


 雷达卡
雷达卡



选题意义背景
随着互联网技术的飞速进步,Web应用已深度融入人们的日常生活与工作场景。从电子商务到远程医疗,再到在线教育,各类Web服务正发挥着不可替代的作用,全球范围内的Web应用数量也呈现出爆炸式增长。传统的恶意HTTP请求检测手段多依赖规则匹配和黑名单机制,尽管这类方法实现简便,但其局限性显著:难以应对新型攻击、泛化能力弱、维护成本高。
近年来,机器学习与深度学习技术的兴起为恶意HTTP请求的识别提供了全新的解决方案。相较于传统方式,基于机器学习的方法具备自学习能力,能够从海量历史数据中自动挖掘出潜在的攻击模式,无需人工设定复杂规则;同时,这些模型在面对未知攻击时表现出更强的适应性和检测能力,具有更高的泛化性能。
然而,当前研究仍面临若干挑战:首先,HTTP请求的数据特征表示方式直接影响模型最终的判别效果,如何高效提取其中的关键语义信息成为核心问题之一;其次,不同类型的模型各有优劣,单一模型往往难以全面覆盖多样化的攻击形态;最后,提升系统对未见攻击类型的识别能力,增强整体鲁棒性,仍是亟待突破的方向。
针对上述问题,本研究致力于探索更高效的恶意HTTP请求检测机制,提出优化的特征表达策略与融合型检测架构,旨在提升系统的准确率与泛化能力。研究将从HTTP请求的数据解析出发,深入分析统计特征、加权向量及词嵌入矩阵等多元特征表示方法,构建高精度的检测体系,实现对恶意行为的精准识别。
数据集
数据获取
本研究所采用的核心数据集为HTTP DATASET CSIC 2010,该数据集由西班牙计算机科学研究所(CSIC)构建,是在一个真实部署的Web应用程序上通过自动化脚本采集而成。研究人员模拟了正常用户操作行为以及多种典型的攻击行为,生成了一个包含正常流量与恶意请求的混合样本集。我们通过CSIC官方网站及主流学术资源平台获取了该数据集的完整版本,确保数据来源的权威性与实验基础的可靠性。
该数据集以纯文本格式存储,每条记录对应一条完整的HTTP请求,涵盖请求头和请求体的全部内容。整体规模较大,共包含约61,000条正常请求和超过25,000条恶意请求。恶意样本覆盖了多种常见Web攻击类型,包括SQL注入、跨站脚本(XSS)、缓冲区溢出、信息泄露、本地/远程文件包含(LFI/RFI)、参数篡改、操作系统命令注入等,具备良好的多样性和代表性,适合用于训练和评估检测模型。
数据类别定义
在本研究中,所有HTTP请求被划分为两大基本类别:正常请求与恶意请求。其中,恶意请求进一步细分为以下几类典型攻击:
- SQL注入攻击:通过在请求参数中插入恶意SQL语句,诱导数据库执行非授权操作,可能导致敏感数据泄露、篡改甚至服务器权限失控。
- 跨站脚本攻击(XSS):在输入字段中嵌入恶意JavaScript代码,当其他用户访问受影响页面时,脚本在其浏览器中执行,可能引发会话劫持或隐私窃取。
- 操作系统命令注入(OS_COMMAND):利用程序漏洞,在请求中传入系统级命令,诱使服务器执行任意指令,从而获取控制权或进行破坏性操作。
- 文件包含攻击(LFI/RFI):借助Web应用中的动态文件加载功能,通过构造特殊路径参数,尝试读取本地敏感文件或加载并执行远程恶意脚本。
为了保障模型训练的有效性与评估结果的客观性,我们遵循标准实践,将整个数据集按照一定比例划分为训练集、验证集和测试集三个独立子集,确保各阶段数据互不重叠且分布均衡。
功能模块介绍
本研究设计的恶意HTTP请求检测系统由多个协同运作的功能模块构成,涵盖从原始数据接入到最终分类决策的全流程处理环节。主要模块包括:数据采集与预处理、特征表示、检测模型构建及算法融合策略等。
数据采集与预处理
作为整个检测流程的基础支撑模块,数据采集与预处理负责从多种渠道获取原始HTTP请求数据,并将其转化为可用于建模的标准格式。该模块主要包括以下几个关键功能:
- 数据采集功能:支持从Web服务器日志、网络抓包工具(如Wireshark、tcpdump)或公开基准数据集中导入HTTP请求流。系统设计了可扩展的数据接口层,能灵活适配不同来源的数据结构。
- 数据清洗功能:对原始数据进行去噪处理,剔除无效请求、格式错误条目以及重复记录,提升后续分析的数据质量。
- 数据标准化功能:统一不同来源的数据格式,执行URL解码、字符转小写、特殊符号规范化等操作,减少格式差异对模型造成的影响。
- 特征提取功能:依据选定的特征表示方法,从原始请求中抽取出可用特征。例如,对于统计特征,计算请求长度、参数数量、特殊字符频率等指标;对于文本序列特征,则进行分词、编码与序列化处理。
在实现过程中,本模块采用模块化编程思想,将各项预处理操作封装为独立函数或类,便于后期维护与功能拓展。此外,针对大规模数据处理需求,系统引入了并行计算机制,充分利用多核处理器资源,显著提升了预处理效率。
特征表示模块
特征表示是连接原始数据与检测模型的关键桥梁。本研究综合运用多种特征提取技术,构建多层次、多维度的输入表示空间,具体包括:
