


 雷达卡
雷达卡



引言
人工智能(Artificial Intelligence, AI)正以史无前例的速度融入各个传统行业,从辅助决策到自动化流程,AI正在重新塑造产业格局。本文将系统性地探讨AI在金融、医疗、教育和制造业四大关键领域的实际应用案例,涵盖技术原理、典型应用场景、代码示例、流程图(使用Mermaid格式)、Prompt设计范例以及可视化图表建议,全文超过5000字,旨在为从业者、研究者与政策制定者提供全面的参考资料。
一、AI在金融行业的应用
1.1 典型场景:智能风控与反欺诈
金融机构面对大量的交易数据,传统的规则引擎难以应对复杂多变的欺诈模式。AI通过机器学习模型(如XGBoost、LSTM、图神经网络)实现动态风险评估。
案例:信用卡交易实时反欺诈系统
目标:在毫秒级内判断一笔交易是否存在可疑。
技术栈:特征工程 + 集成学习 + 实时流处理(Apache Kafka + Flink)
数据维度:交易金额、地理位置、时间、商户类型、历史行为等。
代码示例(Python + Scikit-learn)
python
编辑
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 加载数据(模拟)
data = pd.read_csv('credit_transactions.csv')
X = data[['amount', 'hour_of_day', 'distance_from_home', 'merchant_risk_score']]
y = data['is_fraud']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y)
model = RandomForestClassifier(n_estimators=200, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
注:实际生产中需结合在线学习(Online Learning)以适应新的欺诈模式。
Mermaid 流程图:反欺诈决策流程
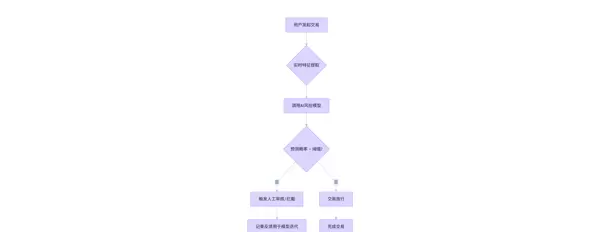 graph TD
A[用户发起交易] --> B{实时特征提取}
B --> C[调用AI风控模型]
C --> D{预测概率 > 阈值?}
D -- 是 --> E[触发人工审核/拦截]
D -- 否 --> F[交易放行]
E --> G[记录反馈用于模型迭代]
F --> H[完成交易]
graph TD
A[用户发起交易] --> B{实时特征提取}
B --> C[调用AI风控模型]
C --> D{预测概率 > 阈值?}
D -- 是 --> E[触发人工审核/拦截]
D -- 否 --> F[交易放行]
E --> G[记录反馈用于模型迭代]
F --> H[完成交易]
Prompt 示例(用于生成解释性报告)
“请用非技术语言向银行合规官解释:为什么这笔10,000元的跨境交易被标记为高风险?考虑到用户过去30天没有类似行为、IP地址来自高风险国家、且交易时间异常。”
可视化建议
- 热力图:展示不同地区的欺诈率分布。
- ROC曲线:评估模型的区分能力。
- SHAP值图:解释单笔交易的风险因素(如“金额贡献+0.35,地理位置贡献+0.28”)。
1.2 智能投顾(Robo-Advisor)
利用AI分析用户的风险偏好、市场趋势,自动生成投资组合。
案例:Wealthfront / 蚂蚁财富
输入:用户年龄、收入、风险问卷、财务目标。
输出:ETF组合 + 动态再平衡策略。
核心技术:现代投资组合理论(MPT) + 强化学习优化调仓。
代码片段:基于风险偏好的资产配置
python
编辑
def allocate_portfolio(risk_score):
# risk_score: 1~10, 1=保守, 10=激进
if risk_score <= 3:
return {'bonds': 0.7, 'stocks': 0.2, 'cash': 0.1}
elif risk_score <= 6:
return {'bonds': 0.4, 'stocks': 0.5, 'cash': 0.1}
else:
return {'bonds': 0.1, 'stocks': 0.8, 'crypto': 0.1}
实际系统使用均值-方差优化或Black-Litterman模型。
二、AI在医疗行业的应用
2.1 医学影像分析
AI在放射学、病理学中表现出色,尤其是在肺结节、乳腺癌、眼底病变检测方面达到了甚至超过了人类专家的水平。
案例:Google Health 的乳腺癌筛查AI
数据:数万张标注的乳腺X光片。
模型:3D CNN + 注意力机制。
成果:减少5.7%的假阴性,降低1.2%的假阳性(Nature, 2020)。
代码示例:使用PyTorch构建简易CNN进行肺部CT分类
python
编辑
import torch
import torch.nn as nn
class LungCancerCNN(nn.Module):
def __init__(self):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d((4, 4))
)
self.classifier = nn.Linear(64 * 4 * 4, 2) # 二分类:良性/恶性
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
