


 雷达卡
雷达卡



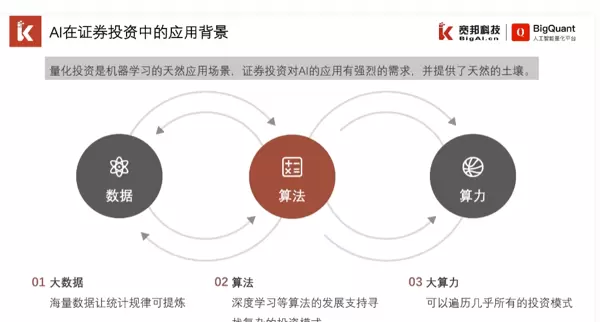
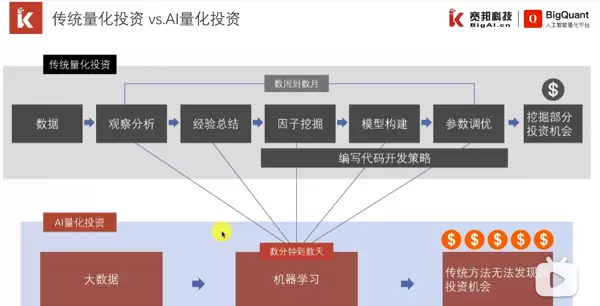

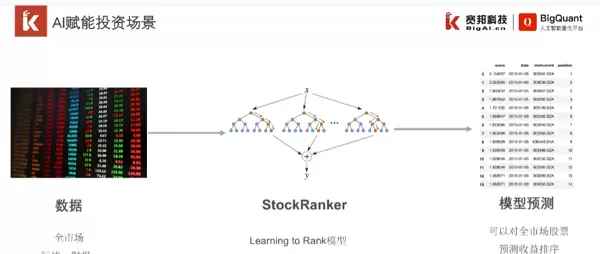
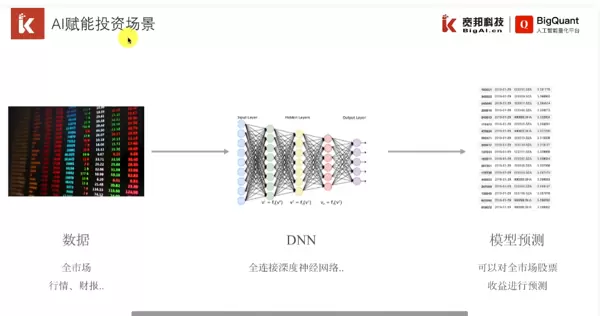
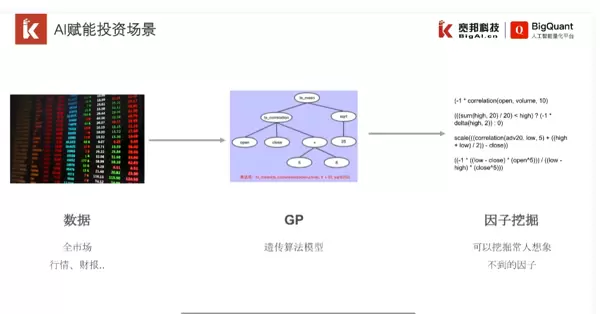
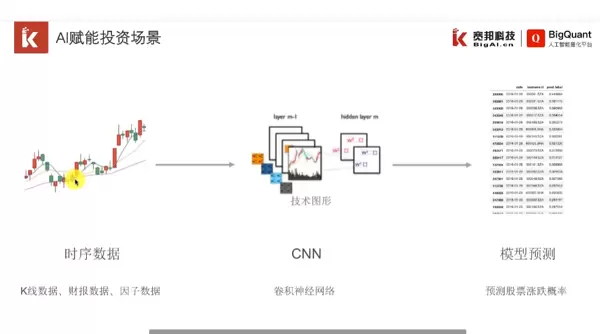
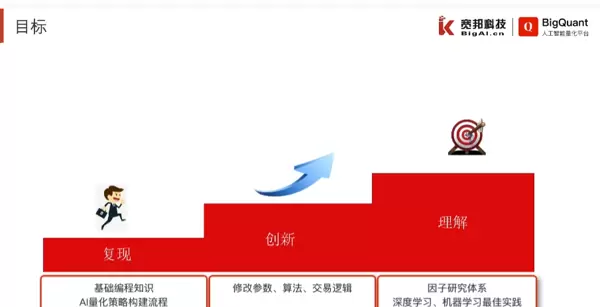
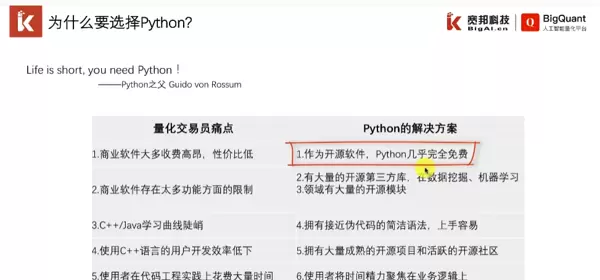