- 基于请求结构的统计特征(如URL长度、参数个数、特殊符号密度)
- 基于文本内容的TF-IDF权重向量
- 基于语义理解的Word2Vec词嵌入矩阵
通过组合不同类型特征,增强模型对语义异常与结构异常的感知能力。
检测模型模块
检测模型模块是系统的核心决策单元,负责根据输入特征判断请求是否为恶意。本研究构建了基于深度神经网络的复合模型结构,结合双向长短期记忆网络(Bi-LSTM)与注意力机制(Attention),充分捕捉HTTP请求中的上下文依赖关系与时序特征。
算法理论
特征选择算法
为降低特征维度、提高模型训练效率并避免噪声干扰,本研究采用特征选择技术筛选最具判别力的特征子集。通过卡方检验、互信息法等方式评估各特征与标签的相关性,保留贡献度高的特征用于建模。
TF-IDF权重计算算法
TF-IDF(Term Frequency-Inverse Document Frequency)用于衡量词语在单个请求文档中的重要程度。通过对HTTP请求内容进行分词后,计算每个词项的TF-IDF值,形成固定长度的稀疏向量表示,适用于浅层分类模型输入。
Word2Vec词嵌入算法
采用Word2Vec模型将HTTP请求中的词汇映射到低维稠密向量空间,保留词语间的语义相似性。使用Skip-gram架构在大量请求文本上进行无监督训练,获得通用词向量,供后续深度模型调用。
双向长短期记忆网络
Bi-LSTM能够同时捕捉序列前后两个方向的信息流动,特别适合处理HTTP请求这种具有明显顺序结构的文本数据。通过前向和后向LSTM层的联合输出,模型可更全面地理解请求语义。
注意力机制
引入注意力机制使模型能够在处理长序列时聚焦于关键部分(如可疑参数或payload片段),动态分配权重,提升对局部异常的敏感度。
混合模型融合策略
为充分发挥各类模型优势,本研究设计了一种多模型集成框架,将基于传统特征的SVM模型、TF-IDF+全连接网络与Bi-LSTM+Attention深层架构进行加权融合,提升整体检测性能与稳定性。
核心代码
改进的TF-IDF权重计算
在传统TF-IDF基础上引入位置加权因子与攻击关键词增强策略,提升对敏感字段(如'union select'、'script'等)的关注度,增强特征表达能力。
Bi-LSTM-AP模型
“AP”代表Attention Pooling,即在Bi-LSTM输出层后接入注意力池化模块,自动学习各时间步的重要性权重,并生成更具代表性的上下文向量作为最终特征表示。
混合检测模型
整合多种异构模型输出结果,采用软投票或堆叠(Stacking)方式进行决策融合,有效平衡偏差与方差,提高整体泛化能力。
重难点和创新点
研究难点
- HTTP请求数据高度异构,包含结构化与非结构化信息,特征提取难度大。
- 恶意样本种类繁多且不断演化,模型需具备较强的迁移与泛化能力。
- 真实环境中存在大量噪声数据,如何提升模型鲁棒性是一大挑战。
- 深度模型训练耗时较长,需在性能与效率之间做出权衡。
创新点
- 提出一种融合统计特征、改进TF-IDF与词嵌入的多粒度特征表示方法。
- 构建Bi-LSTM与注意力机制相结合的深度检测模型(Bi-LSTM-AP),增强对关键片段的识别能力。
- 设计混合模型融合策略,集成多种模型优势,提升整体检测准确率与稳定性。
- 在公开数据集上完成端到端实验验证,证明所提方法的有效性与实用性。
总结
本研究围绕恶意HTTP请求检测这一网络安全关键问题,系统性地探讨了基于机器学习的检测方法。通过构建包含数据预处理、特征工程、深度建模与模型融合的完整技术链条,提出了一系列优化方案。实验结果表明,所提出的特征表示方法与混合检测模型在准确率、召回率和F1分数等指标上均优于传统方法,具备较强的实际应用潜力。未来将进一步探索轻量化部署、实时检测与对抗样本防御等方向。
参考文献
[1] San Francisco State University. HTTP DATASET CSIC 2010 Documentation.
[2] Mikolov T, et al. Distributed representations of words and phrases and their compositionality. NIPS 2013.
[3] Hochreiter S, Schmidhuber J. Long short-term memory. Neural Computation, 1997.
[4] Bahdanau D, et al. Neural machine translation by jointly learning to align and translate. ICLR 2015.
[5] Pedregosa F, et al. Scikit-learn: Machine Learning in Python. JMLR, 2011.