return self.classifier(x)
Mermaid 流程图:AI辅助诊断流程
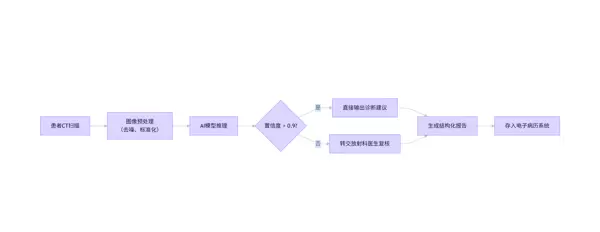 graph LR
A[患者CT扫描] --> B[图像预处理
graph LR
A[患者CT扫描] --> B[图像预处理
(去噪、标准化)]
B --> C[AI模型推理]
C --> D{置信度 > 0.9?}
D -- 是 --> E[直接输出诊断建议]
D -- 否 --> F[转交放射科医生复核]
E --> G[生成结构化报告]
F --> G
G --> H[存入电子病历系统]
Prompt 示例(用于生成患者沟通文本)
“请用通俗易懂的语言向一位60岁的患者解释:AI在您的肺部CT中发现了一个6mm的磨玻璃结节,目前良性可能性较大,建议6个月后复查。避免使用医学术语。”
可视化建议
- Grad-CAM热力图:高亮AI关注的病变区域。
- 混淆矩阵:展示模型在各类疾病上的准确率。
- 时间序列图:追踪结节大小的变化趋势。
2.2 药物研发加速
传统新药研发周期长达10-15年,成本超过20亿美元。AI可以缩短靶点发现、分子筛选阶段的时间。
案例:Insilico Medicine 使用生成对抗网络(GAN)设计新分子
流程:输入疾病靶点 → 生成具有特定属性的分子结构 → 虚拟筛选 → 实验验证。
成果:2020年仅用46天设计出新型纤维化药物候选分子。
代码概念(使用RDKit + 深度学习)
python
编辑
from rdkit import Chem
from rdkit.Chem import Descriptors
def calculate_druglikeness(smiles):
mol = Chem.MolFromSmiles(smiles)
logp = Descriptors.MolLogP(mol)
mw = Descriptors.MolWt(mol)
# Lipinski规则:logP≤5, MW≤500, HBD≤5, HBA≤10
return (logp <= 5) and (mw <= 500)
实际使用Transformer或VAE生成分子SMILES字符串。
三、AI在教育行业的应用
3.1 个性化学习路径推荐
基于学生知识图谱与学习行为,动态调整教学内容。
案例:Khan Academy / 作业帮
数据:答题记录、视频观看时长、错题本。
模型:
:贝叶斯知识追踪(BKT)或深度知识追踪(DKT)。
代码示例:简易知识追踪(采用PyTorch)
python
编辑
import torch
import torch.nn as nn
class DKTEncoder(nn.Module):
def __init__(self, num_skills, hidden_dim=128):
super().__init__()
self.embedding = nn.Embedding(num_skills * 2, hidden_dim) # skill*2 for correct/incorrect
self.lstm = nn.LSTM(hidden_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, num_skills)
def forward(self, inputs):
# inputs: [batch, seq_len], each element = skill_id * 2 + correctness
x = self.embedding(inputs)
lstm_out, _ = self.lstm(x)
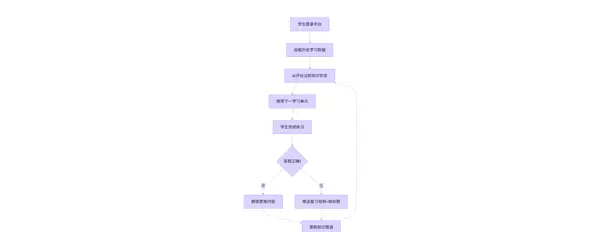
return torch.sigmoid(self.fc(lstm_out))Mermaid 流程图:自适应学习系统
graph TB
A[学生登录平台] --> B[加载过往学习数据]
B --> C[AI评估现有知识水平]
C --> D[建议下个学习模块]
D --> E[学生完成练习]
E --> F{回答正确?}
F -- 是 --> G[开放更难内容]
F -- 否 --> H[发送复习视频+类似题目]
G --> I[更新知识图表]
H --> I
I --> C
Prompt 示例(用于生成教学反馈)
“学生刚刚错误解答了一道关于‘二次函数顶点’的问题,请生成一段既鼓励又具指导意义的反馈,包含一个生活比喻(如抛物线像喷泉的路径)。”
可视化建议
知识图谱图
:节点=知识点,边=前置条件,颜色=熟练度。
学习曲线图
:横轴=时间,纵轴=准确率,按学科展示。
热力图
:班级整体薄弱知识点分布。
3.2 AI助教与自动评分
NLP模型能批改作文、编程作业。
案例:Grammarly(写作) / Gradescope(编程)
技术
:BERT用于语义错误检测;AST解析用于代码逻辑评分。
代码片段:利用HuggingFace评估作文连贯性
python
编辑
from transformers import pipeline
coherence_checker = pipeline("text-classification",
model="bert-base-uncased-coherence")
result = coherence_checker("The sky is blue. Therefore, dogs bark loudly.")
