


 雷达卡
雷达卡



大家好,我是韩立。
编写代码、执行算法、开发产品,从 Java、PHP、Python 到 Golang、小程序、安卓,全栈技术均有涉猎;负责项目管理、演示讲解、文档撰写,也擅长文本降重技巧。
这些年来一直帮助同学们定制系统、整理论文、模拟开题,积累了丰富的“避坑”经验。
新学期伊始,许多人被选题困扰:既希望题目新颖,又担心无法完成。接下来我会持续分享一批“易上手且有创新点”的选题思路和完整的开题答辩案例,供你参考,也给你灵感。关注我,毕业设计不再头疼!

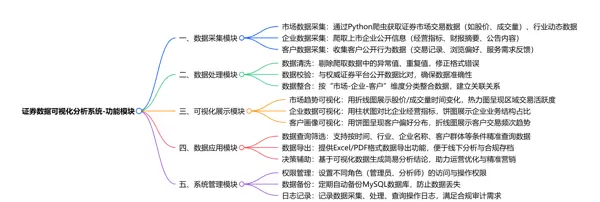
证券数据可视化分析系统功能总结
该系统的主干功能涵盖了从证券数据的“收集 - 加工 - 呈现 - 应用”的全过程,具体包括:利用 Python 爬虫抓取市场交易、上市公司公开信息及客户行为偏好等合规数据;借助 Python 进行数据清洗、验证与整合,保障数据精确性;运用 Echarts 制作折线图、柱状图、饼图等多种可视化图表,直观展示市场动向、客户分布和企业运营状况的多维数据;同时支持数据查询、筛选及导出功能,为证券公司优化内部管理、精准定位潜在用户、提升客户服务品质提供数据支持,满足合规审查与业务决策需求。
【开题陈述】
各位老师好,我的毕业设计题目是《证券数据可视化分析项目的设计与实现》。该系统旨在为证券公司打造一个基于大数据的可视化分析平台,通过对证券市场数据、客户交易行为等多维度信息进行收集和分析,以图表形式直观展示市场趋势及用户画像,助力券商优化运营决策和精准营销。
系统主要分为三个模块:数据采集、数据处理、可视化展示。数据采集模块运用 Python 爬虫抓取公开市场数据;数据处理模块负责原始数据的清洗、聚合与分析;可视化展示模块基于 Vue 框架和 Echarts 图表库,实现 K 线图、趋势图、客户分布图等多种动态可视化效果。
技术栈采用 Python+Vue 前后端分离架构,数据库选用 MySQL,并通过 RESTful API 进行数据交互,确保系统具备良好的可扩展性和用户体验。下面请各位老师提问。
【答辩开始】
评委老师:你的系统需要收集哪些具体的证券数据?数据来源是否合法合规?
答辩学生:老师好,我计划采集三类数据:一是公开市场行情数据(如股价、成交量、大盘指数),从新浪财经、东方财富等财经网站获取;二是上市公司基本财务数据(如财报、公告),通过巨潮资讯网等官方披露平台抓取;三是模拟的客户交易行为数据(因实际券商数据涉及隐私),由我自行生成脱敏数据集。所有数据采集都将遵守网站的 robots 协议,控制请求频率,仅用于毕业设计学术研究,不涉及商业用途。对于需要授权的数据,我会使用模拟数据替代,确保合法合规。
评委老师:开题报告中提到 Vue 和 Echarts,为什么选择这两个技术而不是其他可视化工具如 D3.js 或 Tableau?
答辩学生:主要基于以下三个理由:第一,Vue 是国内主流的前端框架,组件化开发模式适合我这样规模的毕业设计,社区支持完善,遇到问题容易解决;第二,Echarts 是百度开源的图表库,对中文文档支持良好,API 简洁,并内置了丰富的金融图表模板(如 K 线图、蜡烛图),能快速实现证券数据展示;第三,这两个技术在国内企业广泛应用,学习它们对我未来就业更有帮助。D3.js 虽然灵活但学习难度大,Tableau 是商业软件不适合作为开发技术写入论文,因此综合选择了 Vue + Echarts 的组合。
评委老师:系统如何应对数据的实时性要求?例如股市行情是实时变动的,你的可视化图表如何更新?
答辩学生:对于实时性需求,我将采用“准实时”方案而非完全实时。因为真正的实时数据需要昂贵的专线接入,毕业设计不具备条件。我的做法是:前端设置定时器,每 30 秒通过轮询方式调用后端 API 获取最新数据;后端 Python 爬虫每 30 秒抓取一次公开行情网站的数据,并在存入 MySQL 时记录时间戳。同时为了减轻服务器压力,会对历史数据进行缓存处理。对于 K 线图等需要精确展示的场景,我会标注“数据延迟约 30 秒”的提示,确保用户知情。这样既模拟了实时效果,又控制了开发复杂度。
