| 所在主题: | |
| 文件名: gethtml 20140807.zip | |
| 资料下载链接地址: https://bbs.pinggu.org/a-1605218.html | |
本附件包括:
|
|
| 附件大小: | |
|
回帖有奖!
可领3次哦 公司名字在程序同目录下的'公司全名.txt'中,一行一个 这是帮版友写的小程序: 100论坛币求python大神帮忙编一段程序完成从网页中抓取信息 输入: 只用公司名,公司名另存到了txt文件中。一行一个。 时间方面: 时间未考虑小长假及春节,只考虑了周末的情况。 未考虑下班时间。当日查询时终止日期为当日。 当周末查询时,实际查询的是本周四-周五的情况。 周一时,查询的是上周五到周一。 输出: 输出是否中标,同时在脚本所在目录输出中标的公司所有搜索出来的项目名及项目连接。 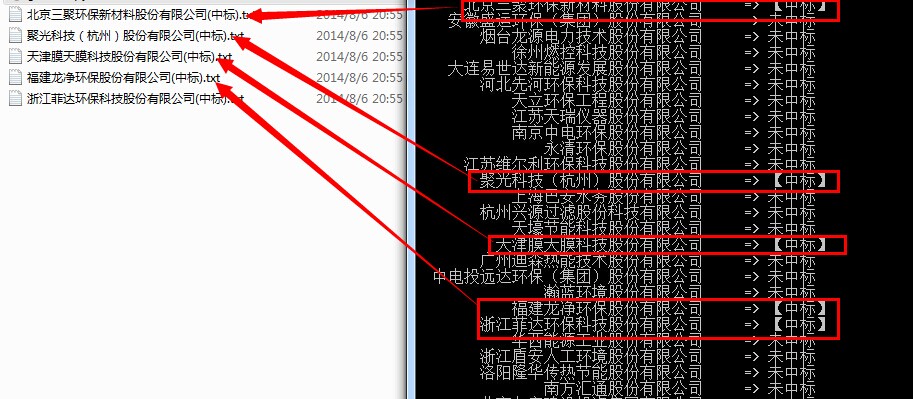 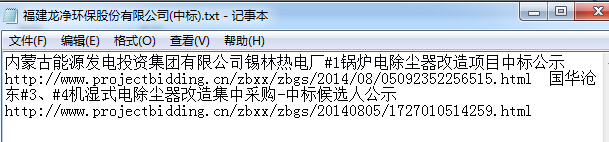 总结: 写这个程序是连谷歌带百度,各种文章中基本都是python2.x的版本,而我的环境是win+python3.4, 做了2to3的修改。 用到的知识: 1、函数及函数调用 2、正则模块,用于检索符合条件超链接及标题;注:python默认正则是贪婪模式(即有多少给出多少,而这正式本程序所需要的),模块:re 3、字符编码,网页是utf-8的编码,在获取之后所有的中文都是”\x45“的样子,要用utf-8的模式解码。其中ignore的作用可以自己搜索下。
带关键字搜索,因为url中涉及了这个关键字,所以分解超链接中关键字即可。 同时,有一点需要注意,url中带有中文,python访问会失败,要做转换:
5、print的功能。模块:sys 默认输出方式的调整,指定到txt中。之后还原为默认。
6、时间模块:time 涉及到:时间的增减,weekday的判断等。 以上即用到的知识点讲解。适合新手。 请高手斧正。 [hide][/hide] |
|
 熟悉论坛请点击新手指南
熟悉论坛请点击新手指南
|
|
| 下载说明 | |
|
1、论坛支持迅雷和网际快车等p2p多线程软件下载,请在上面选择下载通道单击右健下载即可。 2、论坛会定期自动批量更新下载地址,所以请不要浪费时间盗链论坛资源,盗链地址会很快失效。 3、本站为非盈利性质的学术交流网站,鼓励和保护原创作品,拒绝未经版权人许可的上传行为。本站如接到版权人发出的合格侵权通知,将积极的采取必要措施;同时,本站也将在技术手段和能力范围内,履行版权保护的注意义务。 (如有侵权,欢迎举报) |
|

京ICP备16021002号-2 京B2-20170662号
 京公网安备 11010802022788号
论坛法律顾问:王进律师
知识产权保护声明
免责及隐私声明
京公网安备 11010802022788号
论坛法律顾问:王进律师
知识产权保护声明
免责及隐私声明



