


 雷达卡
雷达卡




在当今互联网技术迅速发展的背景下,数据库技术已经历了从单机MySQL到分布式NoSQL的重大变革。
数据库技术的发展历程
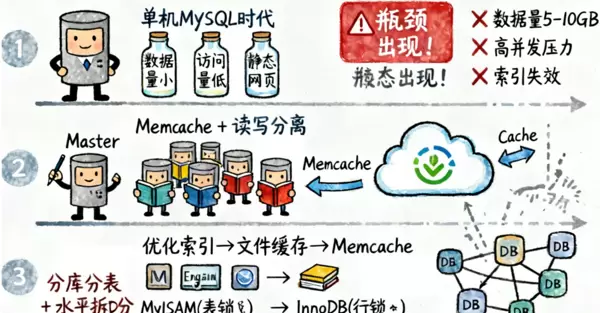
1. 单机MySQL时代
在互联网早期,应用架构较为简单,主要采用“应用层 - 数据访问层 - 数据库”的三层架构。单机MySQL能够很好地满足当时的业务需求,原因在于:
- 数据量较小,单表数据量处于可管理范围;
- 网站多为静态页面,动态交互较少;
- 访问量有限,对并发的压力不大。
然而,随着时间的推移,这种架构的局限性逐渐显露:
- 数据量瓶颈: 当单表数据量达到5-10GB时,查询性能显著下降;
- 访问压力瓶颈: 高并发读写请求导致数据库响应变慢;
- 索引效率瓶颈: 随着数据的增长,索引文件变得过大,影响查询效率。
2. Memcache + MySQL + 垂直拆分阶段
为了克服单机的局限,数据库架构开始演变,采取了以下措施:
- 读写分离策略: 主库负责写操作,从库负责读操作,通过主从复制确保数据的一致性,从而有效地分散数据库压力,提高并发处理能力;
- 引入缓存层: 引入Memcache作为缓存层,优化流程包括首次请求、后续请求和缓存失效三种情况。
这一阶段的改进过程包括优化数据库结构和索引、文件缓存(I/O优化)、以及Memcache缓存服务器的引入。同时,存储引擎也进行了升级,从使用表锁机制的MyISAM引擎转向支持事务且并发性能更高的InnoDB引擎。
3. 分库分表 + 水平拆分 + MySQL集群阶段
随着业务的不断扩展,垂直拆分已不足以应对需求,水平拆分成为了必要选择:
- 水平分片策略: 根据业务维度或数据特性进行分片,每个集群存储部分数据,实现负载均衡;
- 分库分表方案: 从单库单表逐步演进到单库多表再到多库多表,通过路由规则将数据分散到不同的数据库实例中,解决了分布式事务和跨库查询等技术挑战。
4. NoSQL的兴起
进入大数据时代,传统的关系型数据库面临新的挑战,具体表现为:
- 数据结构动态变化: 快速迭代的业务环境导致字段频繁增减,关系型数据库的固定模式难以适应;
- 数据类型多样化: 需要存储文档、图片、日志、社交关系等多种非结构化数据;
- 横向扩展需求: 面对数据量的指数级增长,需要更加灵活的扩展能力。
因此,现代互联网架构转变为多元化的数据存储解决方案,结合关系型数据库、文档数据库、KV存储、文件服务器和图数据库等技术,以适应不同类型的数据存储需求。
MySQL与Redis的技术对比及协同实践
MySQL和Redis是两种截然不同的数据库系统,在技术特性上有着根本的区别:
| 对比维度 | MySQL (InnoDB) | Redis |
|---|---|---|
| 数据存储 | 磁盘存储,持久化为主 | 内存存储,可选持久化 |
| 数据结构 | 结构化表格(行列) | 丰富数据类型(String/Hash/List/Set/ZSet) |
| 数据模型 | 关系型,强Schema | KV型,无Schema |
| 查询能力 | 强大的SQL,支持复杂查询和JOIN | 简单的Key查询,不支持JOIN |
| 事务支持 | 完整ACID事务,多种隔离级别 | 有限事务支持(MULTI/EXEC) |
| 性能特点 | QPS:万级,受磁盘I/O限制 | QPS:10万+级,内存速度 |
| 响应延迟 | 毫秒至几十毫秒级 | 微秒至毫秒级 |
| 数据持久化 | 天然持久化,Redo Log保证 | 可选RDB快照或AOF日志 |
| 容量限制 | TB级,受磁盘容量限制 | GB至TB级,受内存容量限制 |
| 扩展方式 | 垂直扩展+分库分表(复杂) | 主从复制+集群分片(简单) |
| 数据一致性 | 强一致性 | 最终一致性(主从异步复制) |
根据这些特点,MySQL适用于存储核心业务数据,而Redis则更适合用作热点数据缓存,提供高性能的读写服务。
Redis作为MySQL缓存层的架构模式
以下是几种常见的Redis作为MySQL缓存层的架构模式:
1. Cache-Aside模式(旁路缓存)
这是最常见的缓存模式,应用程序直接与缓存和数据库交互:
读取流程:
应用请求 → 查询Redis
↓
命中?
