


 雷达卡
雷达卡



【AI应用探索】-12- GraphRAG+MCP的智能体Agent开发
1 GraphRAG是什么?
2 使用GraphRAG
2.1 配置环境
2.2 修改配置
2.3 使用查询引擎
3 封装成MCP的server服务
3.1 导入依赖与服务初始化
3.2 全局配置
3.3 定义搜索基类 GraphRAGSearchBase
3.4 实现本地搜索和全局搜索类
3.5 定义MCP工具
3.6 编写测试和启动入口
4 客户端集成Agent
4.1 客户端代码详解
4.1.1 初始化与连接
4.1.2 核心Agent逻辑 (process_query)
4.1.3 交互与启动
4.2 运行结果与分析
1 GraphRAG是什么?
GraphRAG 是微软研究室推出的一个开放源码项目,全称为“Graph Retrieval-Augmented Generation”(图检索增强生成)。它借助知识图谱来提升大型语言模型(LLM)的问答效能,目标是在复杂信息和大量数据中提供更为深入和有洞见的回答。
传统的 RAG(检索增强生成)通常从文档片段中提取信息,而 GraphRAG 的主要理念是,首先将原始文本数据(例如文档、报告等)转化为一个结构化的知识图谱。此图谱中的节点表示实体(如人物、地点、事件),边则表示它们之间的关联。
当用户提问时,GraphRAG 并不仅仅是进行关键词匹配,而是:
- 理解问题: 分析问题中包含的实体和关联。
- 图谱检索: 在知识图谱中查找与问题相关的实体、关联及其所在社群(即高度相关的子图)。
- 信息综合: 提炼和汇总从图谱中检索到的结构化信息,生成一个或多个更易理解的概要。
- 生成答案: 将这些概要作为丰富的背景资料,提供给大型语言模型(LLM),从而产生一个比传统RAG更全面、更精确、更有深度的答案。
通过这种方法,GraphRAG 能够更有效地揭示数据中隐含的模式、联系和因果关系,特别适合处理那些需要整合多部分信息才能解答的复杂问题。
2 使用GraphRAG
2.1 配置环境
访问GraphRAG的GitHub页面:
GraphRAG
首先,创建一个新的conda环境并激活。
conda create --name graphrag python=3.11
conda activate graphrag
pip install graphrag安装完成后,在你的工作目录中创建一个名为
christmas的文件夹,并下载示例数据文件。这里我们使用古登堡计划中的一部作品作为示例。
mkdir christmas\input
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt -o christmas\input\book.txt但由于该文件较大,生成索引时会消耗较多token,这里简化使用《红楼梦》替代。将以下内容输入到book.txt中
《红楼梦》四大家族及关键人物事件
第一部分:四大家族简介及概述
《红楼梦》以贾、史、王、薛四大家族的兴衰为背景,描绘了中国封建社会末期广阔的社会生活画卷。这四大家族彼此联姻,关系盘根错节,构成了一个庞大而复杂的社会网络,正所谓“一损俱损,一荣俱荣”。
四大家族均为金陵显贵,权势显赫。他们之间通过婚姻和血缘关系紧密相连:贾母出自史家;王夫?及其胞妹薛姨妈出自王家,王夫人嫁入贾府,薛姨妈嫁入薛家;王熙凤亦出自王家,嫁给贾琏。这种盘根错节的姻亲关系,使得他们在政治、经济上相互扶持,形成了一个强大的利益共同体。
第二部分:各大家族与关键人物介绍
贾家
贾家是《红楼梦》中着墨最多的家族,分为宁国府和荣国府两支,是开国元勋之后,世袭国公爵位。小说主要围绕荣国府展开。
贾母(史太君): 出身于史家,是荣国公贾代善的妻子,贾赦和贾政的母亲。她是贾府的最高权威,慈爱而有威严,对孙辈尤其是贾宝玉疼爱有加。她的决策在很大程度上影响着贾府的命运。
贾政: 贾母的次子,荣国府的实际当家人之一。他为人端方正直,但思想僵化,是封建礼教的坚定维护者。
贾赦: 贾母的长子,承袭了荣国公的爵位,但品行不端,贪婪好色。
王夫人: 贾政的妻子,出身于王家,是贾宝玉、贾元春的母亲。她表面上温和贤良,实则性情固执,是“金玉良缘”的支持者。
贾宝玉: 荣国府的嫡派子孙,是小说的核心人物。他生性聪慧,却厌恶封建礼教,蔑视功名利禄,与林黛玉的爱情悲剧是全书的主线。
林黛玉: 贾母的外孙女,贾敏的女儿。她才华横溢,品行高洁,但体弱多病,与贾宝玉心心相印,是“木石前盟”的代表。