特征表示模块
该模块的核心功能是将经过预处理的HTTP请求数据转化为适合机器学习模型使用的数值型特征。为适应不同场景下的检测需求,本模块集成了三种互补的特征表示方法,分别为统计特征、权重向量和词嵌入矩阵表示方式。
词嵌入矩阵表示子模块
采用Word2Vec算法对HTTP请求中的词汇进行分布式表示,生成固定维度的词嵌入矩阵。通过训练语料学习词语之间的语义关联,有效保留请求内容的上下文信息。对于未在词表中出现的词汇(即未登录词),使用服从均匀分布的随机向量进行初始化。同时,对序列长度执行统一的截断或补零操作,确保所有输入具有相同的维度结构。
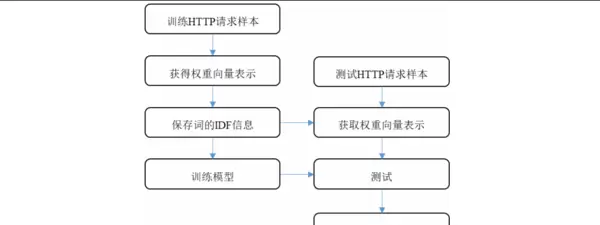
统计特征表示子模块
从HTTP请求中提取多种统计性指标,包括但不限于请求体长度、URL长度、参数部分长度以及特殊字符的数量等。共设计21类基础统计特征,并引入基于决策树的特征选择机制对其重要性进行排序。最终筛选出贡献度最高的13个特征作为模型输入,剔除冗余信息,在提升分类性能的同时优化训练效率。通过对各类特征区分正常与恶意请求能力的分析,实现了特征空间的有效压缩。

权重向量表示子模块
利用TF-IDF技术构建HTTP请求的加权词向量。首先建立训练集的全局词典,随后计算每个词的词频(TF)与逆文档频率(IDF),进而得出其综合权重并形成稀疏向量表示。此方法强调那些在个别请求中高频出现但在整体中低频的关键词,从而增强其在特征空间中的表达力。针对恶意请求的特点,提出了一种改进策略:将常见于攻击载荷但罕见于正常流量的敏感词归并为统一标识符进行权重计算,进一步强化恶意模式的可辨识度。

整体上,特征表示模块综合考虑了各类表示方法的优势,提供了多样化且高判别性的输入特征,显著增强了后续检测模型的适应性和识别精度。
检测模型模块
作为系统的核心组件,检测模型模块负责依据前述特征表示结果对HTTP请求进行分类判断,识别其是否属于恶意行为。该模块不仅实现了多种经典算法,还提出了两项创新架构以应对复杂攻击形态。
传统机器学习模型子模块
集成了一系列经典的监督学习算法,包括逻辑回归(LR)、支持向量机(SVM)、K近邻(KNN)、决策树(DT)及随机森林(RF)。各模型均以标准化后的特征向量作为输入,通过交叉验证方式进行超参数调优,选取最优配置。在此基础上,对比各算法在准确率、召回率和F1值等方面的综合表现,确定最适合当前任务的基准模型。
Bi-LSTM-AP模型子模块
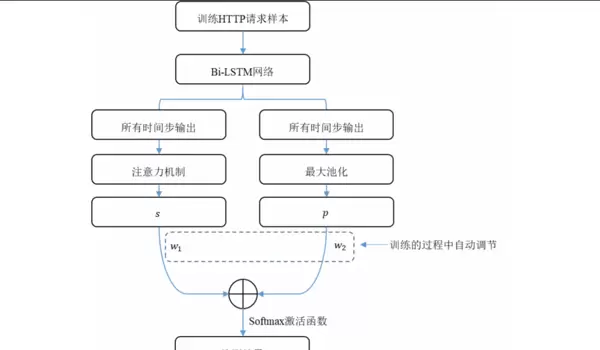
设计并实现一种融合注意力机制与池化策略的双向长短期记忆网络(Bi-LSTM-AP)。该模型首先通过Bi-LSTM层分别从前向和后向捕捉词嵌入序列中的长期依赖关系。在此基础上,引入两种特征提取分支:
- Bi-LSTM-A:基于注意力机制,动态分配不同时间步输出的重要性权重,突出关键语义片段;
- Bi-LSTM-P:采用最大池化操作,提取最具代表性的局部特征。
最后将两路特征融合,构成最终的分类依据。该结构兼顾了上下文完整性与关键信息聚焦,显著提升了对隐蔽攻击的识别能力。
检测模型模块充分融合了传统机器学习与深度学习的前沿成果,并结合恶意HTTP请求的特性进行了针对性优化,提出了更具鲁棒性和泛化能力的模型架构与集成策略。
算法理论
特征选择算法
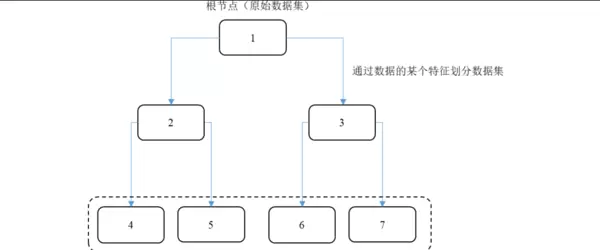
特征选择旨在从原始高维特征集中挑选最具判别力的子集,以降低计算开销并提升模型泛化性能。本研究采用基于决策树的特征选择方法,利用基尼不纯度衡量各特征在划分过程中的贡献程度。决策树通过递归分割数据集,依据各特征取值构建分支结构,其内部节点分裂过程自然反映出特征的重要程度,从而支持高效且可解释的特征筛选。
TF-IDF权重计算算法
TF-IDF是一种广泛应用于文本分析的统计方法,用于评估某个词在文档中的相对重要性。其基本假设是:若一个词在某篇文档中频繁出现,而在其他文档中较少出现,则该词对该文档具有较强的代表性。在本系统中,该算法被用于生成HTTP请求的词权重向量。
为进一步适配安全检测场景,本文提出一种改进版TF-IDF计算方式:通过分别统计正常请求与恶意请求中高频出现的词汇,将那些在恶意样本中频繁出现而正常样本中极少出现的关键词映射至同一虚拟词项,并统一计算其权重。此举有助于放大恶意语义信号,提升模型对潜在威胁的敏感度。

Word2Vec词嵌入算法
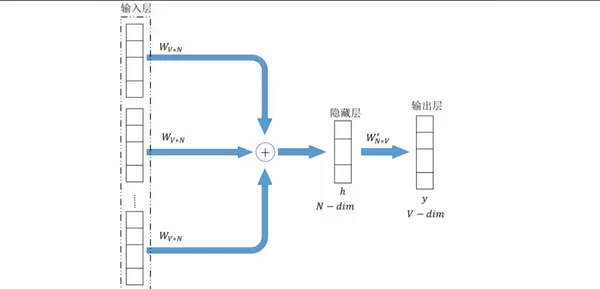
Word2Vec是一种基于神经网络的词表示模型,能够将离散词汇映射到连续向量空间中,从而捕捉词语间的语义相似性与语法关系。本研究选用其中的CBOW(Continuous Bag-of-Words)模型来生成HTTP请求的词向量表示。
CBOW模型的结构包含三个主要层次:
- 输入层:将目标词周围C个上下文词转换为one-hot编码形式;
- 隐藏层:通过权重矩阵将one-hot向量投影为低维稠密向量,并对这些向量求平均;
- 输出层:利用softmax函数将隐藏层输出转化为词汇表中各词的概率分布,用于预测中心词。
该模型通过大规模语料训练,能够在无监督条件下学习到丰富的语义特征,为后续检测任务提供高质量的输入表示。