↙ ↘
是 否
↓ ↓
返回数据 查询MySQL
↓
写入Redis
↓
返回数据更新流程:
应用更新 → 更新MySQL
↓
删除Redis缓存
↓
返回成功优点包括应用逻辑清晰、缓存失效策略灵活、缓存故障不影响数据库访问,特别适合读多写少的场景。缺点则是首次请求必然缓存未命中(冷启动问题),且需要应用层处理缓存逻辑,可能导致代码侵入性强,还可能产生短暂的数据不一致。
典型代码模式:
public User getUser(Long userId) {
// 1. 查询Redis
String cacheKey = "user:" + userId;
User user = redis.get(cacheKey);
if (user != null) {
return user; // 缓存命中
}
// 2. 缓存未命中,查询MySQL
user = userMapper.selectById(userId);
if (user != null) {
// 3. 写入Redis,设置过期时间
redis.setex(cacheKey, 3600, user);
}
return user;
}
public void updateUser(User user) {
// 1. 更新MySQL
userMapper.updateById(user);
// 2. 删除缓存
String cacheKey = "user:" + user.getId();
redis.del(cacheKey);
}2. Read-Through / Write-Through模式
在这种模式下,缓存层统一管理数据的读写,应用层仅与缓存交互:
- Read-Through特点: 应用只从缓存读取数据,缓存负责从数据库加载数据,对应用透明,简化业务逻辑;
- Write-Through特点: 应用只写入缓存,缓存同步写入数据库,确保缓存和数据库的一致性。
优点包括应用逻辑简单、无需关注数据源、缓存层统一管理便于优化、数据一致性更好。缺点是写入延迟较高(同步写数据库)、缓存层需要更复杂的实现,通常需要中间件的支持。
3. Write-Behind模式(异步写入)
在此模式下,写入操作首先更新缓存,然后异步批量写入数据库:
工作原理:
应用写入 → 更新Redis
↓
立即返回成功
↓
后台异步任务 → 批量写入MySQL其优点是写入性能极高,响应时间短,适合高并发写入场景。缺点则包括写入延迟较高、缓存层实现复杂等。
数据缓存与优化策略
Redis相关问题及解决方案
数据可能丢失(Redis故障):当Redis发生故障时,可能会导致数据丢失。这是因为Redis的数据主要存储在内存中,虽然可以通过配置持久化选项来减少这种风险,但在某些情况下仍然难以完全避免。
数据一致性最弱:Redis的设计使得它在数据一致性方面表现较弱,尤其是在分布式环境中,实现高一致性需要额外的机制和技术支持。
实现复杂,需要考虑失败重试:在使用Redis时,为了确保数据的一致性和可靠性,通常需要实现复杂的逻辑,包括失败重试机制,这增加了系统的复杂性。
适用场景
- 计数器、统计数据等对一致性要求不高的场景
- 高并发写入,如点赞、浏览量更新
- 日志、埋点数据收集
缓存一致性问题及其解决策略
1. 缓存更新策略对比
策略一:先删除缓存,再更新数据库
线程A:删除缓存 → 更新数据库
线程B: 查询缓存未命中 → 查询数据库(旧值)→ 写入缓存问题:线程B可能将旧值写入缓存,导致长时间的数据不一致。
策略二:先更新数据库,再删除缓存
线程A:更新数据库 → 删除缓存
线程B:查询缓存未命中 → 查询数据库(新值)→ 写入缓存问题:如果删除缓存失败,会导致数据不一致。
推荐方案:先更新数据库,再删除缓存(配合重试机制),以确保数据的一致性。
2. 延迟双删策略
针对“先更新数据库,再删除缓存”的并发问题优化:
public void updateWithDelayedDoubleDelete(Long id, User user) {
// 1. 删除缓存
String key = "user:" + id;
redis.del(key);
// 2. 更新数据库
userMapper.updateById(user);
// 3. 延迟后再次删除缓存
scheduledExecutor.schedule(() -> {
redis.del(key);
}, 500, TimeUnit.MILLISECONDS);
}原理:
第一次删除:清除旧缓存
更新数据库:持久化新数据
延迟删除:清除并发读导致的旧缓存
延迟时间选择:应大于数据库主从同步延迟,应大于一次查询的耗时,通常设置为500ms-1s。
3. 缓存穿透解决方案
问题描述:查询不存在的数据时,缓存无法命中,持续访问数据库。
解决方案一:缓存空值
public User getUser(Long userId) {
String key = "user:" + userId;
User user = redis.get(key);
