库的维护 排序 SORT 变量名1 变量名2 …… 变量更名 rename 原变量名 新变量名 STATA数据库的维护 删除变量或记录 drop x1 x2 /* 删除变量x1和x2 drop x1-x5 /* 删除数据库中介于x1和x5间的所有变量(包括x1和x5) drop if x0 /* 删去x10的所有记录 drop in 10/12 /* 删去第10~12个记录 drop if x==. /* 删去x为缺失值的所有记录 drop if x==.|y==. /* 删去x或y之一为缺失值的所有记录 drop if x==.y==. /* 删去x和y同时为缺失值的所有记录 drop _all /* 删掉数据库中所有变量和数据 STATA的变量赋值 用generate产生新变量 generate 新变量=表达式 generate bh=_n /* 将数据库的内部编号赋给变量bh。 generate group=int((_n-1)/5)+1 /* 按当前数据库的顺序,依次产生5个1,5个2,5个 3……。直到数据库结束。 generate block=mod(_n,6) /* 按当前数据库的顺序,依次产生1,2,3,4,5,0。 generate y=log(x) if x0 /* 产生新变量y,其值为所有x0的对数值log(x),当x=0时,用缺失值代替。 egen产生新变量 set obs 12 egen a=seq() /*产生1到N的自然数 egen b=seq(),b(3) /*产生一个序列,每个元素重复#次 egen c=seq(),to(4) /*产生多个序列,每个序列从1到# egen d=seq(),f(4)t(6) /*产生多个序列,每个序列从#1到#2 encode 字符变量名,gen(新数值变量名) 作用:将字符型变量转化为数值变量。 STATA数据库的维护 保留变量或记录 keep in 10/20 /* 保留第10~20个记录,其余记录删除 keep x1-x5 /* 保留数据库中介于x1和x5间的所有变量(包括x1和x5),其余变量删除 keep if x0 /* 保留x0的所有记录,其余记录删除 STATA数据库的维护 替换已存在的变量值 replace 变量=表达式 replace bolck=6 if block==0 /* 将block=0的数全部替换为6。 replace z=. if z0 /* 将所有小于0的z值用缺失值代替。 replace age = 25 in 17 /* 将第17条记录中的变量age替换为25。 for var x* : replace X=0 if X==. /* 将所有第一个字母为x的变量替换为0,如果该变量的值为缺失值 纵向连接数据库 Ex3-3.dta: x0 x1 1. 3550 2450 2. 2000 2400 3. 3000 1800 4. 3950 3200 5. 3800 3250 use "E:教学上机ex3-2.dta", clear l x0 x1 g 1. 2450 1450 2 2. 2100 2400 2 3. 2300 3800 2 4. 1590 4200 2 append using E:教学上机ex3-3.dta l x0 x1 g 1. 2450 1450 2 2. 2100 2400 2 3. 2300 3800 2 4. 1590 4200 2 5. 3550 2450 . 6. 2000 2400 . 7. 3000 1800 . 8. 3950 3200 . 9. 3800 3250 . 横向联接数据库 Ex3-5.dta: bh y0 y1 x0 1. 1 35 79.2 2 2. 3 45 47.4 8 3. 4 52 34.6 6 4. 6 66 28.0 9 命令 . drop _all . use E:教学MPH上机ex3-5.dta . sort bh . save "E:教学MPH上机ex3-5.dta",replace file E:教学MPH上机ex3-5.dta saved . use E:教学MPH上机ex3-4.dta . sort bh . merge bh using E:教学MPH上机ex3-5.dta 结果 bh x0 x1 y0 y1 _merge 1. 1 12 24 35 79.2 3 2. 2 15 26 . . 1 3. 3 16 49 45 47.4 3 4. 4 18 57 52 34.6 3 5. 5 20 68 . . 1 6. 6 9 . 66 28 2 列数据接龙 Stack 变量名,into(新变量名)|group(#) 示例 统计描述及区间估计 定量资料的一般描述 均数、标准差、百分位数、中位数 summarize 统计描述及区间估计 百分位数 centile ) cci normal meansd level(#) ] 统计描述及区间估计 定性资料的一般描述 按照分类变量给出频数和构成比 tabulate 变量名 例2. 有三组(group)患者,男女(sex)若干人,sex=1表示男性,sex=0表示女性。测得其血红蛋白浓度(x1,%)和红细胞计数(x2,万/mm3),资料存入c:mydataex2.dta。试对其进行描述。 见ex5-2 . use c:mydataex2 . tab group . tab sex . tab group, sum(x1) . tab group, sum(x2) 统计描述及区间估计 可信区间的估计 ci 变量 cii 观察数 均数 标准差 level(#) /* 指定可信度,缺失时为95(%) by(分组变量) /* 指定按分组变量分别估计均数的可信区间 total /* 指定除按分组变量估计可信区间外,还对整个数据估计,仅用于指定了by(分组变量)时 . use c:mydataex2 . sort group /* 在用by(分组变量)前,必须对分组变量排序 . ci x1 x2, by(group) STATA的作图 作图命令GRAPH graph 图形类型 histogram /* 直方图,为缺省值。 oneway /* 一维散点图 twoway /* 二维散点图、线图 matrix /* 二维散点图阵 bar /* 条图、百分条图 pie /* 圆(饼)图 box /* 箱式图 star /* 星形图 STATA的作图 作图命令GRAPH 常用选项 bin(#) /* 将数据分几组,缺省为5。 freq /* 指定纵轴用频数表示,否则为频率。 normal /* 给直方图加上相应正态曲线。 xlab/ylab/ /*指定坐标轴的界点。 