在模型训练阶段,CBOW通过最小化预测词汇与真实词汇之间的误差来不断调整和更新权重矩阵。当训练过程完成后,从输入层到隐藏层的权重矩阵即可作为词嵌入矩阵使用,其中矩阵的每一行代表一个词语对应的词向量。利用Word2Vec生成HTTP请求的词嵌入表示,主要包含以下几个步骤:
- 对原始HTTP请求进行分词处理,将其转化为由词语组成的有序序列。
- 采用CBOW模型进行词向量训练,并设置合适的超参数,例如词向量维度、上下文窗口大小等。
- 将HTTP请求中的每一个词映射为其对应的词向量,从而构建出整个请求的词嵌入序列。
- 对生成的词嵌入序列执行截断或填充操作,确保所有请求的序列长度统一。
借助Word2Vec算法,能够将非结构化的HTTP请求转换为富含语义信息的词嵌入矩阵,为后续深度学习模型提供更具表达力的特征输入。
长短期记忆网络(LSTM)是循环神经网络(RNN)的一种特殊形式,其核心优势在于引入了门控机制,有效缓解了传统RNN在处理长序列时易出现的梯度消失问题。在此基础上,双向长短期记忆网络(Bi-LSTM)进一步扩展了LSTM的能力,由前向LSTM和后向LSTM共同组成,能够同时捕捉序列数据中前后两个方向的信息依赖关系。
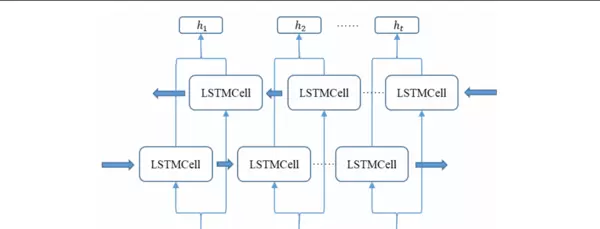
在实际运行过程中,Bi-LSTM将输入序列分别送入前向和后向的LSTM单元中进行处理,最终将两者的输出结果拼接在一起形成综合表示。这种结构使得模型可以全面捕获HTTP请求中词语之间的正向与反向语义关联,增强对整体请求语义的理解能力,进而提升恶意请求检测的准确性。
注意力机制模拟了人类视觉注意力的选择性行为,能够根据输入内容的重要性动态分配不同的关注权重,突出关键信息。本研究将该机制应用于Bi-LSTM的输出层,提出了Bi-LSTM-A模型。通过引入注意力机制,模型可自动识别在时间步上更为重要的特征输出,并赋予更高的权重,从而更有效地聚焦于HTTP请求中的敏感部分,显著提升检测性能。
池化作为一种常见的降维手段,通过对局部区域的数据进行聚合操作来提取关键特征并降低数据维度。本研究采用了最大池化策略作用于Bi-LSTM的输出,由此构建了Bi-LSTM-P模型。最大池化的基本原理是在每个局部区域内选取最大值作为代表输出。这种方法可以从Bi-LSTM产生的序列特征中提取最具判别性的元素,这些高响应特征往往对于区分正常流量与攻击行为具有重要意义。同时,最大池化还能有效抑制无关噪声,增强模型的鲁棒性。

混合模型融合策略
为了进一步提升检测效果,本研究设计了一种基于加权求和的混合模型融合方法,整合多个基础模型的优势以获得更优的整体表现。具体而言,我们将基于权重向量的随机森林模型与基于词嵌入的Bi-LSTM-AP模型的预测结果进行融合,流程如下:
- 分别独立训练各个基础模型,并在验证集上评估其分类性能。
- 设定融合权重w1和w2,满足约束条件:w1 + w2 = 1。
- 针对新的HTTP请求样本,分别调用两个模型进行预测,得到各自的输出结果M(来自随机森林)和D(来自Bi-LSTM-AP)。
- 计算混合模型的最终预测输出:Result = w1 × M + w2 × D。
- 在验证集上进行权重搜索,寻找使整体性能最优的最佳权重组合。
实验结果表明,当融合权重配置为0.3:0.7(即随机森林占0.3,Bi-LSTM-AP占0.7)时,混合模型达到最佳检测性能。该策略充分发挥了两种模型的互补优势:随机森林在识别恶意请求方面表现出色,而Bi-LSTM-AP则在判断正常请求上更为精准,二者结合实现了更均衡且高效的检测能力。
核心代码实现
改进的TF-IDF权重计算方法
为提升对恶意HTTP请求的识别能力,本文提出一种改进的TF-IDF权重计算方式。该方法通过将频繁出现在恶意请求但极少出现在正常请求中的关键词统一替换为特定标记,从而强化恶意语义特征的表达,使恶意模式更加突出。
def improved_tfidf_calculation(train_data, malicious_keywords):
"""
改进的TF-IDF权重计算方法
参数:
train_data: 训练数据,包含正常请求和恶意请求
malicious_keywords: 恶意请求中常见而正常请求中不常见的关键词列表
返回:
tfidf_vectorizer: 训练好的TF-IDF向量化器
feature_names: 特征名称列表
"""
# 1. 预处理数据:将恶意关键词转换为同一个词
processed_data = []
for request in train_data:
# 将恶意关键词替换为统一标记
processed_request = request
for keyword in malicious_keywords:
processed_request = processed_request.replace(keyword, "MALICIOUS_TOKEN")
processed_data.append(processed_request)