王熙凤: 贾琏的妻子,王夫人的侄女。她精明能干,手腕高强,是荣国府的实际掌权者之一,以其泼辣狠毒和聚敛财富而著称。
贾元春: 贾政与王夫人的长女,贾宝玉的姐姐,入宫为妃,地位显赫,是贾府荣耀的象征。
贾探春、贾迎春、贾惜春: 贾府的三位小姐,她们各自有着不同的性格和命运,共同构成了贵族女性的群像。
史家
史家是尚书令史公的后裔,同样是世袭侯爵的大家族,分为忠靖侯和保龄侯两支。虽然在书中的直接描写不多,但其地位和影响力不容小觑。
史湘云: 贾母的侄孙女,是史家的代表人物。她心直口快,开朗豪爽,才情出众,与贾宝玉等人关系密切,是金陵十二钗之一。
王家
王家是都太尉统制县伯王公之后,权势显赫。王家的代表人物主要通过嫁入贾府的女性来体现。
王夫人: 详见贾家部分介绍。
王熙凤: 详见贾家部分介绍。
王子腾: 王夫人和薛姨妈的哥哥,手握军权,是王家权势的代表人物。
薛家
薛家祖上为紫薇舍人,是皇商,家财万贯,有“珍珠如土金如铁”之说。薛家虽富,但在政治地位上不及其他三家,因此寻求与贾家的联姻以获得庇护。
薛姨妈: 王夫人的妹妹,薛宝钗和薛蟠的母亲。她为人慈爱,但对儿子薛蟠过分溺爱。
薛宝钗: 薛姨妈的女儿,美丽端庄,才情出众,是“金玉良缘”的另一位主角。她为人处世圆滑周到,符合封建礼教的规范。
薛蟠: 薛宝钗的哥哥,绰号“呆霸王”。他性情奢侈,言语傲慢,倚财仗势,是典型的纨绔子弟。
第三部分:关键互动事件描述
事件一:林黛玉进贾府
林黛玉因母亲贾敏去世,在外祖母贾母的安排下,从扬州初次来到荣国府。她步步留心,时时在意,生怕被人耻笑了去。在拜见贾母时,祖孙二人相拥而泣,场面感人至深,体现了贾母对女儿的思念和对外孙女的疼爱。随后,黛玉与贾府众人一一见面。与王夫人见面时,王夫人言语间虽客气,却也透露出对黛玉体弱的关切和一丝疏离。最重要的一幕是与贾宝玉的初见,二人一见面都感觉对方似曾相识。宝玉见黛玉没有像他一样的“通灵宝玉”,竟当场摔玉,认为“人无我有,大非奇事”,表现出他对黛玉的特殊看待和天生的亲近感,也预示了二人精神上的高度契合。这一事件奠定了黛玉在贾府的特殊地位,也开启了宝黛爱情故事的序幕。
事件二:宝钗扑蝶
一日,薛宝钗为寻找林黛玉,无意间走到滴翠亭。在亭外,她看到一双美丽的玉色蝴蝶,便玩心大起,拿出扇子追扑蝴蝶。这个情节生动地展现了宝钗作为少女活泼、天真的一面,与她平时端庄稳重的形象形成对比。然而,当她追至滴翠亭附近,无意中听到了丫鬟小红和坠儿关于私情和传递手帕的秘密谈话。为避免自己偷听的嫌疑,宝钗急中生智,故意大声说话,嫁祸于正在寻找她的林黛玉,说“我才看见林姑娘在这里蹲着弄水儿呢”。这一“金蝉脱壳”之计,既保护了自己,又巧妙地将黛玉置于一个尴尬的位置,深刻地揭示了宝钗在天真外表下,深谙世故、善于保护自己、城府颇深的一面。
事件三:元春省亲
贾元春被封为贤德妃后,得到皇帝恩准,回贾府省亲。这是贾府最鼎盛、最荣耀的时刻。为了迎接贵妃,贾府专门修建了奢华无比的大观园。省亲当日,仪仗浩大,场面辉煌。然而,在这荣耀的背后,却是元春与家人无法自由相见的痛苦。元春见到贾母、王夫人等人,忍不住泪流满面,说出“当日既送我到那不得见人的去处”的悲语,道尽了深宫生活的辛酸和对亲情的渴望。她虽为贵妃,却失去了普通人的天伦之乐。在与宝玉、黛玉等姊妹相聚时,她称赞了大观园的景致和众人的才华,并亲自命宝玉、黛玉等人题咏。这次省亲,是贾府权势的顶峰,也是其由盛转衰的重大转折点。它既展现了家族的无上荣光,也暴露了家族内部以及元春个人身处高位却充满悲剧性的命运。
事件四:王熙凤协理宁国府
宁国府的当家主母秦可卿去世,其葬礼事务繁重且混乱不堪。丈夫贾珍悲痛过度,无法主事。荣国府的王熙凤受贾珍所托,前来宁国府协助管理丧事。面对宁国府“无头绪,无章法”的混乱局面,王熙凤展现了她雷厉风行、杀伐决断的管理才能。她首先明确规矩,宣布“宁国府如今的主子就是我”,然后通过“点卯”清查下人迟到早退的现象,并拿一个迟到的下人“开刀”,当众严惩,起到了“杀鸡儆猴”的效果。在她的铁腕管理下,宁国府的各项事务变得井井有条,人人畏服。这一事件充分展示了王熙凤出色的组织能力、权术手腕和狠辣的性格,是她个人能力的高光时刻,也反映了封建大家族内部管理的复杂性和严酷性。准备好数据后,使用 GraphRAG 的命令行工具初始化项目。
graphrag init --root .\christmas执行该命令后,GraphRAG 会在 .\christmas 目录下创建 .env 和 settings.yaml 两个核心配置文件。
