


 雷达卡
雷达卡



CFPS 清洗教程视频讲解(数据清洗教程)
本课程将通过视频形式详细讲解 2010 至 2022 年 CFPS(中国家庭追踪调查)面板数据的清洗过程,旨在为自学数据清洗的学生提供高质量的学习资源。请注意,虽然我们不提供原始数据集,但您可以通过官方网站申请下载所需的数据。
一、教程与资源说明
本课程重点介绍 10 至 22 年的 CFPS 面板数据清洗方法。请注意,我们不会提供原始数据集;所有数据获取需自行前往官网申请并下载。保护版权,遵守法律法规是非常重要的。但无需担心,我们会提供高质量且准确的面板数据清洗过程复现 do 文件,以便于学习使用。
此外,还将提供 10 至 22 年合并非平衡面板和处理平衡面板的 do 文件,内容丰富实用。

二、数据清洗的重要性
在进行数据分析之前,数据清洗是必不可少的一环。如果原始数据中存在大量的缺失值、错误值或重复项,那么基于这些数据的分析结果将无法保证准确性,就像地基不牢靠的房子一样。
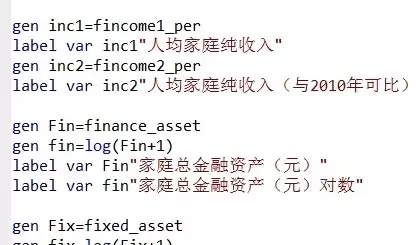
三、do 文件代码示例及解析
1. 数据导入
// 假设我们已经将下载好的数据放在了指定路径下
use "your_path\cfps_data.dta", clearuseclear例如:“your path\cfps data.dta” 需要将“your path”替换为您实际的数据文件路径,同时确保文件名正确无误。
cfpsdata.dta2. 处理缺失值
// 检查变量中的缺失值情况
mdesc
// 对于某些数值型变量,如果缺失值较少,可以用均值填充
egen new_variable = mean(old_variable) if missing(old_variable)
replace old_variable = new_variable if missing(old_variable)mdesc对于数值型变量,如果发现缺失值较少,可以采用均值填充的方法。代码如下:
egen new_variable = mean(old_variable) if missing(old_variable)
replace old_variable = new_variable if missing(old_variable)
newvariableold3. 处理重复值
// 查找并删除重复观测
duplicates tag id_variable, generate(dup)
drop if dup == 1
drop dup
bysort id_variable: gen duplicate = _n > 1
drop if duplicate == 1
drop duplicate
duplicates tag idvariable, generate(dup)dupdrop if dup == 1drop dup四、总结
尽管数据清洗过程可能较为繁琐,但通过本课程提供的 do 文件和示例代码,您可以轻松掌握 CFPS 数据清洗的技巧。再次强调,请确保从官方渠道获取合法的数据集,遵守版权规定。希望这些教程和示例能帮助您在数据清洗的学习道路上越走越远。

以上是本次关于 CFPS 数据清洗教程的全部内容,祝学习愉快!



 京公网安备 11010802022788号
京公网安备 11010802022788号