b2/l2 /*指定坐标轴的副标题。 STATA的作图 如何利用STATA绘制频数分布图? 例 130名14岁女孩身高资料。 gra x,bin(10) freq normal xlab(124,128,132,136,140,144,148,152,156,160,164) ylab(5,10,15,20,25,30,35,40) 数值变量资料的描述 均数、几何均数、中位数、百分位数 极差、四分位数间距、方差、标准差 变异系数 对称分布 均数±标准差 偏态分布 中位数±四分位数间距 数值变量资料的描述 means summarize centile 其他选项 detail /* 详细描述,缺失时为简单描述 centile(#) /* 指定需要计算的百分位数 某市1997年12岁男童120人的身高(cm)资料如下 sum x sum x,d sum x if x140 sum x if x140,d centile x centile x,centile(25,50,75) 例 有五份血清的抗体效价为 1:10, 1:20, 1:40, 1:80, 1:160, 描述其抗体滴度的平均水平。 means x STATA的作图 作图命令graph 简写gra gra 图形类型 histogram /* 直方图 oneway /* 一维散点图 twoway /* 二维散点图、线图 matrix /* 二维散点图阵 bar /* 条图、百分条图 pie /* 圆(饼)图 box /* 箱式图 star /* 星形图 直方图 数值变量资料的统计分析 样本均数与总体均数比较的t检验 配对设计 t检验 成组设计t 检验 方差齐性检验 样本均数与总体均数比较的t检验 ttest 变量名= #val ttesti #obs #mean #sd #val 例 问题: 统计量与参数不同的两种可能 其一:抽样误差 (偶然的、随机的、较小的) 其二:本质上的差别 (必然的、大于随机误差) 例 样本:某医生随机抽查10名某病患者的血红蛋白,求得其均数为12.59 (g/dl),标准差为1.632619 (g/dl) 。 问题:该病患者的平均Hb含量是否与正常人的平均Hb含量相同 (正常人的平均Hb含量为14.02 (g/dl)。 STATA 命令 ttest 变量名= #val ttest x =14.02 STATA 结果 ttest x=14.02 One-sample t test ---------------------------------------------------------------------------- Variable | Obs Mean Std. Err. Std. Dev. ---------+------------------------------------------------------------------ x | 10 12.59 .5162794 1.632619 11.42209 13.75791 ---------------------------------------------------------------------------- Degrees of freedom: 9 Ho: mean(x) = 14.02 Ha: mean 14.02 Ha: mean ~= 14.02 Ha: mean 14.02 t = -2.7698 t = -2.7698 t = -2.7698 P t = 0.0109 P |t| = 0.0218 P t = 0.9891 STATA 命令 ttesti #obs #mean #sd #val ttesti 10 12.59 1.632619 14.02 配对设计t检验 ttest 变量1=变量2 STATA 命令 ttest x1=x2 STATA 结果 ttest x1=x2 Paired t test ------------------------------------------------------------------- Variable | Obs Mean Std. Err. Std. Dev. ---------+--------------------------------------------------------- x1 | 10 12.59 .5162794 1.632619 11.42209 13.75791 x2 | 10 13.27 .3415813 1.080175 12.49729 14.04271 ---------+--------------------------------------------------------- diff | 10 -.6799999.5204272 1.645735 -1.857288 .4972881 ------------------------------------------------------------------- Ho: mean(x1 - x2) = mean(diff) = 0 Ha: mean(diff) 0 Ha: mean(diff) ~= 0 Ha: mean(diff) 0 t = -1.3066 t = -1.3066 t = -1.3066 P t = 0.1119 P |t| = 0.2237 P t = 0.8881 成组设计 t 检验 ttest 变量1=变量2, unpaired ttest 变量,by(分组变量) ttesti #obs1 #mean1 #sd1 #obs2 #mean2 #sd2 unpaired 表示非配对的,如不选就作配对t检验 unequal 表示假设两组方差不齐,如不选表示假设两组方差达到齐性 例(成组设计) 分别测得14例老年人煤饼病人及11例正常人的尿中17 酮类固醇排出量(mg/dl)如下,试比较两组的均数有无差别 STATA 命令 ttest x1=x2, unpaired ttest x, by(g) STATA 结果 ttest x1=x2,unp Two-sample t test with equal variances ---------------------------------------------------------------------------- Variable | Obs Mean Std. Err. Std. Dev. ---------+------------------------------------------------------------------ x1 | 