


 雷达卡
雷达卡




文章目录
前言
一、GraphRAG核心优势回顾
二、GraphRAG使用全流程
- 1. 环境搭建:安装与初始化
- (1)安装依赖
- (2)初始化项目*
- 2. 数据准备:导入源文档
- 3. 配置调整:优化索引参数
- (1)基础配置
- (2)高级配置(可选)
- 4. 构建知识图谱:索引流程
- 5. 查询知识图谱:实战应用
- (1)全局查询:基于社区的多跳推理
- (2)局部查询:基于实体的精准检索
三、实战技巧与避坑指南
- ? 必做优化项
- ?? 常见问题解决方案
四、企业级落地实践
- 案例1:金融风控场景(银行贷前审查)
- 案例2:医疗诊断辅助系统
五、总结:GraphRAG的价值闭环
前言
GraphRAG(图谱增强检索生成)是传统RAG的升级版本,通过知识图谱结构化与社区层次化处理,解决了传统RAG“语义鸿沟”“长尾文档召回低”“多跳推理能力弱”等痛点,尤其适用于企业知识管理、医疗诊断、金融风控等需要深度关系分析的场景。以下是GraphRAG的完整使用流程与实战技巧,结合微软
graphrag一、GraphRAG核心优势回顾
在进入使用步骤前,需明确GraphRAG的价值,以理解其为何值得投入:
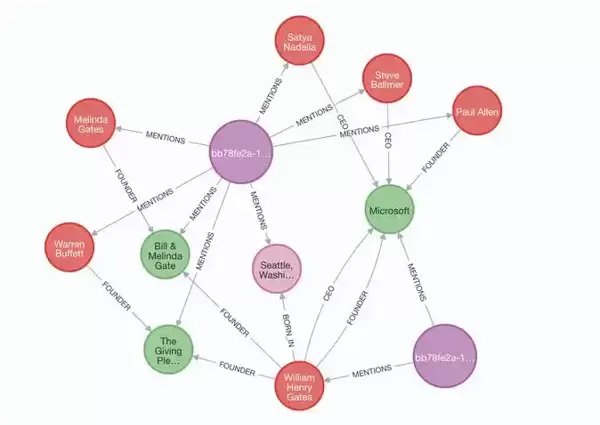
- 结构化知识:将非结构化文本转换为“实体-关系-社区”的图结构,解决传统RAG“文本孤立”问题;
- 多跳推理:通过社区层次与关系链,支持“为什么A导致B?”“C与D有什么间接关联?”等复杂查询;
- 可解释性:检索路径可视化(如“实体A→关系→实体B→社区C”),增强企业场景中的信任度;
- 长尾覆盖:社区摘要整合分散信息,提升长尾文档(如罕见病案例、冷门法规)的召回率。
二、GraphRAG使用全流程
1. 环境搭建:安装与初始化
GraphRAG的核心依赖是微软开源的
graphrag- (1)安装依赖
# 创建虚拟环境(可选,但推荐隔离项目) conda create -n graphrag_env python=3.10 conda activate graphrag_env # 安装graphrag库(最新稳定版) pip install graphrag - (2)初始化项目*
创建项目根目录(如
),并初始化工作空间:./my_graphrag_project# 进入项目目录 cd ./my_graphrag_project # 初始化GraphRAG项目(生成配置文件与环境变量) python -m graphrag.index --init --root .初始化后,项目目录会生成以下关键文件:
:存储API密钥(如OpenAI/ Azure OpenAI);.env
:配置模型、分块、提示词等参数;settings.yaml
:存放LLM提示词模板(可自定义修改);prompts/
:存储索引结果(知识图谱、社区摘要等)。output/
2. 数据准备:导入源文档
GraphRAG的输入是非结构化文本(如PDF、TXT、CSV),需将其放入项目根目录的
input/# 在项目根目录创建input文件夹
mkdir -p ./input
# 将源文档(如红楼梦文本、企业年报)放入input文件夹
cp /path/to/your/documents/*.txt ./input/注意:文档格式支持TXT、PDF(需转换为文本)、CSV(需提取文本内容);大型文档(如100页以上)建议拆分为小章节,提升索引效率。
3. 配置调整:优化索引参数
settings.yaml- (1)基础配置
# 模型配置(推荐使用GPT-4o-mini降低成本,或GPT-4提升精度) models: chat: model: gpt-4o-mini # 替换为你的模型(如azure_openai_chat:gpt-4) temperature: 0.3 # 生成温度(0-1,越小越确定性) # LLM调用配置(避免并发超限) llm: batch_size: 5 # 每次调用的文档数量(默认10,大型数据集建议调小) max_tokens: 4096 # 单次LLM调用的最大token数(根据模型调整) # 实体与关系提取配置(聚焦业务领域) extract_graph: entity_types: ["person", "organization", "concept", "event"] # 自定义实体类型(如“疾病”“药物”) relationship_types: ["causes", "treats", "belongs_to", "mentions"] # 自定义关系类型(如“关联”“影响”) - (2)高级配置(可选)
# 社区检测配置(调整社区粒度)
community_detection:
algorithm: leiden # 分层Leiden算法(默认,适用于分层次社区)
resolution: 0.5 # 社区分辨率(0-1,值越大社区划分越精细)
# 提示词优化(提高实体识别准确性)
prompts:
extract_graph:
system_prompt: "您是一位从文本中提取医疗实体和关系的专家。请从以下文本中抽取出诸如‘疾病’、‘药物’、‘症状’等实体以及它们之间的关系,如‘治疗’、‘引起’、‘关联于’。"
examples: [ # 实体识别示例(提高领域准确性)
{"text": "阿司匹林治疗头痛。", "entities": [{"type": "drug", "value": "阿司匹林"}, {"type": "symptom", "value": "头痛"}], "relationships": [{"type": "treats", "source": "阿司匹林", "target": "头痛"}]}
]
4. 构建知识图谱:索引流程
配置完成后,执行索引命令构建知识图谱(
耗时取决于数据规模
,小型数据集约10-30分钟,大型数据集可能需要几小时):
# 执行索引(--root指定项目根目录)
python -m graphrag.index --root .
