


 雷达卡
雷达卡



链家网二手房数据爬虫项目分享
1 写在前面
大家好!今天给同学们分享一个实用的项目——《链家网二手房数据爬虫》。这个项目基于Python语言的lxml库,通过XPath路径解析获取数据,并结合多线程并发抓取,对速度和异常处理都做了很好的优化。
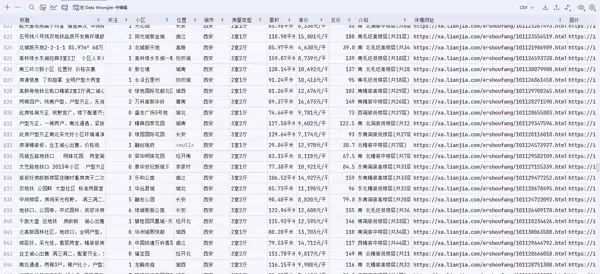
数据抓取字段包括:‘标题’, ‘关注’, ‘小区’, ‘位置’, ‘城市’, ‘房屋类型’, ‘面积’, ‘单价’, ‘总价’, ‘介绍’, ‘详情网址’, ‘图片’。我提供了两种数据存储方式:CSV文件保存和MySQL数据库保存。代码中已添加详细注释,方便同学们理解。
项目主要涉及的技术模块:requests、pandas、lxml、threading、csv。
PS:代码以西安市为例,同学们只需修改关键字即可抓取指定城市的数据!
2 目标网站分析

本次抓取的是链家网的二手房房源数据。通过分析网页结构,我们可以采集以下字段:‘标题’, ‘关注’, ‘小区’, ‘位置’, ‘城市’, ‘房屋类型’, ‘面积’, ‘单价’, ‘总价’, ‘介绍’, ‘详情网址’, ‘封面图片’。
2.1 网页结构分析
打开开发者工具(F12或右键检查),可以发现房源信息位于
ullili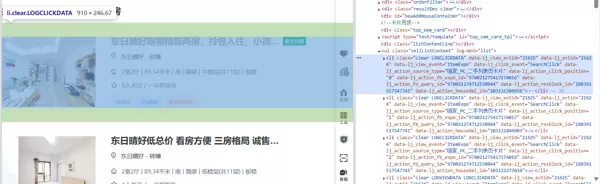
2.2 获取房源标题
房源标题位于
a先获取所有房源列表:
li_List = tree.xpath("//*[@class='sellListContent']/li")在相对位置获取标题:
title = li.xpath('./div/div/a/text()')[0]
2.3 获取图片URL
图片URL位于
imgdata-originalli.xpath('./a/img/@data-original')[0]
2.4 反爬虫处理
链家网在抓取超过5个页面(约150条数据)后会触发反爬机制。解决方案有多种,可以使用Selenium库进行自动化测试,也可以直接使用Cookie绕过。