14 4.377857 .3875 1.449892 3.540714 5.215 x2 | 11 5.528182 .5232431 1.735401 4.362324 6.69404 ---------+------------------------------------------------------------------ combined | 25 4.884 .3306453 1.653227 4.201582 5.566418 ---------+------------------------------------------------------------------ diff | -1.150325 .636752 -2.467547 .1668972 ---------------------------------------------------------------------------- Degrees of freedom: 23 Ho: mean(x1) - mean(x2) = diff = 0 Ha: diff 0 Ha: diff ~= 0 Ha: diff 0 t = -1.8066 t = -1.8066 t = -1.8066 P t = 0.0420 P |t| = 0.0839 P t = 0.9580 两组资料间的方差齐性检验 sdtest 变量名1 = 变量名2 sdtest 变量,by(分组变量) sdtesti #obs1 #mean1 #sd1 #obs2 #mean2 #sd2 单因素方差分析及方差齐性检验 oneway 因变量 分组变量, noanova /* 不打印方差分析表 missing /* 将缺省值作为单独的一组 tabulate /* 打印各组的基本统计量表 简写:t scheffe /* Scheffe法 简写:sch Bonferroni /* Bonferroni法 简写:bon sidak /* Sidak法 简写:si 各组均数两两比较 oneway x group,noanova sch Comparison of var3 by group (Scheffe) Row Mean-| Col Mean | 1 2 ---------+---------------------- 2 | -.425 | 0.426 | 3 | -.91 -.485 | 0.024 0.330 STATA软件及其应用-III 秩和检验和相关与回归分析 秩变换 配对资料的秩和检验; 两组资料的秩和检验; 多组资料的秩和检验; 直线相关分析; 等级相关分析; 直线回归分析; 秩变换 genrank 新变量= 原变量 egen 新变量=rank(原变量) 配对资料的秩和检验 signrank 变量1 = 变量2 两组资料的秩和检验 ranksum 观察值变量,by(分组变量) 两组资料的秩和检验 两组资料的秩和检验 例3 用复方猪胆胶囊治疗老年性慢性支气管炎患者403例,疗效见第(1)~ (3)栏。问该药对此两型支气管炎疗效是否相同? 两组资料的秩和检验 expand f ranksum x,by(g) 多组资料的秩和检验 kwallis 观察值变量, by(分组变量) 多组资料的秩和检验 直线相关和回归分析 correlate pwcorr , regress 因变量 自变量 predict 新变量 , stdp 计算估计值的标准误 stdf 估计预测值y的标准差 sig 打印相关系数假设检验之 P值 star(#) 如果相关系数的假设检验之P值小于#,则在 相关系数旁打印星号
-
个人分类: stata|194 次阅读|0 个评论
-
-
分享
小菜鸟stata入门常用命令
-
Joycelyn小乔 2013-12-30 21:30
-
(1) Stata要在使用中熟练的,大家应该多加练习。 (2) Stata的很多细节,这里不会涉及,只是选取相对重要的部分加以解。 当我们把 Stata 装好以后,首先需要了解的是它的界面。打开Stata后我们便可以看到它常用的四个窗口:Stata Results; Review; Variables; Stata Command。我们所有的运行结果都会在 StataResults 界面中显示;而命令的输入则在 Stata Command 窗口;Review 窗口记录我们使用过的命令;最后 Variables 窗口显示存在于当前数据库中的所有变量的名称。可以直接点击 Review 窗口来重新输入已使用过的命令,我们所需变量可以通过点击 Varaibles 窗口来得到,这些都可以简便我们的操作。 Stata 命令 Stata 软件功能强大,体现在它提供了丰富的命令,可以实现许多功能。每一个Stata 命令都相应的命令格式。我们在这里介绍常用的一些命令的功能和相应的格式,大家在使用Stata 的过程中会不断积累命令的相关知识。 需要对命令的帮助时可以用 help 命令查询。例如了解命令: “reg” ,就可以在Stata Command窗口输入 “help reg” ,也可以在 Help 选项下 content 中查找我们需要的相关命令。用 help查询,则窗口会显示关于该命令的详尽说明。更直接的办法是看 Examples 中的范例是如何使用该命令,阅读一些相关的说明并加以模仿。 重要习惯 我们使用 Stata 进行回归分析时,需要养成一些好的习惯。在进行一些数据量很大,过程复杂的分析时尤其重要。 (1)使用日志(log)。它可以帮助我们记录stata的运行结果。 格式:log using c:\stata8\logfiles\10.21.5_30.log (注意:我们需要先建好文件夹 c:\stata8\logfiles ) 关闭log的命令为“log close”。 格式:log close 那么“10.21.5_30.log”文件就记录了从“log using”命令 到“log close”命令之间stata运行的所有结果。 (2)Do-file。在 command 窗口输入命令的方式很受限制,我们使用工具栏中“Do-file-editor”(第8个)在 Do-file 中编程。直接的好处便是我们可以很方便的执行以前写过的命令,并记录我们需要的命令,方便下一次的使用和分析。在复杂的分析中,采用 Command 窗口输入的方式会是非常的困难,我们必须用 do-file 去编程。 在 do-file 文件中,用*表示注释内容,Stata 在运行 do-file 时会跳过这些注释语句。加入注释语句能增强do-file的可读性。我们应该养成习惯为每一个 do-file 文件写详细的注释内容。