


 雷达卡
雷达卡





本篇报告有别于传统的多因子研究,我们并未将重点放在阿尔法因子的挖掘上,而是通过对股票组合的权重优化计算,找到了在市值中性、行业中性、风格因子中性约束下的最优投资组合,以及验证得到的组合权重是否满足了约束条件。
结构化多因子风险模型首先对收益率进行简单的线性分解,分解方程中包含四个组成部分:股票收益率、因子暴露、因子收益率和特质因子收益率。那么,第只股票的线性分解如下所示:
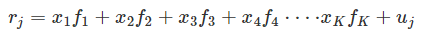
现在我们假设每只股票的特质因子收益率与共同因子收益率不相关,并且每只股票的特质因子收益率也不相关。那么在上述表达式的基础上,可以得到组合的风险结构为:

其中,$r_j$表示第j只股票的收益率;$x_k$表示第j只股票在第k个因子上的暴露(也称因子载荷); $f_k$表示第k个因子的因子收益率(即每单位因子暴露所承载的收益率);$u_j$表示第j只股票的特质因子收益率。因此组合收益率可以表示为:

本文研究使用的大类因子可以参考国泰君安的研报《基于组合优化的风格中性多因子选股策略》。使用到的行业因子为申万一级行业分类的28个行业因子和9大类风格因子。风格因子具体为:Beta、Momentum、Size、Earning Yield、Volatility、Growth、Value、 Leverage、Liquidity。
行业中性和风格中性行业中性是指,多头组合的行业配置与对冲基准的行业配置相一致。行业中性配置的目的在于剔除行业因子对策略收益的影响。与传统观念不同,传统行业配置试图找到在未来某一段时间内强势行业予以超配、弱势行业予以低配,而行业中性的特点在于剔除行业层面的影响,仅考察行业内部个股的超额收益。行业中性策略的净值曲线往往较为平稳,回撤较小。
风格因子中性是指,多头组合的风格因子较之对冲基准的风险暴露为0。风格因子中性的意义在于,将多头组合的风格特征完全与对冲基准相匹配,使得组合的超额收益不来自于某类风格。因为,我们的目的是追求获得稳健的阿尔法收益,而并非市场某种风格的收益。经风格因子中性配置后,策略的净值曲线将会进一步的平滑,最大回撤进一步降低,组合的稳定性较之仅考虑行业中性的配置方式大幅提升。
组合权重优化组合权重优化在多因子模型中起到了至关重要的作用。组合权重优化的目的在于将组合的风险特征完全定量化,使得投资经理可以清楚的了解组合的收益来源和风险暴露。组合权重优化的过程包含2个因素:第一,权重优化的目标函数;第二,约束条件。 其中,约束条件我们在上一节中已经提到,即为组合的行业中性和风格因子中性。对于权重优化的目标函数,有几类不同的方法: 1)最小化组合预期风险

2)最大化经风险调整后收益
最大化经风险调整后的收益为目标函数,同时考虑了预期收益与预期风险的作用,并且在马克维茨的均值方差理论框架下,引入了风险厌恶系数,具体权重优化表达为:

3)最大化组合信息比率
最大化组合信息比率为目标函数以预期收益与预期组合风险的比值作为目标函数,具体权重优化表达为:

上述三种优化目标函数中,第一种方法和第三种方法完全依赖风险模型给定的数据结果进行计算,而第二种最大化经风险调整后的收益为目标函数引入了风险厌恶系数lambda,提高了权重计算的灵活性,使得投资经理可以根据自身的风险偏好进行差异化的选择。
本文复现第二种组合优化方法,暂定假设交易成本TC(w)为0。示意图如下:

研究结果本文重点是如何得到组合的权重,因此没有讲解因子分析、因子验证、策略构建部分。一旦组合权重完成,策略构建也基本完成。本文以2019-01-31这一个调仓日为例,分析出当天如果调仓的组合权重。 我们得到了权重以后进行验证,发现组合满足行业中性的约束:

同时也满足风格中性的约束:

如果我们想使得组合在行业和风格因子上的风险敞口较基准而言有所暴露,我们直接修改约束条件就行,比如我们想在价值因子(Value)上多暴露0.1,结果如下:

可以明显地看到目前组合比基准组合在价值因子上的暴露会直接高出0.2,表明目前的组合超配价值因子,主动选择在该因子上进行风险敞口暴露。
完整代码如下所示:
- import numpy as np
- import pandas as pd
- import numpy as np
- from cvxpy import *
- import datetime
- from sklearn.linear_model import LinearRegression
- start_date = '2015-10-01'
- end_date = '2019-02-01'
- m1 = M.instruments.v2(
- start_date=start_date,
- end_date=end_date,
- market='CN_STOCK_A',
- instrument_list=''
- )
- m7 = M.input_features.v1(
- features="""
- beta_csi500_180_0
- ta_mom_60_0
- log(market_cap_0+0.0001)
- west_eps_ftm_0/close_0
- fs_net_income_0/market_cap_0
- fs_eps_0/close_0
- volatility_240_0
- return_20
- swing_volatility_240_0
- fs_net_profit_qoq_0
- fs_net_profit_yoy_0
- fs_net_profit_0
- west_netprofit_ftm_0
- fs_common_equity_0/market_cap_0
- (fs_non_current_liabilities_0+market_cap_0)/market_cap_0
- fs_total_liability_0/(fs_current_assets_0+fs_non_current_assets_0)
- (fs_common_equity_0+fs_non_current_liabilities_0)/fs_common_equity_0
- turn_0
- """
- )
- m8 = M.general_feature_extractor.v7(
- instruments=m1.data,
- features=m7.data,
- start_date='',
- end_date='',
- before_start_days=0
- )
- m9 = M.derived_feature_extractor.v3(
- input_data=m8.data,
- features=m7.data,
- date_col='date',
- instrument_col='instrument',
- drop_na=False,
- remove_extra_columns=False
- )
-
- # the material we need to build the factors are stored in Material DataFrame
- materials = m9.data.read_df()
- materials = materials.set_index('date')

 京公网安备 11010802022788号
京公网安备 11010802022788号