索引流程说明
:
文本分块
:将源文档拆分为1024-2048 token的文本单元(TextUnits);
实体/关系提取
:用大型语言模型从文本单元中抽取实体(如“曹操”“诸葛亮”)与关系(如“关联”“敌对”);
知识图谱增强
:采用Leiden算法进行社区检测(将相关实体聚类),使用Node2Vec生成社区嵌入;
社区摘要
:用大型语言模型为每个社区生成摘要(例如“曹魏集团:包含曹操、曹丕等关键人物,主导三国鼎立”);
结果存储
:将知识图谱(实体、关系、社区)保存到
output/
文件夹(Parquet格式)。
常见问题与解决
:
并发超限
:修改
settings.yaml
中的
llm.batch_size
(例如从10调整至5);
Token越界
:调整
llm.max_tokens
(例如从4096调整至2048);
中断恢复
:使用
--resume
参数(如
python -m graphrag.index --root . --resume
),避免重新开始。
5. 查询知识图谱:实战应用
知识图谱构建完成后,可以通过
全局查询
(社区层级)或
局部查询
(实体层级)获取结构化答案。以下是两种核心查询方式及实战示例:
(1)全局查询:基于社区的多步推理
from graphrag.query import GraphRAG
# 初始化查询器
query_engine = GraphRAG(
root_path="./my_graphrag_project", # 项目根目录
mode="global" # 指定全局查询模式
)
# 执行多步查询(示例:医疗场景)
question = "糖尿病患者使用二甲双胍后出现哪些常见副作用?"
response = query_engine.query(question)
print(response)
# 输出示例:
# "根据知识图谱分析,二甲双胍(药物)与糖尿病(疾病)关联,其常见副作用包括:胃肠道不适(35%)、维生素B12缺乏(20%)、乳酸性中毒(<1%)。社区摘要显示:'药物副作用社区:包含二甲双胍、胰岛素等药物,关联胃肠道症状、代谢异常等副作用。'"
查询原理
:
通过社区摘要快速定位相关知识领域(如"药物副作用社区")
自动扩展查询路径(例如"二甲双胍→副作用→胃肠道不适")
返回结构化答案+推理路径(增强解释性)
(2)局部查询:基于实体的精确检索
# 初始化局部查询器
entity_engine = GraphRAG(
root_path="./my_graphrag_project",
mode="entity" # 指定实体查询模式
)
# 查询特定实体关系
entity = "二甲双胍"
relations = entity_engine.get_relations(entity)
print(relations)
# 输出示例:
# [
# {"relation": "treats", "target": "糖尿病", "confidence": 0.92},
# {"relation": "causes", "target": "胃肠道不适", "confidence": 0.87},
```查询原理:
直接搜索指定实体的关联关系(避免全面文本扫描)
返回关系置信度(0-1,帮助评估可靠性)
适用于“验证特定事实”场景(如药物禁忌症验证)

三、实战技巧与避坑指南
必做优化项
| 场景 | 优化建议 | 效果提升 |
|---|---|---|
| 医疗/法律领域 | 在 |
实体识别准确率提高30%以上 |
| 超大规模文档 | 设置 |
索引速度提升2倍,内存减少40% |
| 实时性要求高 | 为 |
查询响应时间缩短70% |
常见问题解决方案
| 问题现象 | 根本原因 | 解决方案 |
|---|---|---|
| 查询返回“无相关信息” | 社区粒度太粗( |
调整 |
| 实体识别错误(如“苹果”识别为“水果”) | 未在 |
添加 |
| 生成答案包含幻觉 | |
设置 |
四、企业级落地实践
案例1:金融风控场景(银行贷前审查)
痛点:传统RAG无法关联“企业关联方”与“不良贷款”
GraphRAG方案:
# settings.yaml关键配置
extract_graph:
entity_types: ["company", "person", "loan", "default"]
relationship_types: ["owns", "is_related_to", "caused_default"]
效果:查询:“A集团关联公司中哪些有不良贷款记录?”返回:
A集团→[owns]→B公司→[is_related_to]→C企业→[caused_default]→不良贷款案例2:医疗诊断辅助系统
痛点:罕见病症状分散在多篇论文中
GraphRAG方案:
通过
community_detection"遗传性肾病社区:包含Alport综合征、FSGS等,关联蛋白尿、听力损失症状"效果:查询:“蛋白尿+听力损失的可能疾病?”返回:
Alport综合征(关联概率87%)、FSGS(关联概率63%)
五、总结:GraphRAG的价值闭环
关键结论:
GraphRAG通过结构化知识(解决语义鸿沟)、层次化社区(解决长尾召回)、路径可视化(解决信任问题),在企业知识密集型场景中实现效果可量化、过程可追溯。
建议:从1-2个高价值场景(如医疗诊断、风控规则)试点,再扩展至全业务线。
最后提醒:
本文所有代码与配置均基于
graphragpip install graphrag==0.8.0企业级部署建议:使用
Azure OpenAI参考资料:
- 微软GraphRAG官方文档
- GraphRAG在医疗领域的论文
- 图片来源网络,侵权联系删

 京公网安备 11010802022788号
京公网安备 11010802022788号