比如要说明文件名称,回归分析的目的,时间和存放位置。如果过程中生成并保存了数据文件,应写出相应数据文件的名称等。如果中途对 do-file 文件进行过修改,最好将修改过文件保存为另一个文件,以便于将来对比分析原文件和修改后的文件。 格式: *Wage_analysis.do *The program is written for the analysis of wage determination. *Data management:reshape the data to panel. *This rsult will be saved in the data file:wage1.dta * written:10/21/05 在调试 do-file 文件时,可以选择部分命令让 Stata 只运行选中部分。 我们可以保存当前使用的 do-file 文件。Review 窗口中的命令也可以保存为 do-file。方法是右键点击Review窗口,选择 Save Review Contents。 (3)存储数据。在分析一个大的数据库时,中途对数据有改动和删减,有必要在分析过程中将数据进行保存,可以用File选项中“save as”,同时要为中途保存的数据文件写一个详尽的说明文件,此外还可以在 do-file 文件中或 command 窗口中使用命令 “save” 来实现。 格式:save c:\stata\datasets\2.dta 打开数据文件 我们用Stata做回归的第一步便是打开一个数据库。我们可以用工具栏“Open”(第1个),打开相应数据文件。也可以使用命令 “use” 。 格式:use c:\data\datasets\1.dta Stata 有自己的数据格式,我们课上一般会给大家 Stata 格式的数据库。有时候,我们手头的数据格式不符合 Stata 的格式,就需要用相关软件进行转换,比如transfer,对这个问题感兴趣的同学可以课后和我们联系。如果我们的数据是 Excel 格式,那么可以直接把里面的数据拷贝粘贴到Stata 中:只需要点开数据工具栏“Data Editor”(第9个),就可以进行粘贴。 打开数据后我们可以用工具栏“Data Browse”(第10个)浏览数据。浏览数据可以帮助我们了解具体每一个数据。要了解数据具有的特征,我们必须借助Stata命令。 了解数据特征 “describe” 命令可以告诉我们每一个变量的含义。 格式:describe 具体了解每一个变量的特征,我们可以用 tabstat 命令。例如我们可以计算 wage 的均值,方差,中位数,范围,具体可以用 help tabstata 查询。 格式: tabstat wage, stats(mean) tabstat wage, stats (sd median range) (注意不要逗号) 如果我们想要了解不同教育水平的工资的均值,可以用如下命令: 格式:tabstat wage, by (educ) stats(mean) 此外可以使用 “Sum”,它是命令 “summarize” 的简写。Summarize(Sum)将汇报数据的均值和方差等信息。 格式: summarize wage sum educ exper 需要了解如“中位数”(median),我们可以进一步使用后缀detail。此时会详细报告百分比所对应的样本值。 格式:sum wage educ, detail 此外 Stata 还提供了别的命令帮助我们了解数据,如 “codebook” 命令,它与带detail后缀的“sum” 命令相似。 “table”,它将报告数据取值和相应的频率。 “tabulate” (或简写为ta)是一个很有用的命令。与table相比,ta将进一步报告数据分布的百分比。 格式: codebook wage educ table wage ta educ 利用“by”命令,我们可以了解数据更细致的特征。例如我们想知道受不同教育的人群中工资的分布。 格式: sort educ(这一步不可缺,一定需要先排序) by educ:table wage by educ:tabulate wage 画图 很多时候,画图能够直观地看到数据分布和它们之间关系。比如我们可以 “histogram” 命令画出数据分布的柱状图(histogram)。 格式: histogram wage “scatter”命令可以画出两个变量之间的分布关系。例如我们想直观的看到教育水平变化时工资的变化,可以用 “scatter” 命令或者 “graph twoway scatter” 命令。 格式: scatter wage educ graph twoway scatter wage educ “graph twoway”命令可以带别的后缀,例如 “graph twoway line” 则画的是线状图。 格式: graph twoway line wage educ “graph”命令还有很多别的功能。例如使用“graph matrix”可以了解更多的变量之间的关系。“graph bar (mean) y, over(x)”就可以了解y的平均值关于x分布的柱状图。 格式: graph matrix wage educ graph matrix wage educ exper graph bar (mean) wage, over (educ) 右键点击graph窗口可以将图片进行保存和复制。 变量 在分析的过程中,有些变量并没有在数据中提供,需要我们用原始数据或者回归的结果构造。常用的命令是 “gen” 和 “egen” 。 格式: gen educsqr=educ^2 egen命令相对复杂一些,它能生成一些“gen”命令无法生成的变量。例如可以生成wagesum 为每个人的工资和,以及生成 wagemedian 为工资的中位数(median),wagemax 为工资的最大值。 格式: egen wagesum=sum(wage) egen wagemedian=median(wage) egen wagemax=max(wage) 更复杂的如想产生一个变量“wagemax”为相同教育水平里的最高工资。 格式:egen wagemaxeduc=max (wage),by (educ) 如果我们需要替换某一变量,我们可以用的命令是“replace”。 格式: replace wagemax=wage replace wagemax=1 有时候我们在生成变量时可以加上一定条件,例如如果一个样本工资超过3,我们就定义它的变量wagehigh 的取值为1,否则为0。 