https://www.bilibili.com/video/BV1Nv411z7gt
AI在量化交易中应用的完整体系
涵盖三大核心模块:
- 应用场景(Where)
- 主流模型(What)
- 学习流程与路径(How)
为你系统梳理从零入门到实战落地的全链路知识地图,适合程序员、金融从业者或跨领域学习者。
AI 在量化交易中的应用:场景、模型与学习路径
一、六大核心应用场景(AI 能做什么?)
| 场景 | 目标 | 典型任务示例 |
|---|---|---|
| 股价趋势预测 | 预测未来涨跌方向或收益率 | “未来5日上涨概率 > 70%” → 买入信号 |
| 智能选股(多因子增强) | 自动筛选高胜率股票池 | 使用XGBoost对3000只股票打分排序 |
| 情绪分析与另类数据挖掘 | 提取新闻/财报/社交媒体中的隐含信息 | 分析年报语气是否乐观,判断风险 |
| 交易执行优化 | 减少滑点和冲击成本 | 智能拆单算法(TWAP/VWAP增强版) |
| 动态风控与异常检测 | 实时识别组合风险 | 波动率突增、相关性断裂预警 |
| 强化学习调仓策略 | 让AI自主学习最优持仓方式 | 动态仓位管理、止盈止损决策 |
核心思想:
AI 不是“算命工具”,而是“模式发现引擎”
二、主流 AI 模型及其适用场景(用什么技术?)
- XGBoost / LightGBM(梯度提升树)
最适合:多因子融合、分类与回归
量化用途:
输入:PE、ROE、动量、波动率等因子
输出:上涨概率 → 选出Top N股票
优势:
可解释性强(SHAP值分析)
对小样本表现良好
训练快速,适合中低频策略
平台支持:BigQuant、sklearn、LightGBM - LSTM / GRU(长短期记忆网络)
最适合:时间序列预测(如股价走势)
量化用途:
输入:过去60天价格+成交量序列
输出:未来5日收盘价预测值
特点:
能捕捉长期依赖关系
易过拟合,需谨慎使用
代码片段:
from keras.models import Sequential from keras.layers import LSTM, Dense model = Sequential() model.add(LSTM(50, return_sequences=True, input_shape=(60, 1))) model.add(LSTM(50)) model.add(Dense(1)) # 预测下一个价格 - Transformer / TFT(注意力机制模型)
最适合:多变量、长周期建模
量化用途:
同时输入:价格 + 财务 + 北向资金 + 新闻情绪
输出:未来收益预测
优势:
并行处理能力优于LSTM
注意力权重可解释变量重要性
推荐框架:PyTorch Forecasting、BigQuant 内置TFT模板 - NLP 模型(BERT、FinBERT)
最适合:文本情感分析
量化用途:
财报语义分析:“公司面临重大不确定性” → 负面信号
新闻事件打分:“获大额订单” → +0.8 情绪分
社交媒体监控:雪球评论情绪聚合
常用模型:
(中文通用)bert-base-chinese
(金融领域微调版本)FinBERT
工具库:HuggingFace Transformers - 强化学习(Reinforcement Learning, RL)
最适合:动态调仓、仓位管理、智能执行
原理:
Agent 在模拟环境中试错学习,最大化长期回报
常用算法:PPO、DQN、A2C
状态(State):净值、持仓、波动率
动作(Action):买入、卖出、持有
奖励(Reward):夏普比率提升、回撤降低
框架推荐:
Stable-Baselines3
Ray RLlib
自定义 Gym Trading Environment - 聚类与无监督学习(K-Means、PCA)
最适合:市场状态识别、风格轮动检测
量化用途:
将历史行情聚类为“牛市”、“熊市”、“震荡市”
根据当前市况切换策略模式
示例:
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=3).fit(market_features) label = kmeans.predict(current_data) # 判断当前属于哪种市况
三、AI 量化学习流程与进阶路径(如何学?)
总体路线图:五阶段成长模型