2.2 修改配置
执行初始化后,打开 .\christmas 文件夹下的 .env 文件,填写你的大型语言模型API密钥。
配置好 API 密钥后,还需根据所使用的模型调整 settings.yaml 文件。这里以使用阿里云的Qwen(通义千问)模型为例,需要修改 api_base、model 等参数。
models:
default_chat_model:
type: chat
model_provider: openai
auth_type: api_key # 或 azure_managed_identity
api_key: ${GRAPHRAG_API_KEY} # 在生成的 .env 文件中设置此值,或在使用托管身份时删除
model: qwen-plus
api_base: https://dashscope.aliyuncs.com/compatible-mode/v1
# api_version: 2024-05-01-preview
model_supports_json: true # 如果你的模型支持此功能,建议启用
concurrent_requests: 25
async_mode: threaded # 或 asyncio
retry_strategy: exponential_backoff
max_retries: 10
tokens_per_minute: null
requests_per_minute: null
default_embedding_model:
type: embedding
model_provider: openai
auth_type: api_key
api_key: ${GRAPHRAG_API_KEY}
model: text-embedding-v2
api_base: https://dashscope.aliyuncs.com/compatible-mode/v1
# api_version: 2024-05-01-preview
concurrent_requests: 25
async_mode: threaded # or asyncio
retry_strategy: exponential_backoff
max_retries: 10
tokens_per_minute: null
requests_per_minute: null
配置完成之后,执行以下命令来处理数据、提取实体和关系,并最终构建知识图谱。
graphrag index --root .\christmas
这个流程会花费一定的时间,因为它需要调用大型语言模型进行大量信息提取工作。
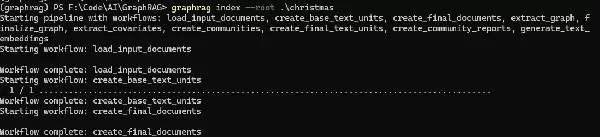 完成后,在 .\christmas\output 文件夹中查看生成的结果文件,这些是parquet格式的表格文件,保存着我们的知识图谱数据。
完成后,在 .\christmas\output 文件夹中查看生成的结果文件,这些是parquet格式的表格文件,保存着我们的知识图谱数据。
 2.3 使用查询引擎
当知识图谱构建完毕后,我们就能利用查询引擎来进行提问了。GraphRAG支持两种主要的查询方式:
global(全局搜索):在全部的知识图谱中搜索,适用于回答开放性和宏观性的问题。
local(本地搜索):在图谱的特定社群或子图中进行更精确的搜索,适用于回答具体和细节性的问题。
这里我们以全局搜索为例,因为我们查询的是贯穿《红楼梦》的一个重要事件。
graphrag query --root ./christmas --method global --query "总结‘元春省亲’这一事件对贾府的重要影响是什么?"
2.3 使用查询引擎
当知识图谱构建完毕后,我们就能利用查询引擎来进行提问了。GraphRAG支持两种主要的查询方式:
global(全局搜索):在全部的知识图谱中搜索,适用于回答开放性和宏观性的问题。
local(本地搜索):在图谱的特定社群或子图中进行更精确的搜索,适用于回答具体和细节性的问题。
这里我们以全局搜索为例,因为我们查询的是贯穿《红楼梦》的一个重要事件。
graphrag query --root ./christmas --method global --query "总结‘元春省亲’这一事件对贾府的重要影响是什么?"