格式: gen wagehigh=1 if wage=10 replace wagehigh=0 if wagehigh ==.(注意是两个等号) 我们也需要去掉过程中的暂用的变量,以方便我们浏览数据和重新定义变量。我们可以用 drop 命令。 格式:drop educsqr wagesum wagemedian wagemax wagemaxeduc wagehigh 我们可以用“keep”或“drop”命令来删除一些样本,在删除之前,我们需要了解删除带来的影响,则可以用“count”命令来了解样本取值的情况。 格式: count if wage100 count if wage10 我们可以用“sort”和“list”命令来了解数据分布的细节。例如我们想知道工资值从小到大排列在第50到70的样本的工资值。 格式: sort wage list wage in 50/70 如果我们想保留工资小于100的样本,可以有两种命令。 格式: keep if wage100 drop if wage=100 有时我们关心变量之间的相关性,可以使用“correlate”命令,它将报告变量之间的相关系数。 格式: correlate wage educ exper tenure 回归 现在我们以进入最重要的环节:回归分析。 进行 OLS 回归的命令为“reg”。 格式:reg wage educ Stata Results 窗口将报告这一回归的相关结果: . reg wage educ 表格中最后两行报告回归的斜率和截距的系数,相应的标准差、t值和P值,同时给出95%的置信区间。在表格左上方,报告了回归的总变异、解释变异和残差变异。表格右上方报告回归的R方和调整后的R方。其中F是自变量所有的系数都为0(即自变量完全没有解释力)这样一个零假设对应的F分布值。 回归会产生很多我们感兴趣的值,例如回归的拟合值以及回归的残差。Stata 提供了 predict 命令帮助我们存储这些变量。例如我们把拟合值定义为wagehat,残差定义为wageresid。 格式: predict wagehat predict wageresid, re 我们常常需要检验某一个零假设,例如在我们作了如下回归 格式:reg wage educ exper tenure nonwhite female 之后,我们想要知道 nonwhite 的系数是否显著,我们可以直接看回归结果报告,也可以用 test 命令。 格式:test nonwhite test 命令报告的结果为 F 值。而回归结果报告的为 t 值。它们之间是平方关系,而 p 值是一样的。对于更复杂的零假设,比如 nonwhite 和 female 是否同时为0。exper 的系 数和 tenure 的系数是否相等,则只能借助“test”命令。 格式: test nonwhite femalew test exper=tenure 报告回归结果 一般需要报告回归系数和相应的残差,同时报告系数的显著性。此外根据需要往往还要报告回归的拟合优度和使用的样本个数。对于回归系数的符号和大小变化,要给出相应的分析和解释。许多时候还会把检验的结果附在表格中。 下面是一个报告回归结果的表格(摘自经济学论文)。其中括号里报告的是系数的方差, All Women和 Married Women 表示两个总体,(1)(2)(3)对应不同的模型设定。 计算器 Stata 可以充当计算器用,使用 “display” 命令: 格式:display sqrt(5)*sin(0.5) 关于 Stata 的数学函数的命令格式,可以查询 help function。 原文地址:http://www.seekbio.com/biotech/soft/2010/d81933655.html 描述统计 describe describe命令可以描述数据文件的整体,包括观测总数,变量总数,生成日期,每个变量的存储类型(storage type),标签(label)等。 list summarize summarize可以提供varlist指定变量(可以不止一个)的如下统计量:Percentiles(分位数),四大最大的数和四个最小的数,Variance(方差),Std. Dev.(标准差),Skewness(偏度),Kurtosis(斜度) tabstat tabstat varlist ) ] tabstat提供 ) ]指定的统计量,可供选择的有mean(均值),count(非缺失观测值个数),sum(总和),max(最大值),min(最小值),range(最大值-最小值),sd(标准差),var(方差),cv(变易系数=标准差/均值),skewness(偏度),kurtosis(斜度),median( 中位数 ),p1(1%分位数,类似地有p5, p10, p25, p50 , p75, p95, p99),iqr(interquantile range = p75 – p25)。 比如,想知道变量pop在整个样本的均值和方差,可以使用如下命令: tabstat pop, stats(mean var) anova命令 anova y x1 x2 anova 做方差分析(analysis of variance),研究y的平均值在分类变量x1和x2不同取值之间的差异。 signrank命令 signrank y1=y2 signrank做Wilcoxon秩检验。 signtest命令 signtest y1=y2 秩检验,检验变量y1和y2的中值是否相等。检验y1的中值是否为5可用如下命令 signtest y1=5 ttest命令 ttest y1=y2 检验变量y1和y2的平均值是否相等。检验y1的平均值是否为5可用如下命令 ttest y1=5 correlate命令 correlate correlate计算varlist中变量(两两)之间的相关系数。 秩检验及结果的保存 ASK: I perform a ranksum test (i.e. Wilcoxon - Mann-Whitney U test). With -return list-, I get the saved results. Unfortunately, I see the (z) but not the Prob(z) in this list. ANSWER by "Nick Cox" ( n.j.cox@durham.ac.uk ): P-value is calculated internally as 2 * normprob(-abs(`z')) , 其中局部宏`z' 是报告为 r(z) 的统计量。 所以,在执行 -ranksum- 后,你只需要计算 2 * normprob(-abs(r(z))) 就可以得到相应P值。 比如: sysuse auto, clear ranksum price,by(foreign) local z = r(z) local p = 2*normprob(-abs(`z')) 这样, 局部宏 p 就保存了秩和检验的P值。 或者在-ranksum-后, scalar P_value = 2*normprob(-abs(r(z))) scalar list P_value