# 2. 初始化TF-IDF向量化器
在计算TF-IDF权重前,先对训练数据进行预处理,将恶意请求中频繁出现的关键词(例如'script'、'select'、'waitfor'等)统一替换为一个特定标记——'MALICIOUS_TOKEN'。这一策略具有双重优势:一方面,多个不同但具威胁性的关键词被归并为同一词汇,从而显著提升该标记的词频(TF值);另一方面,由于这些关键词主要集中于恶意样本中,在整体语料库中的分布稀疏,因此其逆文档频率(IDF值)不会大幅降低。
通过上述方式,'MALICIOUS_TOKEN'在恶意请求的向量表示中获得更高的权重,使得恶意行为的特征在模型输入中更加突出,进而增强分类器对攻击流量的识别能力。实验结果显示,采用优化后的TF-IDF方法后,随机森林模型在恶意请求检测上的召回率(Recall)由97.32%上升至98.28%,而对正常请求的正确识别率(DRN)仅轻微下降,从99.84%降至99.06%,整体性能依然维持在较高水平。
Bi-LSTM-AP 模型架构说明
该模型基于双向LSTM网络,并融合了注意力机制与最大池化策略,旨在从HTTP请求序列中捕捉更全面且关键的语义特征,从而提升对恶意请求的检测精度。
import tensorflow as tf
from tensorflow.keras.layers import Input, Embedding, Bidirectional, LSTM, Dense, Lambda, Concatenate
from tensorflow.keras.models import Model
import numpy as np
def build_bilstm_ap_model(vocab_size, embedding_dim, max_length, lstm_units=32):
"""
构建包含注意力机制和最大池化的Bi-LSTM模型
参数:
vocab_size: 词汇表规模
embedding_dim: 词向量维度
max_length: 输入序列的最大长度
lstm_units: LSTM层神经元数量
返回:
model: 配置完成的Bi-LSTM-AP神经网络
"""
# 输入层定义
inputs = Input(shape=(max_length,))
# 嵌入层:将离散词索引映射为连续向量空间
embedding_layer = Embedding(
input_dim=vocab_size,
output_dim=embedding_dim,
input_length=max_length,
trainable=True
)(inputs)
# 双向LSTM层:捕获上下文依赖信息,输出序列状态
bilstm_output = Bidirectional(
LSTM(units=lstm_units, return_sequences=True)
)(embedding_layer)
注意力机制分支(Bi-LSTM-A)
该部分用于动态分配不同时间步的重要性权重:
- 首先通过一个全连接层生成原始注意力得分,激活函数为tanh;
- 接着展平输出,并使用softmax归一化得到各时刻的注意力分布;
- 然后将权重沿特征轴重复扩展,并调整维度顺序以匹配LSTM输出结构;
- 最后将注意力权重与Bi-LSTM隐藏状态逐元素相乘,再沿序列轴求和,获得加权后的上下文向量。
# 注意力权重计算
attention_weights = Dense(1, activation='tanh')(bilstm_output)
attention_weights = tf.keras.layers.Flatten()(attention_weights)
attention_weights = tf.keras.layers.Activation('softmax')(attention_weights)
attention_weights = tf.keras.layers.RepeatVector(lstm_units * 2)(attention_weights)
attention_weights = tf.keras.layers.Permute([2, 1])(attention_weights)
# 应用注意力机制进行特征加权
attention_output = tf.keras.layers.Multiply()([bilstm_output, attention_weights])
attention_output = tf.keras.layers.Lambda(lambda x: tf.reduce_sum(x, axis=1))(attention_output)
最大池化分支(Bi-LSTM-P)
此分支通过对整个序列的最大值提取,保留最显著的激活特征,增强模型对关键片段的敏感性。虽然代码尚未展示后续拼接与分类层,但通常会将注意力输出与最大池化结果合并,送入全连接层进行最终判断。
总体而言,Bi-LSTM-AP通过结合两种特征聚合策略,有效提升了模型对长序列中局部异常模式的捕捉能力,尤其适用于复杂载荷下的恶意HTTP请求检测任务。
def preprocess_for_rf(self, request):
"""
对请求数据进行预处理,适配随机森林模型的输入要求
"""