 从结果可以看出,GraphRAG成功地从我们提供的文本中分析并总结了答案。
3 封装成MCP的服务
为了使GraphRAG的功能更易于被其他应用(特别是AI智能体)调用,我们可以将其封装成一个服务。这里我们采用FastMCP框架,将GraphRAG的查询功能打包成一个可以被智能体调用的工具(Tool)。
我们参考官方源码 graphrag/api/query.py 的架构,编写一个MCP服务。以下是代码的详细分段解析。
3.1 导入依赖与服务初始化
首先,我们导入所有必需的库,包括asyncio、os、pandas以及graphrag和mcp的相关模块。然后,初始化一个FastMCP实例,并命名为graphrag_search,这将是我们的服务名称。
#!/usr/bin/env python3
# coding=utf-8
import asyncio
import os
from abc import ABC, abstractmethod
from collections.abc import AsyncGenerator
from pathlib import Path
from typing import ClassVar, List, Optional
import pandas as pd
from dotenv import load_dotenv
from mcp.server.fastmcp import FastMCP
from graphrag.api.query import (global_search, global_search_streaming,
local_search, local_search_streaming)
from graphrag.config.load_config import load_config
from graphrag.config.models.graph_rag_config import GraphRagConfig
# 初始化MCP服务
mcp = FastMCP("graphrag_search")
3.2 全局配置
接下来,定义一些全局常量,用于指定GraphRAG生成的数据文件目录、LanceDB的URI以及默认的社群层级。同时,定义一个字典来映射表名,以便后续加载数据。
# --- 全局配置 ---
DATA_DIR = Path("./output")
LANCEDB_URI = f"{DATA_DIR}/lancedb"
COMMUNITY_LEVEL = 2
# 定义要读取的索引文件名称
TABLE_NAMES = {
从结果可以看出,GraphRAG成功地从我们提供的文本中分析并总结了答案。
3 封装成MCP的服务
为了使GraphRAG的功能更易于被其他应用(特别是AI智能体)调用,我们可以将其封装成一个服务。这里我们采用FastMCP框架,将GraphRAG的查询功能打包成一个可以被智能体调用的工具(Tool)。
我们参考官方源码 graphrag/api/query.py 的架构,编写一个MCP服务。以下是代码的详细分段解析。
3.1 导入依赖与服务初始化
首先,我们导入所有必需的库,包括asyncio、os、pandas以及graphrag和mcp的相关模块。然后,初始化一个FastMCP实例,并命名为graphrag_search,这将是我们的服务名称。
#!/usr/bin/env python3
# coding=utf-8
import asyncio
import os
from abc import ABC, abstractmethod
from collections.abc import AsyncGenerator
from pathlib import Path
from typing import ClassVar, List, Optional
import pandas as pd
from dotenv import load_dotenv
from mcp.server.fastmcp import FastMCP
from graphrag.api.query import (global_search, global_search_streaming,
local_search, local_search_streaming)
from graphrag.config.load_config import load_config
from graphrag.config.models.graph_rag_config import GraphRagConfig
# 初始化MCP服务
mcp = FastMCP("graphrag_search")
3.2 全局配置
接下来,定义一些全局常量,用于指定GraphRAG生成的数据文件目录、LanceDB的URI以及默认的社群层级。同时,定义一个字典来映射表名,以便后续加载数据。
# --- 全局配置 ---
DATA_DIR = Path("./output")
LANCEDB_URI = f"{DATA_DIR}/lancedb"
COMMUNITY_LEVEL = 2
# 定义要读取的索引文件名称
TABLE_NAMES = {
为了提高代码的可复用性,我们构建了一个名为 GraphRAGSearchBase 的抽象基类。该类的主要任务包括:
- 在实例化时,加载 .env 环境变量和 settings.yaml 配置文档。
- 依据子类设定的 REQUIRED_TABLES 清单,自动从 output 文件夹读取相应的 .parquet 数据文件至 Pandas DataFrame 中。
- 声明 search 和 stream_search 两个抽象方法,确保子类必须实现这两项搜索功能。
# 基础搜索类别,记录配置与数据表信息
class GraphRAGSearchBase(ABC):
REQUIRED_TABLES: ClassVar[List[str]] = []
def __init__(self, config_path: str = "./settings.yaml", data_dir: str | Path = DATA_DIR):
self.config_path = Path(config_path)
self.data_dir = Path(data_dir)
if not self.config_path.exists():
raise FileNotFoundError(f"配置文档未定位: {self.config_path}")
dotenv_path = self.config_path.parent / ".env"
if dotenv_path.exists():
load_dotenv(dotenv_path)
self.config = self._load_config()
self.dataframes = self._load_dataframes()
def _load_config(self) -> GraphRagConfig:
return load_config(root_dir=Path("."), config_filepath=self.config_path)
def _load_dataframes(self) -> dict[str, Optional[pd.DataFrame]]:
if not self.data_dir.exists():
raise FileNotFoundError(f"数据文件夹未定位: {self.data_dir}")
dataframes = {}
for table_key in self.REQUIRED_TABLES:
table_name = TABLE_NAMES.get(table_key)
if not table_name:
print(f"提示: 不明的表格标识符 '{table_key}'")
continue
file_path = self.data_dir / f"{table_name}.parquet"
if file_path.exists():
dataframes[table_key] = pd.read_parquet(file_path)
else:
if table_key == 'covariates':
dataframes[table_key] = None
print(f"提示: 协变量文件未定位: {file_path},将采用 None 值")
else:
raise FileNotFoundError(f"{table_key} 文件未定位: {file_path}")
