


 雷达卡
雷达卡



一、背景概述
随着人工智能与大规模模型在各行业的广泛应用,高维向量已成为表示文本、图像、语音等复杂数据的核心形式。在推荐系统、图像识别和自然语言处理等领域,对向量数据的存储效率与检索性能提出了更高要求,推动数据库技术不断演进。
为应对这一趋势,专用向量数据库应运而生,同时传统关系型数据库也逐步增强对向量的支持能力。PostgreSQL 通过 pgvector 插件实现了高效的向量检索功能,而 MySQL 生态在此方面长期存在短板。尽管 MySQL 9.0 引入了 VECTOR 数据类型,但其距离计算功能仅限于 HeatWave 环境使用,且缺乏通用的向量索引机制。
该技术空白导致企业不得不额外部署独立的向量数据库或进行数据迁移以满足高维向量运算需求。为此,AliSQL 在 MySQL 8.0 基础上进行了深度扩展,原生集成了企业级向量处理能力,提供开箱即用的向量化解决方案。通过标准 SQL 接口,用户可无缝融合高精度向量匹配与复杂业务逻辑,显著降低 AI 应用落地的成本与复杂度。
本文基于 AliSQL 8.0(版本号:20251031),深入解析向量索引的核心实现机制,涵盖存储结构设计与底层算法原理,帮助开发者更好地理解并高效利用其向量功能。
二、向量功能使用示例
AliSQL 支持最高达 16,383 维的向量数据存储与计算,内置主流相似性度量函数,如余弦相似度(COSINE)和欧式距离(EUCLIDEAN),并支持在全维度向量列上构建基于 HNSW(Hierarchical Navigable Small World)算法的向量索引。
以下为创建带向量索引表、插入数据及执行向量搜索的基本流程:
# 创建带有向量索引的表CREATE TABLE?`t1`?(??`id`?INT NOT NULL AUTO_INCREMENT PRIMARY KEY,??`animal`?VARCHAR(10),???`vec`?VECTOR(2) NOT NULL,?# 新增vector类型列? VECTOR INDEX?`vi`(`vec`) m=6?distance=cosine?# 显示指定m和distance? );# 插入数据INSERT INTO?`t1`(`animal`,?`vec`) VALUES? ("Frog", VEC_FROMTEXT("[0.1, 0.2]")),? ("Dog", VEC_FROMTEXT("[0.6, 0.7]")),? ("Cat", VEC_FROMTEXT("[0.6, 0.6]"));# 向量搜索SELECT?`animal`, VEC_DISTANCE(`vec`, VEC_FROMTEXT("[0.1, 0.1]")) AS?`distance`?FROM t1 ORDER BY?`distance`;查询结果展示
|--------|---------------------------||?animal?|?distance ? ? ? ? ? ? ? ? ?||--------|---------------------------||?Cat ? ?|?0.00000001552204198507212?||?Dog ? ?|? ? ?0.0029455257170004634?||?Frog ??|? ? ? ?0.05131670194948623?||--------|---------------------------|此外,也可在已存在向量数据的表上添加向量索引:
# 向量列类型转换 ALTER TABLE `t1` MODIFY COLUMN `vec` VECTOR(2) NOT NULL; # 创建向量索引
CREATE?VECTOR INDEX vi ON t1(v);?# 不显示指定m和distance,则默认使用参数值三、向量索引实现详解
HNSW 是当前最受欢迎的近似最近邻(ANN)搜索算法之一,在多项评测中展现出卓越的性能表现。AliSQL 目前优先支持基于 HNSW 的向量索引方案,整体 ANN 查询架构如下图所示:
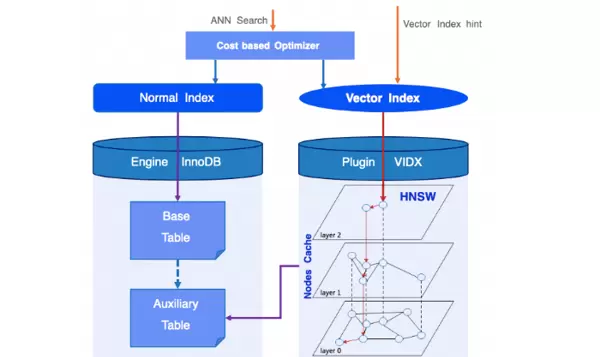
在执行 ANN 查询时,系统会先进行代价估算,自动选择最优索引路径;亦可通过 FORCE INDEX 等提示强制指定使用的向量索引。