-
个人分类: stata|244 次阅读|0 个评论
-
-
分享
结构化大数据计算的理想模式
-
外键属性化 2013-7-8 15:18
-
随着社会的信息化发展,企业 IT 化的不断完善,业务的不断扩展,服务质量的不断提高,企业数据越来越庞大:如何从海量数据中快速获取自己需要的数据?如何能够完成越来越复杂的数据计算?在数据仓库和数据库中的数据以 TB\GB 级增长的时候,如何能够保证数据查询和计算的高效率和响应度?这些问题都给 CIO 带来了严峻的挑战。 针对上述的问题,包括 Teradata 、 IBM 、 ORACLE 、 EMC 、 Apache 基金会等众多的公司和机构,都提出了自己的解决方案。笔者在多年的 BI 实施过程中,对上述公司的解决方案,或多或少都有所涉及,在这里,仅按自己的理解,对这些方案进行归纳和总结,因为笔者的水平有限,观点难免有错误和片面之处,也希望读者给予指正。 笔者认为:当前数据计算所面临的问题,主要集中在三个方面:第一是数据存取和数据交换时的 I/O 瓶颈问题,第二是复杂计算模型的完备性问题,第三是数据计算本身的性能问题。 I/O 瓶颈问题,主要表现在和硬盘的交互以及通过网络输入输出,一般来说使用高转速的硬盘以及增加网络带宽可以获得一定程度的缓解,大部分情况下不会成为瓶颈。数据量大到一定程度时可以使用数据库集群,不过数据库扩容成本很高,该方案不是一个很优的选择。 复杂计算模型的完备性问题,影响的主要是开发效率。程序员一般采取两种方式实现数据计算:第一是使用 SQL/ 存储过程,众所周知, SQL 是结构化查询语言的最小完备集。但是最小完备集并不是最好用的完备集, SQL 的问题有很多:无序集合、集合化不彻底、没有对象引用等等。虽然在 SQL 2003 标准中增加了一些窗口函数,但是扩展的程度有限,易用性也有限。所以 SQL 虽然提供了完备的计算体系 , 可是开发效率太低。第二是编程实现或者使用第三方工具 。目前市面上很少有第三方工具具备完备的计算体系,编程则遇到同样的问题:开发效率太低。 数据计算本身的性能问题则是一个最严重的问题。理论上,以存储过程或复杂 SQL 来实现计算逻辑是保证性能最好的做法,数据库有很多优化措施,且本身是 c 语言开发,可以让计算更快。但是优化总是有限的,数据量大到一定程度,性能终究是个瓶颈。 能有效解决性能问题的唯一办法就是并行计算。目前提供并行计算的产品有两大类,一类是以 TD 、 GreenPlum 为代表的 MPP 数据库产品,其优点是计算快,并行算法透明,缺点是数据库扩容成本太高,每增加一个并行节点则要增加不菲的费用,一般用户承受不起。 另一类以 Hadoop 为代表的分布式数据处理的软件框架,该方案把数据存储在分布式文件系统 HDFS 里。 HDFS 分布式文件系统很好地解决了 IO 问题,并具有很强的容错能力,是个很优秀的数据存储方案。但是 Hadoop 提供的并行框架 MapReduce 则不敢苟同了,该框架是为非结构化数据的搜索统计而设计的 , 由于本身不提供算法,又没有现成的类库,导致程序员编写算法难度很高,工作量很大。同时由于 MapReduce 框架把任务拆分得过细,使得很简单的一个计算任务,需要编写数个 Map 和 Reduce 方法来实现,开发和运行效率都很低。 因此笔者认为,理想的大数据计算模式,应该具备以下特征: 1、 计算层独立于数据库和应用程序之外,既不受数据库难扩容的影响,也不受应用程序的限制。 2、 计算层能够访问分布式文件系统(如 HDFS 等),便于在海量数据时避开 IO 瓶颈。 3、 具有足够完备的计算体系,在编写算法时,有丰富的类库和方法支持,减轻开发工作量。 4、 计算层提供并行框架,并行节点扩充容易,成本低廉。且数据块的拆分比较灵活,允许程序员根据实际情况随意指定。 5、 计算层对外提供标准的数据访问接口 , 如 JDBC 等 作者介绍:张淳,从 2008 年起一直从事 BI 领域数据计算和分析方面的咨询和项目实施工作。在电信、移动、金融、能源等领域处理海量结构化数据业务方面,具有丰富的咨询和项目实施经验。现在北京微视角软件技术有限公司担任资深产品支持顾问。
-
209 次阅读|0 个评论
-
-
分享
如何使用联合国粮农组织统计数据库 FAOSTAT
-
rebeccaAndrew 2013-5-8 11:10
-
联合国粮食及农业组织(Food and Agriculture Organization of the United Nations,以下简称粮农组织),是战后成立最早的国际组织。1946年,世界粮农组织与联合国签订协议并经确认,成为联合国系统内的一个专门机构。联合国粮农组织的宗旨是:保障各国人民的温饱和生活水准;提高所有粮农产品的生产和分配效率;改善农村人口的生活状况,促进农村经济的发展,并最终消除饥饿和贫困。 联合国粮农组织的主要职能是:(1)搜集、整理、分析和传播世界粮农生产和贸易信息;(2)向成员国提供技术援助,动员国际社会进行投资,并执行国际开发和金融机构的农业发展项目;(3)向成员国提供粮农政策和计划的咨询服务;(4)讨论国际粮农领域的重大问题,制定有关国际行为准则和法规,谈判制定粮农领域的国际标准和协议,加强成员国之间的磋商和合作。可以说,粮农组织是一个信息中心,是一个开发机构,是一个咨询机构,是一个国际讲坛,还是一个制定粮农国际标准的中心。 联合国粮农组织统计数据库(FAOSTAT)是一个在线数据库。目前保存了来自210多个国家和地区的3百万个时间数列和横截面数据,内容包括农业、营养、渔业、林业、粮食、土地利用和人口。FAOSTAT家庭是个数据包,含有九个专题数据库,主页顶端功能栏列有生产、贸易、供给使用账户/粮食平衡表、粮食安全、价格、原料投入、林业、渔业等内容。 第一步,百度输入联合国粮农组织统计数据库 第二步 点击 第三步 有两个选择,经典页面和新建页面,选择新页面 第四步 可以点击不同窗口进行相关数据查询 例如 我查询了2000-2011年全球茶叶产量如图 还可以查询相关数据,例如查询板栗的价格、产量和交易量如图,可以点击下载 就可以下载相关数据 O(∩_∩)O!!!