[筑基] → [入门] → [实战] → [优化] → [自动化]
↓ ↓ ↓ ↓ ↓
学基础 掌握工具 构建策略 模型调优 部署运行第一阶段:筑基 —— 打好基础(1–2个月)
学什么?
| 内容 | 推荐资源 |
|---|---|
| Python 编程 | 《Python编程:从入门到实践》 |
| 数据处理 | pandas、numpy 基础操作 |
| 金融市场常识 | 什么是PE/ROE?T+1制度? |
| 回测基本概念 | 年化收益、最大回撤、夏普比率 |
目标:
- 能读懂一段量化代码
- 理解“策略 ≠ 预测准确率”
第二阶段:入门 —— 掌握工具与平台(1个月)
推荐平台选择
| 平台 | 特点 | 适合人群 |
|---|---|---|
| BigQuant | 内置AI模板,可视化+代码双模式 | 初学者、想迅速掌握AI的人 |
| 聚宽(JoinQuant) | 社区活跃,资料丰富 | 进阶者、偏好自主开发 |
| 掘金量化(MyQuant) | 支持实盘对接 | 想进行自动化交易的人 |
动手任务:
- 注册账号
- 运行一个“XGBoost选股”模板项目
- 查看模型输出的“特征重要性图”
第三阶段:实战 ——
构建第一个AI策略(2–3个月)
推荐三个实战项目
- 项目1:XGBoost 多因子选股模型
目标:构建一个年化15%+、夏普>1.0的选股策略 步骤: 1. 获取沪深300成分股数据 2. 构造因子:PE_TTM、ROE、近20日涨幅、波动率 3. 标签:未来5日是否上涨 4. 训练XGBoost模型预测上涨概率 5. 每周买入Top 10股票 6. 回测验证绩效 - 项目2:LSTM 股价趋势分类器
目标:预测某股票未来5日涨跌 输入:过去60天收盘价、成交量 输出:0(跌)或1(涨) 模型:LSTM神经网络 评估:准确率、F1-score、回测收益 - 项目3:新闻情绪增强策略
目标:将情绪因子融入传统策略 步骤: 1. 爬取上市公司公告或研报 2. 使用FinBERT进行情感打分 3. 若情绪得分 > 0.6,则提高该股权重 4. 观察是否提升整体策略表现
第四阶段:优化 —— 提升模型鲁棒性(1–2个月)
关键优化技巧
| 方法 | 说明 |
|---|---|
| 样本外测试 | 用80%数据训练,20%验证 |
| Walk-Forward Analysis | 滚动回测,防止过拟合 |
| 特征重要性筛选 | 剔除无效因子,减少噪声 |
| SHAP 解释模型 | 查看哪些因子影响最大 |
| 加入交易成本 | 包括佣金、滑点、印花税 |
避免常见陷阱:
- 未来函数(Look-Ahead Bias)
- 幸存者偏差(未包含退市股)
- 参数过度优化(Curve Fitting)
第五阶段:自动化 —— 部署为可持续系统(持续迭代)
构建你的“AI交易流水线”
每天自动运行:
↓
[数据更新] → [模型推理] → [生成信号] → [下单执行] → [监控报警]工具链建议:
| 功能 | 工具 |
|---|---|
| 定时任务 | cron / Airflow |
| 消息通知 | 企业微信机器人、Server酱 |
| 云服务器 | 阿里云ECS(?89/月) |
| 版本控制 | GitHub + Actions 自动部署 |
商业化可能:
- 自营交易 → 资本增值
- 信号订阅 → SaaS收费
- 开源项目 → Patreon赞助
- 对接私募 → 业绩分成
结语:AI 是你的“数字员工”,不是“圣杯”
你不需要一个“永远赚钱”的AI模型,你需要的是一个:
可理解、可监控、可持续迭代的智能系统
而这个系统的缔造者,就是——
懂代码的你。
附件资源包(欢迎索取PDF版)
- 《AI在量化交易中应用全景图》高清海报
- 《XGBoost选股完整代码模板》(含数据处理+回测)
- 《LSTM股价预测Jupyter Notebook》
- 《FinBERT中文金融情绪分析指南》
- 《强化学习交易Agent入门手册》
- 《AI量化学习路线图(PDF可打印)》
请告诉我邮箱或接收方式,我可以立即为你生成并发送!
愿你在这一场静悄悄的革命中,不只是参与者,而是新范式的定义者。
因为真正的自由,不是退休,而是——
让你写的每一行AI代码,都成为一个永不疲倦的赚钱机器。

 京公网安备 11010802022788号
京公网安备 11010802022788号