从逻辑上看,整个 HNSW 结构构成一张完整的多层导航图。这张图的信息被组织为一张辅助表,并持久化保存至磁盘。其中每一行记录对应图中的一个节点,基于该结构即可完成向量的插入与检索操作。
与传统索引直接访问存储引擎不同,AliSQL 引入了向量索引插件机制,在内存中维护一个 HNSW 图的 Nodes Cache,用于加速查询响应速度。
3.1 HNSW 算法原理
HNSW(Hierarchical Navigable Small World)是一种基于分层图结构的高效近似最近邻搜索算法,源自论文《Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs》。其核心设计理念包含两个关键点:
- 分层跳表结构:第 0 层包含所有数据点,向上各层依次为下一层的稀疏子集,形成“缩略图”。高层用于快速跳跃定位,低层则保障搜索精度。
- 邻近连接机制:每层均构建为基于向量距离的邻近图,每个节点维护若干最近邻居信息,用于局部精细化搜索。
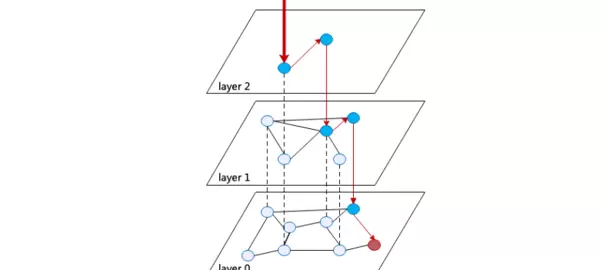
单层图中的最近邻搜索(Search Layer)
参考论文 Algorithm 2,单层 NSW 图的搜索过程如下:
- 输入参数:目标向量 q、返回数量 ef、初始候选集 C(含一个或多个当前层节点)、空的结果集 W。
- 循环迭代:从候选集 C 中取出距离 q 最近的节点 c,遍历其所有邻居 e;若 e 未被访问且与 q 距离更优,则将其加入结果集 W 和候选集 C。
- 终止条件:当候选集中最近节点到 q 的距离大于结果集中最远节点的距离时,停止搜索。
- 输出结果:返回结果集中距离最近的 ef 个节点。
节点插入流程(Insert)
对应论文 Algorithm 1,主要参数包括 M(每层节点最大邻居数)和 L(当前图最大层数),步骤如下:
- 初始化层级:确定新节点 q 将被插入的最大层级 l。
2. 搜索 L ~ l+1 层
在 HNSW 图结构中,搜索过程从最高层 L 开始,选择一个随机节点作为起始点。采用 ef = 1 的 Search Layer 算法进行贪心遍历,逐层向下查找距离查询向量 q 最近的局部节点。每一层都以此方式找到最优入口点,并将其作为下一层的起点,直至完成第 l+1 层的搜索任务。
3. 插入 l ~ 0 层
以在 l+1 层确定的最近邻节点为起点,在第 l 层继续执行 Search Layer 算法,此时 ef 设置为 M。通过该算法定位候选邻居后,将新节点 q 插入当前层,并与其邻居建立双向连接关系。此过程逐层向下执行,直至第 0 层。值得注意的是,第 0 层使用的 ef 值为 2M,与其他高层不同,旨在提升底层搜索精度和连接质量。
4. 邻居 shrink 操作
对于每一层中参与连接的节点,若其邻居数量超过预设上限 M(第 0 层为 2M),则需执行 shrink 操作。该操作会移除距离最远的连接边,保留更接近的邻居,从而维持图结构的紧凑性和高效性,避免冗余连接影响检索性能。
KNN 搜索算法
该流程对应论文中的 Algorithm 5,主要包括两个阶段:
- 快速跳转:从顶层 L 到第 1 层,使用 ef = 1 的 Search Layer 算法实现快速粗粒度跳转,迅速逼近目标区域。
- 精确搜索:进入第 0 层后,进行精细搜索,最终返回 K 个与查询向量最相似的近邻结果。
3.2 向量索引存储格式设计
为支持 HNSW 算法的持久化与高效访问,需在数据库中合理设计并存储图结构。为此引入一张辅助表,用于保存每个节点从第 0 层到其所在最高层的完整信息。每行记录代表图中的一个节点,包含多层映射点的数据。
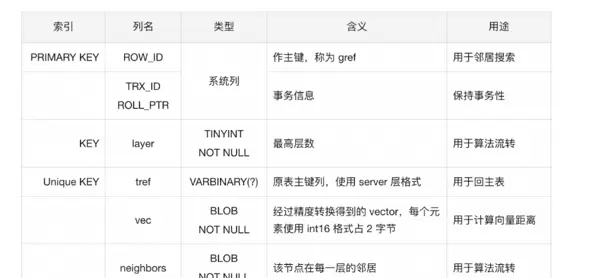
关键字段说明示例:
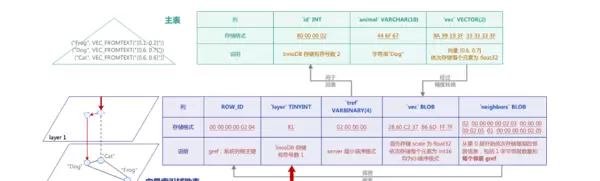
- gref:表示图引用标识(graph ref),作为辅助表主键,用于邻居节点的快速查找。实际使用 InnoDB 的系统列 ROW_ID 实现唯一性。
- layer:建立索引 KEY,便于快速定位整个 HNSW 图的入口节点——即具有最大 layer 值的节点。
- tref:表示原表引用(table ref),即主表主键,用于向量搜索完成后回表获取原始数据。采用 server 层的小端序存储格式。例如,若主表主键为 int 类型值 1,在 InnoDB 中存储为 80 00 00 01,则辅助表中以 BINARY 格式存储为 01 00 00 00。