-
290 次阅读|0 个评论
-
-
分享
我的数据查找网店新开张,有各种wind数据库等
-
ztxy1 2013-5-8 03:39
-
http://duxiuqw.taobao.com/ ,有空欢迎大家光临
-
175 次阅读|0 个评论
-
-
分享
利用期刊数据库提高论文参考文献编辑质量
-
lanruomuyu 2013-4-14 14:01
-
科技期刊论文参考文献的合理引用和准确著录是编辑论文参考文献的两个重点,利用中英文科技期刊数据库查询文献的方法可以判断论文参考文献引用是否合理,是否遵循时效性、必要性、新颖性原则;还可以逐一核对参考文献的著录内容,从而提高论文参考文献的编辑质量. http://d.wanfangdata.com.cn/Periodical_zgkjqkyj201102031.aspx
-
个人分类: 技术经验|0 个评论
-
-
分享
转载五个数据库~~https://bbs.pinggu.org/thread-2168501-1-1.html
-
几儿 2013-4-6 14:06
-
小硕期间的研究方向也基本定下来了。但常常和身边的朋友们聊天,大家抱怨最多的就是:“老师只给了一个研究方向和几个关键词,我到哪去找最新的英文文献啊?”或者是:“我对这个方面根本就了解不多,我怎么知道这个方面那里在研究啊?他们在研究什么啊?万一我想的思路别人已近写出东西了,我再做出来不就发不了文章了?” 现在我就来介绍一个方法可以很好的解决这个问题!! 首先,我们常用的数据库! 常用的数据库有5个。不多介绍,直接上图! 本帖隐藏的内容 第二,创建自己的Google reader 输入网址 : http://reader.google.com/ 进入页面后点击“创建账号”,按要求输入注册信息。点击“我接受;创建我的账号”。进入下一页面。输入自己的手机号(老师告诉我们这是免费的,其实要是有Google的邮箱就可以省去注册账号这一步了)。稍等片刻会有一个短信回复(有时可能要等很久,请耐心,实在不行可以点击“重新发送”。但这要可能会造成验证码验证无效。因为收到的可能是第一个的验证码!这样要等第二个验证码发来再验证!),告诉你验证码。输入验证码点击验证。再进入申请账号所用的邮箱,链接激活。这样你就可以有自己的Google reader了!(要是界面是英文的,可以在账号后面的设置里选择语言,改成中文!) 这是在下的Google reader,先秀一下: 接下来进入正题,解决上面大家最苦恼的两个问题! 问题一:老师只给了一个研究方向和几个关键词,我到哪去找最新的英文文献啊? 先在浏览器地址栏里输入 www.hubmed.org ,在2处输入要找的关键词,点击3。例图如下 接着出现下面的界面,点击红圈标记的地方: 再然后出现下面的界面,复制红圈标记的地址: 回到刚才申请好的Google reader里。点击订阅,把复制的网址黏贴进去,回车就可以了 这样,只要有以你搜索的词为关键词的文献出版或被搜录了,你都可以在自己的Google reader里知道。并可以看到摘要,这样,阅读摘要,选择你喜欢的文章,自己就可以寻找下载地址进行下载了!可以帮你把握自己研究方向最新的文章动态! 问题二:我怎么知道这个方面那里在研究啊?他们在研究什么啊? 这个问题的解决方法,最方便的就是订阅于自己研究方向有关的杂志了!方法如下: 以我个人举例,我要看毒理方面的文章,我先在百度里找到“美国化学学会”。进入“ACS美国化学学会全文数据库”,找到“Chemical Research in Toxicology《毒物学领域的化学研究》”点击进入 进入一个新的页面后,复制网址,回到刚才申请好的Google reader里。点击订阅,把复制的网址黏贴进去,回车就可以了 这样,“Chemical Research in Toxicology《毒物学领域的化学研究》”新一期的一出版,上面所有的文章,我都可以看到摘要和关键词了。对于自己感兴趣的我就可以选择性的下载了! 再说一点,springerlink的链接是进入要看的学科分类后。点击红框部分: 出现新的下载任务: 再复制红框部分网址,回到刚才申请好的Google reader里。点击订阅,把复制的网址黏贴进去,回车就可以了。 对于sciencedirect和acs比较相似。但要现在1处输入要搜索的方向。再在2处点击 出现下图。点击红框; 出现的网站。复制红框的网址。点击订阅,把复制的网址黏贴进去,回车就可以了 其他两个数据库的杂志大家可以自己试一试!我就不废话了!! 最后,其实Google reader上还有编辑、标注、评论、共享.......我就不多废话了。转成中文的大家可以自己探索! 本文来自: 经管之家 天津工程职业技术学院管理科学与工程系 版,详细出处参考: https://bbs.pinggu.org/forum.php?mod=viewthreadtid=2168501page=1fromuid=2752047
-
191 次阅读|0 个评论
-
-
分享