if (user != null) {
return user.getId() == null ? null : user; // 空对象标识
}
user = userMapper.selectById(userId);
if (user == null) {
// 缓存空值,设置较短过期时间
redis.setex(key, 60, new User()); // 空对象
} else {
redis.setex(key, 3600, user);
}
return user;
}解决方案二:布隆过滤器
// 初始化布隆过滤器
BloomFilter<long> bloomFilter = BloomFilter.create(
Funnels.longFunnel(),
10000000, // 预期数据量
0.01 // 误判率
);
// 启动时加载所有存在的ID
List<long> allUserIds = userMapper.selectAllIds();
allUserIds.forEach(bloomFilter::put);
public User getUser(Long userId) {
// 先判断是否可能存在
if (!bloomFilter.mightContain(userId)) {
return null; // 一定不存在
}
// 正常缓存逻辑
return getUserWithCache(userId);
}
</long></long>方案对比:
缓存空值:实现简单,但会占用缓存空间。
布隆过滤器:节省空间,但存在误判,维护成本较高。
4. 缓存击穿解决方案
问题描述:热点数据过期瞬间,大量请求直接访问数据库。
解决方案一:互斥锁
public User getUser(Long userId) {
String key = "user:" + userId;
User user = redis.get(key);
if (user != null) {
return user;
}
// 获取互斥锁
String lockKey = "lock:" + key;
boolean locked = redis.setnx(lockKey, "1", 10);
if (locked) {
try {
// 再次检查缓存(双重检查)
user = redis.get(key);
if (user != null) {
return user;
}
// 查询数据库
user = userMapper.selectById(userId);
// 写入缓存
if (user != null) {
redis.setex(key, 3600, user);
}
return user;
} finally {
redis.del(lockKey);
}
} else {
// 等待后重试
Thread.sleep(50);
return getUser(userId);
}
}解决方案二:热点数据永不过期
public User getUser(Long userId) {
String key = "user:" + userId;
String value = redis.get(key);
if (value != null) {
CacheValue cacheValue = JSON.parse(value);
// 检查逻辑过期时间
if (cacheValue.getExpireTime() > System.currentTimeMillis()) {
return cacheValue.getData();
} else {
// 异步更新缓存
executorService.submit(() -> refreshCache(userId));
// 返回旧数据
return cacheValue.getData();
}
}
// 缓存未命中,同步加载
return loadAndCache(userId);
}5. 缓存雪崩解决方案
问题描述:大量缓存同时过期,或Redis宕机,导致数据库压力骤增。
解决方案:
(1)过期时间随机化
// 基础过期时间 + 随机值
int baseExpire = 3600;
int randomExpire = new Random().nextInt(300); // 0-300秒
redis.setex(key, baseExpire + randomExpire, value);(2)Redis高可用架构
Redis Sentinel(哨兵模式)
↓
主从自动切换
↓
Redis Cluster(集群模式)
↓
数据分片 + 高可用(3)多级缓存降级
public User getUser(Long userId) {
// L1: 本地缓存
User user = localCache.get(userId);
if (user != null) return user;
// L2: Redis缓存