- vec:存储节点对应的向量数据,采用半精度 int16 格式以节省空间。转换时需记录缩放因子 scale(float32 类型,占前 4 字节)。该处理虽牺牲部分精度,但显著降低存储开销并提升搜索效率。
- neighbors:按层组织邻居信息,包含从第 0 层到最高层的每一层邻居列表。每层先存 1 字节表示邻居数量,随后依次存储各邻居的 gref 值。这种结构支持算法在同层内高效导航与搜索。
精度转换机制
将原始 float32 向量元素转换为 int16 时,采用线性映射公式:
int16 = round(float32 / scale)
其中,scale 为向量中所有元素最大绝对值与 32767(int16 可表示的最大正值)之间的比值。例如,对向量 [0.6, 0.7] 进行转换的过程如下图所示:
[9A 99193F | 3333333F]原始向量 [0.6,?0.7] 大端序? ? |?1.?找最大绝对值:?0.7? ? |?2.?计算scale:?0.7/32767? ? v缩放因子 scale =?2.13629555e-05? ? |?3.?量化: 每个元素除以scale并四舍五入? ? v量化后向量 [28086,?32767]? ? |?4.?存储: scale(32位float) + dims(16位int数组)? ? v存储结构: [scale:?2.13629555e-05] [dims:?28086] [dims:?32767] 小端序[2860 C2 37 | B6 6D | FF 7F]综上所述,向量索引辅助表通过科学的字段布局、合理的精度压缩策略以及高效的 neighbors 存储结构,实现了对 HNSW 图节点信息的紧凑且可扩展的存储方案。结合必要的索引设计,完整支撑了 HNSW 算法的运行逻辑。只需持续从该表加载节点数据,即可驱动完整的插入与搜索流程。
3.3 DD 适配与 DDL 原子性保障
向量索引辅助表与普通用户表不同,不对外暴露,无法被直接访问。其与主表之间存在紧密耦合关系,具体结构如下图所示:
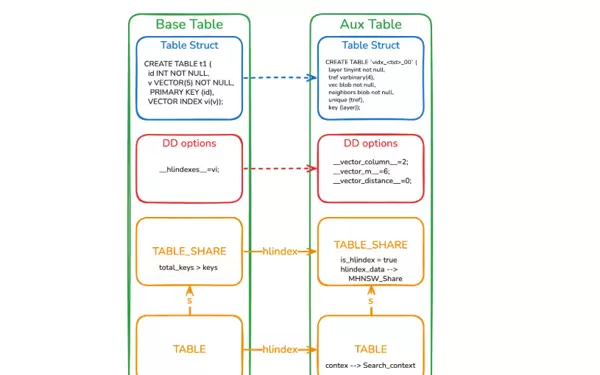
- 辅助表命名规则基于主表的 table id,格式为
vidx_<table_id>_00。主表可通过此名称在数据字典(DD)中查找到辅助表的元数据。 - 当执行向量搜索或更新操作时,系统通过主表自动打开对应的辅助表。
- 利用辅助表的 DD 信息构建 TABLE_SHARE 对象,并挂载至主表的 hlindex 指针下。同时创建共享的 Nodes Cache,通过 hlindex_data 指针进行访问。
- 辅助表的 TABLE 实例同样挂载于 hlindex 指针下,并配套生成 context 对象,用以暂存向量搜索的结果集。
- 为避免资源泄漏,辅助表的 TABLE_SHARE 不加入 table cache,而是随主表关闭而释放。
- 在执行 DDL 操作时,主表与辅助表的结构变更被封装在同一事务中。借助 MySQL 的事务机制与 DDL log 功能,确保整个变更过程具备原子性及崩溃恢复能力(Crash Safe),从而保障系统稳定性与数据一致性。
四、总结
通过对 HNSW 算法各阶段的精细化实现,结合专用辅助表的结构设计与存储优化,成功构建了一套高效、稳定、可持久化的向量索引机制。无论是插入、搜索还是元数据管理,均通过严谨的工程手段保障了算法性能与系统可靠性。
AliSQL 通过构建结构化的向量索引辅助表,全面实现了 HNSW 图结构的高效存储与算法流程支持。结合对 MySQL 8.0 数据字典(DD)的适配优化,确保了元数据的一致性以及 DDL 操作的原子性。这一技术方案有效弥补了 MySQL 生态在高维向量处理方面的长期不足,使现有的 AliSQL 实例能够直接具备高性能的向量检索能力,无需额外部署或改造。
尽管本文重点阐述了向量索引在存储层和算法层面的实现机制,但数据库整体功能的稳定性还需依赖事务管理与并发控制的支持。关于这部分内容,将在后续文章《AliSQL 向量技术解析(二):节点缓存与并发控制》中详细展开,深入分析 Nodes Cache 如何提升查询效率,并探讨向量操作如何借助并发控制机制和事务隔离级别达到生产环境所需的可靠性标准。

 京公网安备 11010802022788号
京公网安备 11010802022788号