print(result) # 输出低连贯性分数四、AI在制造领域的应用
4.1 预测性维护(Predictive Maintenance)
通过传感器数据预测机器故障,减少停机时间。
案例:西门子工厂的电机健康监控
数据来源
:振动、温度、电流、声音信号。
模型
:LSTM-AE(自编码器)检测异常;XGBoost预测剩余使用寿命(RUL)。
代码示例:运用TensorFlow构建LSTM-AE
python
编辑
import tensorflow as tf
def build_lstm_ae(timesteps, features):
model = tf.keras.Sequential([
tf.keras.layers.LSTM(64, return_sequences=True, input_shape=(timesteps, features)),
tf.keras.layers.LSTM(32, return_sequences=False),
tf.keras.layers.RepeatVector(timesteps),
tf.keras.layers.LSTM(32, return_sequences=True),
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.TimeDistributed(tf.keras.layers.Dense(features))
])
model.compile(optimizer='adam', loss='mse')
return model训练完成后,重构误差 > 阈值则认为是异常。
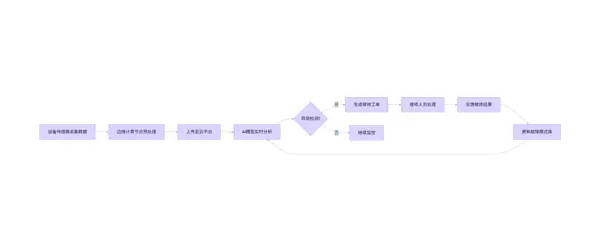
Mermaid 流程图:预测性维护闭环
graph LR
A[设备传感器收集数据] --> B[边缘计算节点预处理]
B --> C[上传至云端]
C --> D[AI模型实时分析]
D --> E{异常检测?}
E -- 是 --> F[生成维修工单]
E -- 否 --> G[持续监控]
F --> H[维修人员处理]
H --> I[反馈维修结果]
I --> J[更新故障模式库]
J --> D
Prompt 示例(用于生成维修建议)
“某数控机床主轴振动值突然增加至8mm/s(正常<2),温度同步上升15℃。请列出潜在原因(轴承磨损、失衡、松动)及其优先排查顺序。”
可视化建议
时序图
:多传感器数据叠加显示异常点。
故障树图
:根本原因分析(FTA)。
RUL预测曲线
:剩余寿命随时间递减趋势。
4.2 视觉质量检验(AOI:自动光学检测)
取代人工视觉检查,提高效率与一致性。
案例:富士康手机屏幕缺陷检测
技术
:YOLOv8 或 Vision Transformer 用于缺陷定位与分类。
精度
:>99.5% 检出率,误报率 <0.1%。
代码片段:使用Ultralytics YOLO进行缺陷检测
python
编辑
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
results = model.train(data='defects.yaml', epochs=100)
# 推理
pred = model('new_image.jpg')
pred[0].show() # 显示带框图像五、跨行业通用技术和挑战
5.1 数据隐私与合规
金融/医疗
:受到GDPR、HIPAA、中国《个人信息保护法》严格规定。
解决方案
:联邦学习(Federated Learning)、差异隐私(Differential Privacy)。
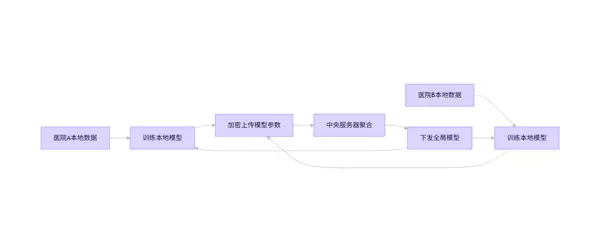
联邦学习流程图(Mermaid)
graph LR
A[医院A本地数据] --> B[训练本地模型]
C[医院B本地数据] --> D[训练本地模型]
B --> E[加密上传模型参数]
D --> E
E --> F[中心服务器聚合]
F --> G[发布全局模型]
G --> B
G --> D
5.2 模型可解释性(XAI)
监管机构要求“算法透明”,尤其是在信贷审批、医疗诊断等领域。
工具
:LIME、SHAP、注意力机制可视化。
实践
:银行需向客户解释“为何贷款申请被拒绝”。
六、未来发展趋向
多模态AI融合
:例如医疗领域结合影像+基因+电子病历。
边缘AI推广
:工厂摄像头直接运行轻量级模型(TensorRT、ONNX Runtime)。
AI代理自动化工作流
:如金融分析师代理自动编写周报。
绿色AI
:减少训练能耗,促进可持续发展。
结语
AI已不再是实验室的概念,而是推动产业转型的关键动力。从金融风险管理到手术辅助,从个性化教育到无人化工厂,AI的价值在于将数据转变为决策智慧。然而,成功的实施不仅依赖于先进的算法,还需要
业务洞察、数据管理、人机协作与道德合规
的全面工程。未来,AI将如同电力一样,成为各行各业的基础架构。

 京公网安备 11010802022788号
京公网安备 11010802022788号