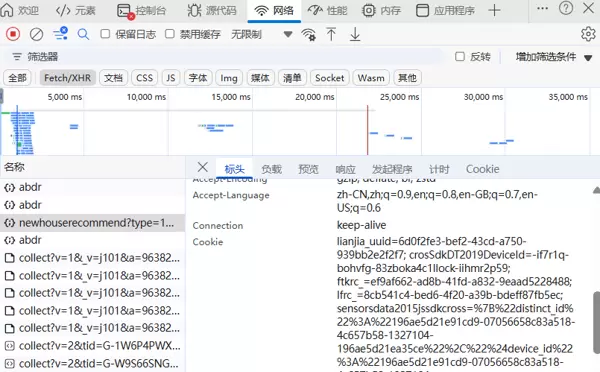
2.5 获取Cookie的方法
在开发者工具中选择"网络(Network)"选项卡 筛选XHR请求 找到相关请求并复制Cookie值
3 完整代码实现
import requests
import threading
import pandas as pd
from lxml import etree
import csv
from datetime import datetime
import pymysql
# 数据库连接配置
cnx = pymysql.connect(
host="localhost",
user="root",
password="123456",
database="secondhouse_xian"
)
cursor = cnx.cursor()
# 全局变量
count = [] # 全部信息列表
city = '西安' # 目标城市
filename = f'{city}.csv' # CSV文件名(带时间戳)
# 生成1-10页URL
def url_creat():
url = 'https://xa.lianjia.com/ershoufang/pg{}/'
return [url.format(i) for i in range(1, 51)]
# CSV存储函数
def save_to_csv(data):
# 定义CSV表头
headers = ['标题', '关注', '小区', '位置', '城市', '房屋类型', '面积', '单价', '总价', '介绍', '详情网址', '图片']
# 首次写入时创建文件并写入表头
with open(filename, 'a', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=headers)
if f.tell() == 0:
writer.writeheader()
writer.writerow(data)
# 页面解析函数
def url_parse(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0',
'Cookie': 'lianjia_uuid=6d0f2fe3-bef2-43cd-a750-939bb2e2f2f7; select_city=330100; lianjia_ssid=1807dc6c-353e-4e7c-a4a6-caaae625f69d; '
}
crosSdkDT2019DeviceId=-if7r1q-bohvfg-83zboka4c1llock-iihmr2p59; login_ucid=2000000456398621;
lianjia_token=2.00142d0bba43fa714b0580228b73f70576; lianjia_token_secure=2.00142d0bba43fa714b0580228b73f70576;
security_ticket=UgAs85ty1j+KdeDNa49PrErJN6hc68OmqtitvxeskqSNS6hdJJ2PBLT0Bh62YyMhnstpwUB/x7a3/9fvfcAjhPMF8c1id9nGUCwZ1GgRxjwWsijqvaEobK0A2AHw6QdsLDuHKa9YmDuzfWDIjmgE7QDLVHyv81Ff4eM9apx1eV4=;
ftkrc_=ef9af662-ad8b-41fd-a832-9eaad5228488; lfrc_=8cb541c4-bed6-4f20-a39b-bdeff87fb5ec;
Hm_lvt_46bf127ac9b856df503ec2dbf942b67e=1746682060; HMACCOUNT=36F711E17DDBF3F9;
_qzjc=1; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiZDY2ODNiZTlmMjJlMDUxMDA2ZDU4NTg2NjJlOTA2NjY5MzU3Zjc5ODRlYjFiNWJiOWI2NDFmYjMyOTBkYTc2ZmY0MzdlNzNmNzNkZDlmYWU1Mjk1ZThkN2UzZmNkMGQ1MTkyYmIyNTI4YzY1NjNmYzNjMGJkOTA2ZWNkYzBmZGJlOGYxM2NkODA5MWQ1YjZlZWJlZjQ2ZWMzMjgwZmMxNDUwMjIyNDA4NjA4YjU2MzliYmYyMDkwNGI4NmIyODMzNTg0ZWYwYzAyYzVlZjQzMzQ5YTQ4NjM0N2Y0YmIxM2VmNTVlOGUzNDU0NWQ2NTc3NDY5MmUzMTMxODAwNDcyOFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCJjMzU0MWE0OVwifSIsInIiOiJodHRwczovL2h6LmxpYW5qaWEuY29tL2Vyc2hvdWZhbmcvcGcxLyIsIm9zIjoid2ViIiwidiI6IjAuMSJ9; _jzqa=1.3628376045562550000.1746682061.1746682061.1746682061.1;
_jzqc=1; _jzqx=1.1746682061.1746682061.1.jzqsr=clogin%2Elianjia%2Ecom|jzqct=/.-; _jzqckmp=1; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22196ae5d21e91cd9-07056658c83a518-4c657b58-1327104-196ae5d21ea35ce%22%2C%22%24device_id%22%3A%22196ae5d21e91cd9-07056658c83a518-4c657b58-1327104-196ae5d21ea35ce%22%2C%22props%22%3A%7B%7D%7D; _ga=GA1.2.1014061828.1746682072;
_gid=GA1.2.288150949.1746682072; _gat=1; _gat_past=1; _gat_global=1; _gat_new_global=1; _gat_dianpu_agent=1;
_ga_W9S66SNGYB=GS2.2.s1746682072$o1$g0$t1746682072$j0$l0$h0; _ga_1W6P4PWXJV=GS2.2.s1746682072$o1$g0$t1746682072$j0$l0$h0;
_qzja=1.1120861123.1746682060329.1746682060329.1746682060329.1746682060329.1746682085924.0.0.0.2.1; _qzjb=1.1746682060329.2.0.0.0;