return dataframes
@abstractmethod
async def search(self, query: str, response_type: str = "multiple paragraphs") -> tuple[str, dict]:
pass
@abstractmethod
async def stream_search(self, query: str, response_type: str = "multiple paragraphs") -> AsyncGenerator:
if False:
yield
3.4 实现本地搜索和全局搜索类
基于 GraphRAGSearchBase,我们创建了两个特定的实现类:GraphRAGLocalSearch 和 GraphRAGGlobalSearch。
GraphRAGLocalSearch:
它规定了本地搜索所需的所有数据表。
它实现了 search 和 stream_search 方法,内部调用了 GraphRAG SDK 提供的 local_search 和 local_search_streaming 函数。
# 本地搜索实现
class GraphRAGLocalSearch(GraphRAGSearchBase):
REQUIRED_TABLES = ['entities', 'communities', 'community_reports', 'text_units', 'relationships', 'covariates']
async def search(self, query: str, response_type: str = "multiple paragraphs") -> tuple[str, dict]:
return await local_search(
config=self.config,
community_level=COMMUNITY_LEVEL,
response_type=response_type,
query=query,
**self.dataframes
)
async def stream_search(self, query: str, response_type: str = "multiple paragraphs") -> AsyncGenerator:
async for chunk in local_search_streaming(
config=self.config,
community_level=COMMUNITY_LEVEL,
response_type=response_type,
query=query,
**self.dataframes
):
yield chunk
GraphRAGGlobalSearch:
它仅定义了全局搜索所需的几个主要数据表。
它同样实现了 search 和 stream_search 方法,但调用的是 global_search 和 global_search_streaming 函数。
# 全局搜索实现
class GraphRAGGlobalSearch(GraphRAGSearchBase):
REQUIRED_TABLES = ['entities', 'communities', 'community_reports']
async def search(self, query: str, response_type: str = "multiple paragraphs") -> tuple[str, dict]:
return await global_search(
config=self.config,
community_level=COMMUNITY_LEVEL,
dynamic_community_selection=False,
response_type=response_type,
query=query,
**self.dataframes
)
async def stream_search(self, query: str, response_type: str = "multiple paragraphs") -> AsyncGenerator:
async for chunk in global_search_streaming(
config=self.config,
community_level=COMMUNITY_LEVEL,
dynamic_community_selection=False,
response_type=response_type,
query=query,
**self.dataframes
):
yield chunk
3.5 定义MCP工具
这是将GraphRAG与MCP智能体相连的重要步骤。我们定义了两个异步函数 local_search_tool 和 global_search_tool,并利用 @mcp.tool() 装饰器将它们注册为MCP工具。
@mcp.tool(): 此装饰器会自动将函数转变为一种可以被AI Agent识别并调用的工具。
函数签名和文档字符串: 函数的参数和文档字符串(docstring)至关重要,因为它们用于生成工具的描述,AI Agent会依据这些描述来判断何时以及如何使用该工具。
# --- MCP 工具定义 ---
@mcp.tool()
async def local_search_tool(query: str, response_type: str = "multiple paragraphs") -> str:
"""
运用GraphRAG本地搜索功能进行查询,适用于针对特定实体和关系的详尽查询。
本地搜索特征:
- 集中于与查询相关的特定实体和关系
- 反馈迅速,消耗资源较少
- 适合具体、定向的问题
Args:
query: 查询语句,例如"红楼梦中贾宝玉与林黛玉的关系如何?"
response_type: 响应类型,可选值包括"multiple paragraphs"(多段落)、"single paragraph"(单段落)、"single sentence"(单句)等
Returns:
基于知识图谱的本地搜索结果
"""
search_service = GraphRAGLocalSearch()
response, _ = await search_service.search(query, response_type)
return response
@mcp.tool()
async def global_search_tool(query: str, response_type: str = "multiple paragraphs") -> str:
"""
运用GraphRAG全局搜索功能进行查询,适用于需要全面理解数据集的广泛问题。
全局搜索特征:
- 考虑整个知识图谱的背景信息
- 消耗资源较多,响应时间较长
- 适合广泛、概括性的问题
Args:
query: 查询语句,例如"总结红楼梦中主要人物的命运"
response_type: 响应类型,可选值包括"multiple paragraphs"(多段落)、"single paragraph"(单段落)、"single sentence"(单句)等
Returns:
基于知识图谱的全局搜索结果
"""
search_service = GraphRAGGlobalSearch()
response, _ = await search_service.search(query, response_type)
return response
3.6 编写测试和启动入口
最后,我们提供一个 if __name__ == "__main__": 入口,这样脚本既可以被MCP框架导入作为服务运行,也可以直接执行来进行快速测试。这里我们直接调用 global_search_tool 来验证其功能是否正常。
if __name__ == "__main__":
print("Running a direct test of the global search tool...")
result = asyncio.run(global_search_tool(query="总结'元春省亲'这一事件对贾府的重大意义是什么?"))
print(result)
输出:
D:\software_code\anaconda\envs\graphrag\python.exe F:\Code\AI\MCP\mcp_graph_rag\graphrag_server.py
Running a direct test of the global search tool...