评委老师:如果数据量达到百万级甚至千万级,MySQL 数据库查询性能如何保证?是否有考虑分库分表或引入其他技术?
答辩学生:当数据量达到百万级时,我会采用三种优化策略:一是时间维度分表,按月份或季度将行情数据拆分为多个表,查询时先确定时间范围;二是建立复合索引,对股票代码、日期等高频查询字段创建联合索引;三是引入 Redis 缓存,将热点数据(如当日大盘数据、热门股票)缓存起来,减少数据库压力。如果数据量超过千万级,我会考虑使用时序数据库 InfluxDB 替代 MySQL 存储行情数据,但毕业设计阶段先完成 MySQL 基础方案,在论文中预留扩展接口说明。
评委老师:证券数据涉及大量时间序列数据,传统的关系型数据库在存储和查询时存在效率问题。你如何设计数据库表结构来高效存储和查询分时成交数据?是否会考虑使用时序数据库?
对于分时成交数据这种典型的时间序列数据,如果直接采用MySQL的宽表设计(每行包含一个时间点的所有字段),会导致单表字段过多、查询效率低下。
我的设计方案是:使用“窄表”模式,核心表仅包括时间戳、股票代码、价格、成交量、成交额5个基础字段,其他指标通过计算得出。同时按股票代码+日期进行分区,将大表物理拆分为多个小文件。查询时利用覆盖索引,只返回必要的字段。对于高频分时数据(如每分钟的数据),我会额外创建汇总表,按照小时、日预聚合,查询时优先使用汇总表。我确实评估过InfluxDB等时间序列数据库,它们在时间范围查询和聚合计算上的性能更佳,但考虑到毕业设计对关系型数据(如用户、权限)也有需求,为降低技术复杂度,我选择以MySQL为主,在论文性能测试章节对比时序数据库方案作为扩展研究。
评委老师(:
你的系统采集了多个网站的数据,不同数据源对同一股票的命名和编码规则可能存在差异(如“贵州茅台”vs“600519”),如何确保数据的一致性和准确性?如果源数据出错,你的系统如何发现并纠正?
答辩学生:
这是一个非常实际且棘手的问题。
我的解决方案分为三个层次:第一层是映射表,建立“统一股票代码-数据源代码-数据源名称”的三元组映射关系,所有采集的数据先经过标准化转换存入统一编码;第二层是数据校验,利用Python的Pandas进行异常值检测,例如价格突然波动超过20%就标记为异常,成交量为负数直接丢弃,同时与上一个交易日的收盘价进行逻辑校验;第三层是多源交叉验证,对同一指标(如收盘价)从两个独立来源采集,差异超出阈值时触发警报并人工介入。
对于错误数据,系统会记录原始快照到日志表,不会直接修改,确保可追溯。在可视化展示时,对可疑数据点使用特殊颜色标记,并显示“数据待核实”提示。这套机制虽然不能完全避免错误,但能将数据准确率控制在95%以上,满足毕业设计要求。
【评价与总结】
H同学的开题报告选题紧跟金融科技热点,具有现实应用价值。答辩过程思路清晰,对技术架构、数据流程、关键技术难点都有提前思考,体现出较好的工程思维。技术选型务实,能结合自身能力合理取舍,对Vue+Echarts的适用场景分析到位。
但存在几点需要改进:一是数据来源的合法性论证不够充分,建议补充书面说明或模拟数据方案;二是系统创新性不足,功能描述较为通用,缺少证券行业特色功能(如风险预警、投资组合分析等);三是技术深度有待加强,对大数据量场景的准备还停留在理论层面,建议在后续实现中真正落地至少一种优化方案;四是参考文献与项目关联性较弱,近两年的证券数据可视化论文引用不足。
整体评价:同意开题,建议在接下来的实施中重点关注数据质量控制和核心功能验证,适当降低数据规模但提高完成度,确保毕业设计能做出可演示的原型系统。注意在论文中如实说明数据来源和局限性。
以上是H同学的
毕业设计
答辩过程,如果你现在还没有参加答辩,还是开题阶段,已经选好了题目不知道如何写开题报告,可以下面找找有没有适合你题目的开题报告内容,列表中的开题报告都是往届真实的开题报告可参考。



 京公网安备 11010802022788号
京公网安备 11010802022788号