_qzjto=2.1.0; _jzqb=1.2.10.1746682061.1; Hm_lpvt_46bf127ac9b856df503ec2dbf942b67e=1746682086
}
尝试:
response = requests.get(url=url, headers=headers, timeout=10)
response.encoding = 'utf-8'
tree = etree.HTML(response.text)
li_List = tree.xpath("//*[@class='sellListContent']/li")
lock = threading.RLock()
with lock:
for li in li_List:
# 数据提取
title = li.xpath('./div/div/a/text()')[0]
link = li.xpath('./div/div/a/@href')[0]
attention = li.xpath('./div/div/text()')[0].split('人')[0]
# 位置信息
position = li.xpath('./div/div[2]/div/a/text()')[0] + li.xpath('./div/div[2]/div/a[2]/text()')[0]
# 房屋类型
types = li.xpath('./div/div[3]/div/text()')[0].split(' | ')[0]
# 面积信息
area = li.xpath('./div/div[3]/div/text()')[0].split(' | ')[1]
# 房屋详情
info = li.xpath('./div/div[3]/div/text()')[0].split(' | ')[2:-1]
info = ''.join(info)
# 总价信息
total_price = li.xpath('.//div/div[6]/div/span/text()')[0]
# 单价信息
unit_price = li.xpath('.//div/div[6]/div[2]/span/text()')[0]
# 图片链接
pic_link = li.xpath('./a/img/@data-original')[0]
dic = {
'标题': title,
'关注': attention,
'小区': position.split(' ')[0],
'位置': position.split(' ')[1],
'城市': city,
'房屋类型': types,
'面积': area,
"单价": unit_price,
'总价': total_price,
'介绍': info,
"详情网址": link,
'图片': pic_link
}
print(dic)
# 实时保存到CSV文件
save_to_csv(dic)
count.append(dic)
异常处理 Exception as e:
print(f"处理 {url} 时出现错误: {str(e)}")
# 主运行函数
def run():
links = url_creat()
threads = []
# 创建并启动线程
for url in links:
t = threading.Thread(target=url_parse, args=(url,))
threads.append(t)
t.start()
# 等待所有线程完成
for t in threads:
t.join()
# 可选:将所有数据再次保存为完整CSV文件(防止漏存)
pd.DataFrame(count).to_csv(filename, index=False, encoding='utf-8-sig')
print(f"数据已保存至 {filename},共爬取 {len(count)} 条记录")
# CSV数据导入MySQL数据库
def csv_to_mysql_simple(csv_file):
"""极简版CSV数据入库”””
with open(csv_file, 'r', encoding='utf-8-sig') as f:
reader = csv.DictReader(f)
# 批量插入SQL模板
sql = """INSERT INTO House(title, attention, community, location, city, house_type, area, unit_price, total_price, description, detail_url, image_url)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""
# 遍历每一行数据
for row in reader:
try:
cursor.execute(sql, (
row['标题'],
int(row['关注']), # 转换为整数
row['小区'],
row['位置'],
row['城市'],
row['房屋类型'],
row['面积'],
row['单价'],
row['总价'],
row['介绍'],
row['详情网址'],
row['图片']
))
cnx.commit() # 提交事务
except Exception as e:
print(f"插入失败: {row['标题']},错误原因: {str(e)}")
cnx.rollback() # 回滚当前事务
print("数据导入完成!")
if __name__ == '__main__':
run() # 注释该行会将爬取的CSV文件仅存储在MySQL数据库中
csv_to_mysql_simple('西安.csv') # 注释该行会仅执行爬取数据到CSV文件的操作

 项目总结
这个链家网二手房数据抓虫项目展示了如何利用Python进行网页数据采集,包括:
使用requests库发送HTTP请求
使用lxml和xpath解析页面内容
采用多线程提升抓取效率
处理反爬机制(通过Cookie)
将数据存储到CSV文件和MySQL数据库中
同学们可以根据自身需求修改代码,例如更改目标城市、调整抓取字段或优化存储方式。希望这个项目对大家学习网络爬虫有所帮助!
如有任何疑问,欢迎在评论区留言讨论。
项目总结
这个链家网二手房数据抓虫项目展示了如何利用Python进行网页数据采集,包括:
使用requests库发送HTTP请求
使用lxml和xpath解析页面内容
采用多线程提升抓取效率
处理反爬机制(通过Cookie)
将数据存储到CSV文件和MySQL数据库中
同学们可以根据自身需求修改代码,例如更改目标城市、调整抓取字段或优化存储方式。希望这个项目对大家学习网络爬虫有所帮助!
如有任何疑问,欢迎在评论区留言讨论。

 京公网安备 11010802022788号
京公网安备 11010802022788号