17:41:56 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= qwen-flash; provider = openai
17:41:56 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= qwen-flash; provider = openai
17:41:56 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= qwen-flash; provider = openai
17:41:56 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= qwen-flash; provider = openai
[11/13/25 17:41:56] INFO utils.py:3422
LiteLLM 17:41:56 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= qwen-flash; provider = openai
completion() model= qwen-flash; provider = openai
17:41:56 - LiteLLM:INFO: utils.py:3422 - LiteLLM completion() model= qwen-flash; provider = openai
17:41:56 - LiteLLM:INFO: utils.py:3422 - LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
17:42:02 - LiteLLM:INFO: utils.py:3422 - LiteLLM completion() model= qwen-flash; provider = openai
[11/13/25 17:42:02] INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
元春省亲是《红楼梦》中贾府历史上最具象征意义的光辉事件,标志着贾府家族地位的巅峰时刻。作为贾府的长女,元春被选入宫并晋升为妃,其省亲活动不仅是皇权对贾府的直接认同,更体现了家族与皇室之间紧密的政治与血缘关系。这一事件在封建社会结构中具有极高的象征价值,使贾府从一个显赫的士族家庭跃升为与皇权相连的特殊阶层,其社会地位因此得到了前所未有的巩固与提升 [Data: Reports (4, 5)]。
然而,元春省亲的辉煌背后,潜藏着贾府由盛转衰的深刻伏笔。尽管仪式盛大、礼制严格,但省亲时间极为短暂,元春自身在宫廷中的地位亦显得脆弱,加上她对家族未来的担忧,暗示了这一荣耀的表面性和短暂性。这一事件并非单纯的家族庆典,更被视为贾府命运的转折点——其后贾府的奢侈之风愈演愈烈,过度挥霍财力,为日后的衰败埋下了隐患。元春的早逝虽未在文本中直接描述,但其命运轨迹已暗示了贾府失去政治保护后的迅速崩溃,因此省亲既是家族荣耀的顶点,也是衰亡的开端 [Data: Reports (4, 5)]。
为迎接省亲,贾府耗费巨资建造并装饰大观园,这一工程不仅是物质财富的集中展示,更反映了贾府对家族荣耀与未来期望的极致追求。大观园作为元春省亲的临时住所,其设计融合了礼制规范、审美理念与权力象征,展现了贾府在文化和空间构建上的高度自觉。然而,如此庞大的工程在短期内消耗了大量财力,不仅加重了家族的经济负担,也暴露了其资源分配的失衡,成为日后财政崩溃的预兆。大观园随后成为贾府成员日常生活与情感交流的重要场所,见证了青春、理想与爱情的萌芽,但也因承载过重的象征意义而最终沦为衰败的见证 [Data: Reports (4, 5)]。
从精神层面来看,元春省亲的仪式性质远超其实质意义。整个省亲流程包含了复杂的礼仪表演、诗歌唱和、宴饮庆典,这些活动不仅是对封建礼教的遵循,更反映了贾府作为士族家庭对文化和道德的自我彰显。这一事件在贾府成员心中留下了不可磨灭的印象,成为家族精神世界中最耀眼的部分。即便在家族后来遭受重创、衰败流离之时,元春省亲依旧被频繁回忆,成为一种情感依托与身份认同的标志,维持着家族成员对“家”的归属感与尊严感 [Data: Reports (4, 5)]。
在情感层面上,元春省亲为贾府带来了短暂而强烈的家族凝聚力。元春与贾母、王夫人、宝玉等亲人相聚,情感表达真挚感人,特别是与宝玉的互动,既展现了兄妹情深,也映射出家族内部亲情联系的宝贵。尽管这一短暂的相聚难以长久,但在心理上给予了贾府成员极大的安慰,使整个家族在短时间内感受到了荣誉与温暖,加强了“家”的情感基础。这种情感高峰虽然瞬间即逝,却在家族记忆中留下了深刻的痕迹,成为日后回忆与哀悼的关键支撑点 [Data: Reports (4, 5)]。
综上所述,元春省亲对贾府的意义是多方面且深远的:它不仅是家族地位的顶峰象征,也是命运转折的开端;不仅是物质与文化的集中展示,也是精神与情感的高潮时刻。这一事件在表面辉煌的背后,隐含着衰败的预示,通过建筑、仪式、情感与象征的交织,构建了一个关于权力、荣耀与失落的复杂叙述。其影响超越时空,不仅塑造了贾府的集体记忆,也深刻揭示了封建家族在皇权与命运面前的脆弱性和必然命运 [Data: Reports (4, 5)]。
command="python",
args=[server_script_path],
)
stdio, write = await self.exit_stack.enter_async_context(stdio_client(server_param))
self.session = await self.exit_stack.enter_async_context(ClientSession(stdio, write))
await self.session.initialize()
response = await self.session.list_tools()
logging.info(f"成功连接至GraphRAG服务器,可用工具列表: {[tool.name for tool in response.tools]}")
4.1.2 核心Agent逻辑 (process_query)
实现了一种典型的 ReAct (推断和行动) 模式的 Agent 流程:
- 获取可用工具: 从 MCP 服务器获得工具列表,并转换成 OpenAI API 需要的 tools 参数格式。
