


 雷达卡
雷达卡



在自动驾驶、工业质量检测、安全监控等领域,实时目标检测一直是技术上的重大挑战,特别是在需要“毫秒级响应”的应用场景中。在过去十年间,YOLO系列以其轻量化和高效能的特性,成为了这一领域的主要解决方案。从最初的YOLO到最新的YOLOv11、YOLOv12,该系列模型一直在尝试在速度与准确性之间找到最佳平衡。
尽管经历了多次迭代,YOLO系列的核心机制仍然存在一些共同的问题:一方面,卷积操作仅能在固定的感受野内进行局部信息聚合;另一方面,虽然自注意力机制能够扩大感受野,但由于其计算成本较高,通常在实际应用中被限制在特定区域内,从而丧失了全局视角的优势。更重要的是,自注意力机制主要关注像素间的二元关系,这限制了它在处理复杂场景、细节对象或高度复杂的视觉关系时的能力。
为了克服这些限制,由清华大学、太原理工大学和西安交通大学的研究人员组成的团队开发了一种新的目标检测模型——YOLOv13,该模型通过引入HyperACE(基于超图的自适应相关性增强机制)将相关性建模从二元关系扩展到了更高阶的结构。HyperACE通过将不同尺度的特征图中的像素作为节点,并利用可学习的超边构建模块来探索节点之间的高阶相关性,进而通过一个线性复杂度的信息传递模块,根据高阶相关性有效地融合多尺度特征,从而在复杂的视觉场景中实现更准确的感知。
除了HyperACE之外,YOLOv13还提出了FullPAD(全管道聚合-分布范式),该范式首先在全球尺度上增强相关性,然后将增强的相关性特征分发到backbone、neck和head的不同阶段,确保高阶语义在整个检测过程中得到充分利用,从而改进梯度流动并提高整体性能。此外,该模型采用了更轻量的深度可分离卷积模块代替传统的大型卷积核,这样在保持精度的同时减少了参数和计算资源的需求。
实验结果表明,无论是小型模型还是大型模型,YOLOv13在MS COCO数据集上的表现都有显著提升,尤其是在减少参数数量和FLOPs的情况下,达到了当前最优的检测效果。例如,YOLOv13-N相比YOLOv11-N提升了3.0%的mAP,而相对于YOLOv12-N则提高了1.5%。
现在,用户可以在HyperAI超神经官网上的一键部署教程中体验YOLOv13的部署过程。
Demo 运行指南
- 访问hyper.ai首页,选择“一键部署YOLOv13”或进入“教程”页面选择相应选项,点击“在线运行此教程”。
- 页面加载完成后,点击右上角的“Clone”,将教程复制到个人容器中。请注意,页面右上角提供了语言切换功能,支持中文和英文两种版本,本文将以英文版为例进行介绍。
- 选择合适的硬件配置(如NVIDIA GeForce RTX 5090)和软件环境(如PyTorch),根据需要选择计费方式(按量付费或包日/周/月),最后点击“Continue job execution(继续执行)”。
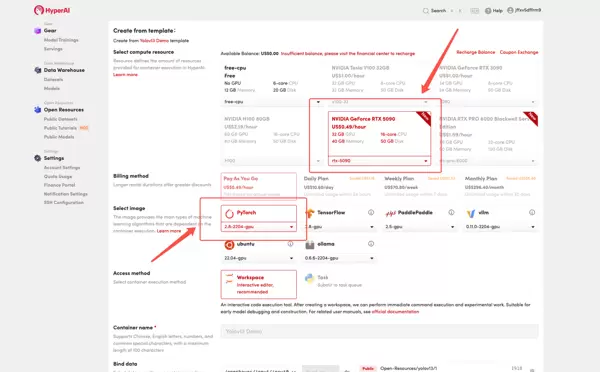
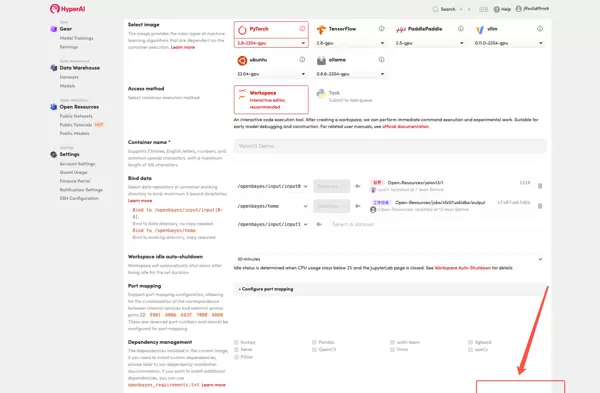
- 等待系统分配资源,初次使用可能需要大约3分钟的时间。当状态显示为“运行中”时,点击“API地址”旁的箭头图标,即可进入Demo页面。
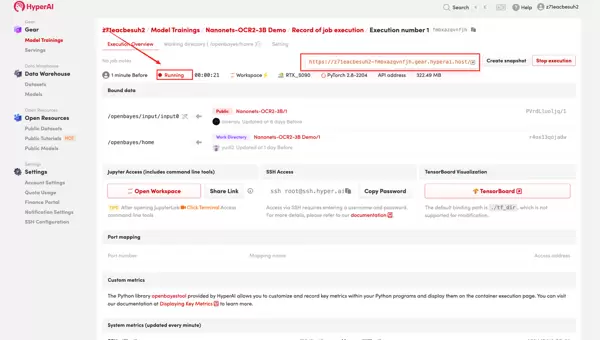
效果演示
在Demo运行页面,用户可以通过上传图片或视频并点击“Detect Objects”按钮来启动检测过程。
参数说明:
- Model: 可选模型包括yolov13n.pt(nano)、yolov13s.pt(small)、yolov13l.pt(large)、yolov13x.pt(extra large)。模型规模越大,精度(mAP)越高,但相应的参数量、计算量(FLOPs)和推理时间也会增加。
- Confidence Threshold: 置信度阈值用于过滤检测结果,只有当检测到的对象置信度超过此阈值时才会被保留。
IoU 阈值:即交并比阈值,用于非极大值抑制(NMS)过程。
每张图像的最大检测数:指在单个图像中可以检测到的最大边界框数量。
以下测试是使用「yolov13s.pt」模型进行的,具体效果如图所示。

以上是 HyperAI 超神经本期推荐的教程内容,欢迎各位前来体验!
教程链接:
https://go.hyper.ai/EHfXY

 京公网安备 11010802022788号
京公网安备 11010802022788号