try {
user = redis.get("user:" + userId);
if (user != null) {
localCache.put(userId, user);
return user;
}
} catch (Exception e) {
log.error("Redis异常,降级到数据库", e);
}
// L3: 数据库 + 限流
return rateLimiter.execute(() -> {
user = userMapper.selectById(userId);
// 尝试写回缓存
tryWriteCache(userId, user);
return user;
});
}(4)熔断降级
@HystrixCommand(fallbackMethod = "getUserFallback")
public User getUser(Long userId) {
return getUserWithCache(userId);
}
public User getUserFallback(Long userId) {
// 降级逻辑:返回默认值或从备用数据源获取
return defaultUserService.getUser(userId);
}Canal binlog订阅方案
架构设计:
MySQL Binlog → Canal Server → MQ (Kafka/RocketMQ)
↓
Canal Client
↓
更新/删除Redis缓存性能对比数据:
| 操作类型 | MySQL (InnoDB) | Redis (单实例) | 性能提升 |
|---|---|---|---|
| 简单主键查询 | 1-2万 QPS | 10-15万 QPS | 10倍 |
| 批量读取 | 5000-8000 QPS | 5-8万 QPS | 8倍 |
| 写入操作 | 8000-1.2万 QPS | 8-12万 QPS | 8倍 |
| 事务操作 | 3000-5000 TPS | 1-2万 TPS | 4倍 |
响应延迟对比:
| 操作类型 | MySQL | Redis | 延迟降低 |
|---|---|---|---|
| 单条查询 | 5-20ms | 0.1-1ms | 10-100倍 |
| 批量查询(100条) | 50-100ms | 1-5ms | 20-50倍 |
| 写入操作 | 5-15ms | 0.1-1ms | 10-50倍 |
并发能力对比:在高并发场景下(1000并发):
MySQL:响应时间快速上升,从10ms增长到100ms+,连接池容易耗尽。
Redis:响应时间保持稳定,1ms左右,轻松支持10万+并发。
实际案例数据:某电商平台商品详情页优化:
优化前(纯MySQL):平均响应150ms,峰值QPS 3000
优化后(Redis缓存):平均响应8ms,峰值QPS 50000+
缓存命中率:95%以上
数据库负载:降低90%
架构最佳实践总结
分层缓存策略:
请求流量
↓
本地缓存(Caffeine)- 容量小,速度极快
↓ (miss)
Redis缓存 - 容量中等,速度快
↓ (miss)
MySQL数据库 - 容量大,速度相对慢
↓
返回结果并逐层回写缓存核心原则:
热点数据优先缓存:遵循二八原则,20%的数据承载80%的访问。
合理的过期时间:根据数据变化频率设置TTL。
监控和告警:关注缓存命中率、响应时间、错误率。
降级和限流:在缓存故障时提供兜底方案。
数据预热:系统启动时加载热点数据。
NoSQL四大分类详解
KV键值对数据库
典型代表:Redis、Memcached
核心特性:
最简单的数据模型:Key-Value映射。
极高的读写性能,支持百万级QPS。
丰富的数据结构:String、Hash、List、Set、Sorted Set。
支持数据持久化(Redis)。
应用场景:
缓存系统:Session存储、页面缓存。
计数器:访问统计、点赞数。
消息队列:简单的发布订阅。
分布式锁:基于SETNX的锁实现。
技术特点:
Redis采用单进程单线程模型(6.0后支持多线程IO)。
内存存储,性能极致。
支持主从复制、哨兵、集群等高可用方案。
文档型数据库
典型代表:MongoDB、CouchDB
核心特性:
存储JSON/BSON格式的文档。
灵活的Schema设计,字段可动态扩展。
支持复杂查询和聚合操作。
介于关系型和非关系型数据库之间。
MongoDB技术亮点:
基于C++编写,性能优秀。
分布式文件存储,易于扩展。
支持丰富的查询语言和索引类型。
内置Sharding支持,自动数据分片。
应用场景:
内容管理系统:文章、评论、用户UGC内容。
日志分析:存储和查询大量日志数据。
实时分析:用户行为分析、推荐系统。
移动应用后端:用户配置、游戏数据。
适用条件:
表结构不明确且持续变化。
数据量大且增长快速。
需要高可用和水平扩展。
不需要复杂的事务支持。
不适用场景:
需要强事务一致性的业务。
需要复杂JOIN查询的场景。