- 初次 LLM 调用 (决策阶段): 将用户的问题和可用工具列表一同发送给 LLM。LLM 会评估用户的请求,并判断是否需要使用某个工具来解答问题。若需要,它将返回一个包含所需工具名称和参数的 tool_calls 对象。
- 工具调用: 若 LLM 确定需要调用工具,客户端会解析 tool_calls,并利用 self.call_tool 方法向 MCP 服务器发起远程调用。
- 再次 LLM 调用 (总结阶段): 将工具返回的数据,加上之前的对话记录,重新发送给 LLM。这次,LLM 的目标是根据工具提供的数据,产生一个连贯、全面的自然语言响应。
- 返回结果: 如果 LLM 在初始阶段就确定无需调用工具,它将直接生成回复。反之,最终的答复将是第二次调用的结果。
async def process_query(self, query: str):
"""
处理用户查询的整体Agent流程
"""
messages = [{"role": "user", "content": query}]
# 1. 获取工具定义
mcp_tools = (await self.session.list_tools()).tools
available_tools = [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.model_json_schema()
}
} for tool in mcp_tools]
try:
# 2. 初次调用LLM:让模型做出决策
response = await self.client.chat.completions.create(
model=self.model,
messages=messages,
tools=available_tools,
tool_choice="auto",
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
if tool_calls:
logging.info(f"LLM决定调用工具: {tool_calls[0].function.name}")
messages.append(response_message)
tool_call = tool_calls[0]
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
# 3. 执行工具调用
tool_result_content = await self.call_tool(tool_name, tool_args)
tool_result_text = tool_result_content[0].text if tool_result_content else "工具执行失败。"
messages.append({
"role": "tool",
"content": tool_result_text,
"tool_call_id": tool_call.id
})
# 4. 再次调用LLM:让模型基于工具结果生成最终回答
logging.info("将工具结果返回给LLM进行总结...")
final_response = await self.client.chat.completions.create(
model=self.model,
messages=messages
)
final_answer = final_response.choices[0].message.content
else:
# 若模型选择不使用工具,直接给出答案
final_answer = response_message.content
print(f"\nGraphRAG 回答: {final_answer}\n")
return final_answer
except Exception as e:
logging.error(f"与LLM互动时出错: {e}")
print("\nGraphRAG: 对不起,处理您的请求时遇到问题。\n")
4.1.3 互动与启动
chat 方法提供了一个简易的命令行互动界面,而 main 函数作为程序的入口,负责创建客户端实例、建立服务器连接并启动聊天循环。
async def chat(self):
print("GraphRAG 智能问答助手已激活!您可以开始提问。输入 'exit' 或 '退出' 以结束会话。")
while True:
user_input = input("您: ")
if user_input.lower() in ["exit", "退出"]:
print("再见!")
break
await self.process_query(user_input)
async def main():
# 指向先前编写的 GraphRAG 服务器脚本的位置
server_script_path = "F:/Code/AI/MCP/mcp_graph_rag/graphrag_server.py"
client = GraphRAGClient()
try:
await client.connect_server(server_script_path)
if client.session:
await client.chat()
finally:
if client.session:
await client.close()
if __name__ == '__main__':
asyncio.run(main())
4.2 运行结果与解析
当我们启动客户端并询问“‘元春省亲’这一事件对贾府的重要影响是什么?”时,后端日志和前端显示了以下信息:
D:\software_code\anaconda\envs\graphrag\python.exe F:\Code\AI\MCP\mcp_graph_rag\graphrag_client.py
GraphRAG 智能问答助手已激活!您可以开始提问。输入 'exit' 或 '退出' 以结束会话。
您: [11/13/25 19:34:30] INFO 处理类型为 server.py:674
ListToolsRequest
2025-11-13 19:34:30,590 - INFO - 成功连接至GraphRAG服务器,可用工具列表: ['local_search_tool', 'global_search_tool']
‘元春省亲’这一事件对贾府的重要影响是什么?