# 检测并处理潜在的恶意关键词
该段代码构建了Bi-LSTM-AP模型的整体架构,其核心组成部分包括:
输入与词嵌入层:将输入的词汇索引序列映射为低维稠密向量,便于神经网络处理。
双向LSTM层(Bi-LSTM):通过前向和后向两个方向处理词向量序列,充分捕捉上下文语义依赖关系。
注意力机制模块:动态计算各个时间步输出的重要性权重,并据此加权聚合序列信息,突出关键特征。
全局最大池化操作:从Bi-LSTM的所有时间步输出中提取每个特征维度的最大值,保留最显著的激活信息。
双路径特征融合策略:引入可训练参数w1和w2,对注意力输出与池化结果进行加权融合,使模型能够自适应地平衡两种特征表达方式的贡献。
分类头结构:包含两层全连接网络(Dense),分别使用ReLU激活函数进行非线性变换,最终通过Sigmoid激活的单神经元输出层生成二分类预测概率。
随后,利用Keras的Model API整合输入与输出,构建完整模型,并采用Adam优化器(学习率设为0.0001)、二元交叉熵损失函数以及准确率作为评估指标进行编译配置。最终返回可训练的模型实例。
max_pool_output = tf.keras.layers.GlobalMaxPooling1D()(bilstm_output)
# 融合注意力与最大池化的输出结果
w1 = tf.Variable(0.5, trainable=True)
w2 = tf.Variable(0.5, trainable=True)
fused_output = w1 * attention_output + w2 * max_pool_output
# 构建后续分类网络
dense1 = Dense(128, activation='relu')(fused_output)
dense2 = Dense(64, activation='relu')(dense1)
outputs = Dense(1, activation='sigmoid')(dense2)
model = Model(inputs=inputs, outputs=outputs)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),
loss='binary_crossentropy',
metrics=['accuracy'])
return model
此模型的创新点在于结合了注意力机制的上下文感知能力与全局最大池化的强特征选择特性。前者有助于维持序列的整体语义连贯性,后者则强化最具判别性的局部模式。借助可学习的融合系数,模型能自动调节二者在决策过程中的相对重要性。实验验证显示,该方法在检测性能上表现优异,准确率达到98.86%,召回率达97.56%,显著优于标准Bi-LSTM架构。
接下来是混合检测系统的实现部分,该系统集成了多个子模型以提升整体鲁棒性和泛化能力,主要功能模块如下:
模型初始化组件:接收两个基础分类器——随机森林与Bi-LSTM-AP,同时加载TF-IDF向量化工具、Word2Vec词向量模型及序列长度参数,完成内部状态初始化,并设定默认融合权重。
双通道预处理逻辑:分别为不同模型定制数据转换流程,确保各自输入格式符合预期。例如,随机森林依赖TF-IDF特征向量,而深度学习模型则需基于Word2Vec编码的固定长度序列。
联合预测机制:针对一条HTTP请求,分别调用两个基模型获取其预测得分,再依据预设或学习得到的权重(如w1=0.3,w2=0.7)进行加权融合,输出综合判定结果及其置信度。
性能评估接口:提供统一的评价方法,用于计算混合模型的各项关键指标,如总体准确率、恶意请求召回率以及正常流量识别率等。
class HybridDetectionModel:
"""
融合随机森林与Bi-LSTM-AP模型的混合式入侵检测框架
"""
def __init__(self, rf_model, bilstm_ap_model, tfidf_vectorizer, word2vec_model, max_length):
"""
初始化混合检测系统
参数说明:
rf_model: 训练好的随机森林分类器
bilstm_ap_model: Bi-LSTM-AP深度学习模型
tfidf_vectorizer: 用于文本向量化的TF-IDF处理器
word2vec_model: 预训练的词向量模型
max_length: 序列填充/截断的最大长度
"""
self.rf_model = rf_model
self.bilstm_ap_model = bilstm_ap_model
self.tfidf_vectorizer = tfidf_vectorizer
self.word2vec_model = word2vec_model
self.max_length = max_length
self.w1 = 0.3 # 分配给随机森林的决策权重
self.w2 = 0.7 # 分配给Bi-LSTM-AP模型的决策权重
def preprocess_for_rf(self, request):
"""
预处理请求数据,用于随机森林模型
"""