数据关系复杂的业务系统。
列存储数据库
典型代表:HBase、Cassandra、Bigtable
核心特性:
按列存储数据,而非按行。
适合海量数据的分布式存储。
高效的数据压缩能力
支持PB级数据量
技术架构
基于LSM树(Log-Structured Merge-Tree)的写优化设计,支持高吞吐写入。采用最终一致性模型,支持列族(Column Family)概念。
应用场景
- 大数据分析:用户行为分析、广告投放
- 时序数据:监控指标、物联网数据
- 消息系统:存储海量消息记录
- 推荐系统:特征存储、模型数据
图关系数据库
典型代表包括Neo4j和JanusGraph。
核心特性
- 以图结构存储数据:节点(Node)和关系(Relationship)
- 高效的关系查询和图遍历
- 支持复杂的图算法
- 适合多度关系查询
技术亮点
- 图的深度优先和广度优先遍历
- 最短路径、PageRank等图算法
- ACID事务支持(Neo4j)
- 灵活的属性图模型
应用场景
- 社交网络:好友关系、社交推荐
- 知识图谱:实体关系、智能问答
- 风控系统:关系挖掘、欺诈检测
- 推荐引擎:基于图的协同过滤
技术选型指南
NoSQL适用场景
- 数据结构动态变化:当业务需求快速变化,数据模型无法预先确定时,MongoDB的无Schema特性允许灵活增减字段,无需ALTER TABLE操作,零停机时间,适合敏捷开发和快速迭代。
- 高写入负载:对于日志、监控、用户行为等高频写入场景,MongoDB侧重写入性能,而非事务安全;HBase支持海量数据的高吞吐写入;Redis提供极致的内存写入速度。
- 海量数据存储:当数据量超过单机MySQL的处理能力,MongoDB内置Sharding,易于水平扩展;HBase支持PB级数据存储,比MySQL分库分表方案更易维护。
- 高可用需求:对于7×24小时不间断服务的系统,MongoDB副本集提供自动故障转移;Redis哨兵/集群保证高可用;Cassandra无单点故障的P2P架构。
关系型数据库适用场景
- 强事务一致性需求:金融、支付、订单等核心业务系统,ACID事务保证数据一致性,支持复杂的事务隔离级别,严格的数据完整性约束。
- 复杂查询需求:需要多表关联、聚合、子查询的场景,强大的SQL查询能力,优化器自动选择最优执行计划,丰富的索引类型支持。
- 数据关系复杂:实体间存在多对多、复杂关联关系,外键约束保证引用完整性,JOIN操作处理关联查询,视图简化复杂查询逻辑。
- 数据量可控:单表数据量在千万级以内,增长可预测,MySQL在合理数据量下性能优秀,运维成熟,工具生态完善,开发人员技术栈成熟。
NoSQL与SQL协同架构
现代互联网架构通常采用多数据库协同方案:
分层存储策略
- 热数据:Redis缓存,毫秒级响应
- 温数据:MySQL存储核心业务数据
- 冷数据:MongoDB/HBase存储归档数据
读写分离策略
- 写操作:MySQL主库,保证事务一致性
- 读操作:MySQL从库 + Redis缓存,提升并发能力
- 复杂查询:Elasticsearch,支持全文检索和聚合分析
业务写入 → MySQL主库 → Binlog → 数据同步
↓
Redis缓存更新
↓
MongoDB/ES异步同步性能优化原则
缓存策略
- 多级缓存:本地缓存 + 分布式缓存
- 缓存预热:系统启动时加载热点数据
- 缓存穿透防护:布隆过滤器
- 缓存雪崩防护:随机过期时间
连接池管理
- 合理设置最大连接数和最小空闲连接数
- 配置连接超时和空闲超时
- 监控连接池使用情况
- 使用连接池的连接复用机制
监控与诊断
- 实时监控:QPS、TPS、响应时间
- 慢查询分析:定期优化慢查询
- 资源监控:CPU、内存、磁盘IO、网络
- 告警机制:及时发现性能瓶颈
总结
数据库技术的演进是互联网业务发展的必然结果。从单机MySQL到分布式NoSQL,每一次架构升级都是为了应对更大的数据量、更高的并发、更复杂的业务需求。
没有万能的数据库:MySQL和NoSQL各有优劣,应根据具体场景选择。
性能取决于场景:压测结果表明,查询性能更多取决于查询模式和数据量,而非数据库类型。
多数据库协同:现代架构通常采用MySQL + Redis + MongoDB等多数据库组合方案。
持续优化迭代:数据库选型不是一次性决策,需要根据业务发展持续优化。
技术选型建议
- 核心交易系统:MySQL,保证ACID特性和数据一致性
- 缓存系统:Redis,提供极致性能
- 日志分析系统:MongoDB/HBase,支持海量数据和灵活查询
- 社交关系系统:图数据库,高效处理复杂关系查询
- 全文检索:Elasticsearch,提供强大的搜索和分析能力
随着技术的不断发展,NewSQL(如TiDB、CockroachDB)正在尝试结合SQL和NoSQL的优势,提供分布式事务和水平扩展能力。

 京公网安备 11010802022788号
京公网安备 11010802022788号