[11/13/25 19:34:43] INFO 处理类型为 server.py:674
ListToolsRequest
2025-11-13 19:34:44,510 - INFO - HTTP 请求: POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions "HTTP/1.1 200 OK"
2025-11-13 19:34:44,542 - INFO - LLM决定使用工具: global_search_tool
2025-11-13 19:34:44,542 - INFO - 通过MCP调用工具 'global_search_tool',参数: {'query': '元春省亲这一事件对贾府的重要影响', 'response_type': 'single paragraph'}
[11/13/25 19:34:44] INFO 处理类型为 server.py:674
CallToolRequest
19:34:44 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
19:34:44 - LiteLLM:INFO: utils.py:3422 - LiteLLM completion() model= qwen-flash; provider = openai
19:34:44 - LiteLLM:INFO: utils.py:3422 - LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py19:34:44 - LiteLLM:INFO: utils.py:3422 - LiteLLM completion() model= qwen-flash; provider = openai
:3422
19:34:44 - LiteLLM:INFO: utils.py:3422 - LiteLLM completion() model= qwen-flash; provider = openai
LiteLLM completion() model= qwen-flash; provider = openai
19:34:44 - LiteLLM:INFO: utils.py:3422 - LiteLLM completion() model= qwen-flash; provider = openai
INFO 19:34:44 - LiteLLM:INFO: utils.py:3422 - LiteLLM completion() model= qwen-flash; provider = openai
utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
INFO utils.py:3422
LiteLLM completion() model= qwen-flash; provider = openai
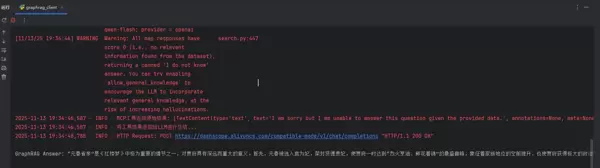
[11/13/25 19:34:46] WARNING Warning: All map responses have score 0 (i.e., no relevant information found from the dataset), returning a canned 'I do not know' answer. You can try enabling `allow_general_knowledge` to encourage the LLM to incorporate relevant general knowledge, at the risk of increasing inaccuracies.
2025-11-13 19:34:46,587 - INFO - MCP工具返回原始结果: [TextContent(type='text', text='I am sorry but I am unable to answer this question given the provided data.', annotations=None, meta=None)]
2025-11-13 19:34:46,587 - INFO - 将工具结果返回给LLM进行总结...
2025-11-13 19:34:48,788 - INFO - HTTP Request: POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions "HTTP/1.1 200 OK"
GraphRAG Answer: “元春省亲”是《红楼梦》中非常关键的情节之一,对贾府有深远且重要的影响。首先,元春入选宫廷为妃,荣升贤德贵妃,使贾府达到了“烈火烹油、鲜花着锦”的辉煌顶峰,标志着家族地位的显著提高,同时也为贾府赢得了巨大的政治荣誉和社会声誉。其次,元春省亲的事件直接推动了大观园的建设,不仅为贾府增添了豪华的园林景观,还成为了贾府贵族生活、诗歌聚会和情感纷争的主要场所。更为重要的是,这一事件在表面繁荣的背后隐藏着危机:尽管元春省亲的场面极其隆重,但也透露出她在深宫中的孤独和命运的无奈,预示着贾府从繁荣到衰败的命运。因此,“元春省亲”不仅是贾府荣耀的最高点,也是其由盛转衰的关键转折,具有强烈的象征意义和命运警示功能,深刻反映了封建家族兴衰无定、繁华易逝的悲剧主题。
已经成功地使用了agent:
智能决策: LLM 接收到问题后,准确地识别出这是一个宏观问题,并决定调用 global_search_tool。它甚至改进了查询语句。
工具的限制: GraphRAG 工具在其被提供的数据——《圣诞颂歌》的文本中进行了搜索。由于数据源中不含《红楼梦》的内容,GraphRAG 如实返回了“我不知道”的结果。
Agent的知识补充: 当客户端 Agent 收到工具的否定回应后,并未直接向用户传达“我不知道”。而是将此结果作为背景信息,再次询问 LLM。这时,LLM 认识到其专用工具无法提供帮助,于是启动了自身的内部知识库,最终提供了关于“元春省亲”的高质量且完全正确的解答。
这个流程完美体现了 Agent 架构的优点:它能智能调配外部工具以获取精准、实时的信息,当外部工具无效时,它还能平滑地切换至利用模型的通用知识,从而最大程度地确保了问答的效率和质量。

 京公网安备 11010802022788号
京公网安备 11010802022788号