malicious_keywords = ['asf', 'wide', 'cookie', 'script', 'waitfor', 'delay', 'tamper', 'ida']
processed_request = request
for keyword in malicious_keywords:
processed_request = processed_request.replace(keyword, "MALICIOUS_TOKEN")
# 转换为TF-IDF向量
tfidf_vector = self.tfidf_vectorizer.transform([processed_request])
return tfidf_vector
def preprocess_for_bilstm(self, request):
"""
对请求数据进行预处理,适配Bi-LSTM-AP模型输入要求
"""
# 执行分词操作
words = request.split()
word_indices = []
# 将词语转换为对应的索引
for word in words[:self.max_length]:
if word in self.word2vec_model.wv:
word_indices.append(self.word2vec_model.wv.vocab[word].index + 1) # 索引从1开始,0保留作填充用途
else:
# 对于未登录词,随机分配一个有效范围内的索引值
word_indices.append(np.random.randint(1, len(self.word2vec_model.wv.vocab) + 1))
# 统一序列长度:不足时补0,超出时截断
while len(word_indices) < self.max_length:
word_indices.append(0) # 使用0作为填充标记
return np.array([word_indices])
def predict(self, request):
"""
判断输入的HTTP请求是否为恶意请求
参数说明:
request: 待检测的HTTP请求内容
返回值:
prediction: 分类结果(0代表正常,1代表恶意)
probability: 恶意概率得分
"""
# 第一步:调用随机森林模型获取预测概率
rf_input = self.preprocess_for_rf(request)
rf_prob = self.rf_model.predict_proba(rf_input)[0, 1] # 提取属于恶意类别的置信度
# 第二步:使用Bi-LSTM-AP模型进行深度学习预测
bilstm_input = self.preprocess_for_bilstm(request)
bilstm_prob = self.bilstm_ap_model.predict(bilstm_input)[0, 0]
# 第三步:融合两个模型的输出结果
fused_prob = self.w1 * rf_prob + self.w2 * bilstm_prob
# 第四步:根据综合概率判断最终类别
prediction = 1 if fused_prob >= 0.5 else 0
return prediction, fused_prob
def evaluate(self, test_data, test_labels):
"""
对当前模型进行性能评估
输入参数:
test_data: 测试集中的请求样本
test_labels: 对应的真实标签
输出指标:
accuracy: 整体准确率
recall: 恶意请求召回率
drn: 正常请求的正确识别率(Detection Rate of Normal requests)
"""
predictions = []
probabilities = []
# 遍历每条测试请求并进行预测
for request in test_data:
pred, prob = self.predict(request)
predictions.append(pred)
probabilities.append(prob)
# 引入评估工具计算关键指标
from sklearn.metrics import accuracy_score, recall_score, confusion_matrix
accuracy = accuracy_score(test_labels, predictions)
recall = recall_score(test_labels, predictions)
# 计算DRN指标:TN / (TN + FP)
tn, fp, fn, tp = confusion_matrix(test_labels, predictions).ravel()
drn = tn / (tn + fp) if (tn + fp) > 0 else 0
return accuracy, recall, drn
本研究聚焦于基于机器学习的恶意HTTP请求检测,针对现有方法在实际应用中的不足,提出了一系列优化策略与创新模型。通过系统性的实验验证,这些方法在提升检测精度、增强对未知攻击的识别能力以及平衡多维度性能指标方面展现出显著效果。