DB2 SQL讲义(一)
-
daydayup81 2013-1-18 22:19
-
DB2是DBMSs的一种,是IBM公司创建的数据管理系统(1974-1983),目前的版本是V10。 数据库中最基本的对象是数据表和视图,它们由不同的列组成,列又称为字段或变量,而行则不同,一行记录必须包含所有字段或变量的值。数据表中的行是经常变化的,而列则不常变化,比较稳定。 数据表中的列有不同的数据类型,一般来说包括三大类: 1. 数值(整数、小数) 2. 字符串(定长、变长) 3. 日期和时间(日期、时间) 这些类的数据之间可以通过转换函数进行转换。 数据库最常用的操作是 select from where。该操作会把满足条件的行选出来。 数据库提供投影操作,也就是说只提取一张表中的某几个变量而非所有变量。 数据库一般也提供所有的集合操作 并、交、差 运算等等。 数据库还提供将两张表的数据进行 笛卡尔乘积 的操作,该操作对于分解业务,提高数据利用性能很有帮助。 数据库可以更新。 执行这些操作的语言称为SQL。可以把SQL写成函数或者过程,执行一系列的操作,比如说分支选择和循环遍历。 有时候为了维护方便,往往将一系列的数据库操作绑在一起,要么不执行,要么一起执行,如果执行到一半出错,数据库会自动退回到未执行前的状态,这个被称为事务transaction。
-
个人分类: DB2 SQL|172 次阅读|0 个评论
-
-
分享
“河南省统计数据库∪重大文件”文库开通了,希望大家多多订阅!
-
dingdatou0303 2013-1-1 18:06
-
“河南省统计数据库∪重大文件”文库开通了,希望大家多多订阅!
-
168 次阅读|0 个评论
-
-
分享
《工程索引》(美国EI核心数据库全文检索)核心期刊
-
chinaei 2012-9-27 16:50
-
《工程索引》(TheEngineeringIndex,简称EI)是美国工程信息公司(EngineeringinformationInc.)出版的著名工程技术类综合性检索工具。收录文献几乎涉及工程技术各个领域。例如:动力、电工、电子、自动控制、矿冶、金属工艺、机械制造、管理、土建、水利、教育工程等。它具有综合性强、资料来源广、地理覆盖面广、报道量大、报道质量高、权威性强等特点。EI录入的文章都代表着权威与高质量。所以EI被称为全球核心,被每个国家认可。一般用作:硕士毕业、博士毕业、评副教授、评正教授、评高级工程师使用。作者在国际会议或者国际杂志上发表论文被EI收录后,国内一些权威机构可以出具EI收录证书给作者。 《工程索引》EiCompendex是全世界最早的工程文摘来源。EiCompendex数据库每年新增的50万条文摘索引信息分别来自5100种工程期刊、会议文集和技术报告。EiCompendex收录的文献涵盖了所有的工程领域,其中大约22%为会议文献,90%的文献语种是英文。Ei公司在1992年开始收录中国期刊。1998年Ei在清华大学图书馆建立了Ei中国镜像站。 EI除作为检索工具外还是国际论文最重要的统计源之一,是对理工科高等院校和工程研究院所学术水平评价的重要依据。作者文章在国际EI核心工程索引中心办理发表,1-9个月内文章会被美国的EI数据库全文收录(全英文版文章),这时作者可以登陆EI数据库检索到自己的文章。当文章已经可以在EI网上检索到的时候,这时为了方便国内作者,国际EI核心工程索引中心委托教育部科技查新站给作者出具认证报告,也就是一份被EI全文收录的索引页与证明,加盖公章。这个就是EI检索证书,具有教育部的官方性质。由国际EI核心工程索引中心免费给作者提供,不收取任何费用。 国际EI核心工程索引中心成立于美国加州,致力于全球学术交流和知识传播,尤其专注于EI论文的发表与检索。本中心在中国香港设立国际会务办公室,服务于东亚地区的EI国际会议的召开与组织,以及专业学术期刊的出版和发行。在中国大陆的EI会议事务办公室设立在文化底蕴深厚的江苏省南京市,该机构拥有出色的工作团队和优质的国际合作伙伴,愿与科研院所及个人开展EI会议论文发表和检索方面的合作,并帮助其进入EI检索(100%检索),大陆地区作者请联系: 投稿信箱: 002@eimeeting.com , 咨询电话: 025-66910093 联系QQ: 1666736703
-
180 次阅读|0 个评论
-
-
分享
数据库
-
随风归来 2012-6-4 09:29
-
中国综合社会调查(CGSS)、 美国综合社会调查(GSS)、 东亚社会调查(EASS)、 国际社会调查协作项目数据库(ISSP)
-
157 次阅读|0 个评论
GMT+8, 2026-5-5 02:28


 标签: 数据库经管大学堂:名校名师名课
标签: 数据库经管大学堂:名校名师名课

 京公网安备 11010802022788号
论坛法律顾问:王进律师
知识产权保护声明
免责及隐私声明
京公网安备 11010802022788号
论坛法律顾问:王进律师
知识产权保护声明
免责及隐私声明