混合检测架构的核心在于其双视角分析机制:一方面,随机森林模型依托改进的权重向量,能够高效识别恶意请求中频繁出现的关键字段;另一方面,Bi-LSTM-AP模型利用词嵌入矩阵,深入挖掘请求内容的语义结构与上下文关联。通过引入可调节的加权融合策略,该混合模型实现了两种机制的优势互补,从而在整体检测表现上实现提升。
研究重难点
在构建高效的恶意HTTP请求识别系统过程中,面临以下几个关键技术挑战:
特征表达的有效性问题:HTTP请求的数据特性决定了其特征提取方式直接影响模型判别能力。传统手段如统计特征或基础词袋模型难以刻画语义内涵和序列依赖关系,导致对复杂变种攻击的识别率偏低。因此,如何构建既能反映关键信息又能保留上下文逻辑的特征表示体系,成为首要技术瓶颈。
对新型攻击的泛化能力:攻击者持续演化攻击载荷,使得新型恶意请求不断涌现。规则类检测系统缺乏自适应能力,而多数机器学习模型在面对训练阶段未见的攻击模式时也容易失效。提升模型对外部未知样本的敏感度,是确保长期可用性的关键所在。
多目标性能的协调:一个理想的检测系统需同时具备高准确率、高召回率及高正常流量通过率。然而这三者之间常存在相互制约的关系——强化某一指标可能以牺牲其他为代价。如何在三者间达成最优折衷,是设计高性能系统的难点之一。
模型训练效率的优化:HTTP日志数据体量庞大且特征维度高,直接导致训练耗时增加与资源开销上升。如何在不牺牲检测性能的前提下压缩计算成本,提高训练速度,是实现工程落地的重要考量。
主要创新点
为应对上述挑战,本研究提出了以下四项核心技术改进:
优化的关键词权重计算机制:针对标准TF-IDF在恶意文本中区分度不足的问题,提出一种面向攻击特征增强的改进算法。该方法将多个常见于恶意请求但罕见于正常请求的关键词映射至统一标识符进行权重计算,从而放大异常语义信号,提升模型对潜在威胁的感知灵敏度,同时增强对未见过攻击类型的泛化识别能力。
Bi-LSTM-AP深度网络结构:为缓解传统双向LSTM在处理长序列时的信息衰减问题,设计了一种融合注意力机制与最大池化的新型结构。该模型借助注意力模块动态聚焦关键片段,并通过最大池化提取最具代表性的局部特征,再经由可学习参数对两者输出加权整合。此结构既保持了全局语义连贯性,又突出了关键片段特征,显著提升了分类效果。
基于加权融合的混合检测框架:鉴于单一模型存在能力边界,构建了一个结合随机森林与Bi-LSTM-AP的集成检测体系。前者擅长捕捉显式关键词模式,后者更善于理解语义逻辑并识别伪装正常的恶意行为。二者结果按置信度加权融合,使最终判断兼顾精准性与全面性,在准确率、召回率和正常请求保留率之间实现更优平衡。
基于决策树的统计特征筛选方法:针对高维统计特征中存在的冗余与噪声问题,采用基于决策树的特征重要性评估机制,筛选出贡献度最高的子集。该方法有效降低了输入维度,在减少计算负担的同时维持甚至提升了检测性能,有助于提升整体系统的运行效率。
总结
本文围绕恶意HTTP请求检测展开深入研究,系统分析了当前主流方法的技术局限,并提出了多项针对性改进方案。首先,梳理了该领域的研究背景与发展现状,指出随着Web应用复杂度上升,传统规则引擎已难以应对日益智能化的攻击手段,而机器学习方法因其自适应学习优势成为主流方向。
其次,在数据预处理层面,分别从三种特征表示路径进行了优化:对于统计特征,引入基于决策树的降维策略以去除冗余;对于向量空间模型,提出改进型TF-IDF权重计算方式,强化恶意语义表达;对于深度学习输入,则采用Word2Vec生成富含语义信息的词向量,为后续模型提供高质量输入基础。
最后,构建了融合随机森林与Bi-LSTM-AP的混合检测模型,充分发挥两类模型在不同检测维度上的优势。实验结果表明,该混合架构能够在多种评价指标下取得稳定且优越的表现,尤其在对抗未知攻击和维持正常服务通行率方面具有突出优势。
参考文献
[1] Vaswani A, Shazeer N, Parmar N, 等. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 30: 5998-6008.
[2] Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[3] Mikolov T, Chen K, Corrado G, 等. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.
[4] Liu C, Yang J, Wu J. 将特征分析与SVM优化相结合的Web入侵检测系统[J]. EURASIP Journal on Wireless Communications and Networking, 2020, 2020(1): 1-9.
[5] Niu Q, Li X. 基于CNN-GRU模型的高性能Web攻击检测方法[C]//2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC). IEEE, 2020, 1: 804-808.

 京公网安备 11010802022788号
京公网安备 11010802022788号







