


 雷达卡
雷达卡



昨天,谷歌推出了其最新一代人工智能模型 Gemini 3 Pro,该模型被定位为当前最智能的AI系统。在多项基准测试中表现卓越,几乎全面领跑。我将其称为现阶段综合实力最强的“六边形战士”级大模型。
下图展示了一份涵盖主流顶级大模型性能对比的综合性Benchmark评测表,接下来我将为您逐一解析其中关键信息。
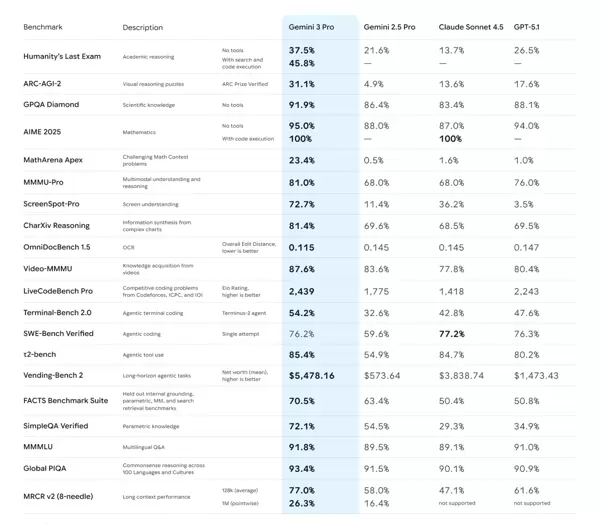
整个评测体系主要划分为四大核心模块:核心认知与推理能力、多模态理解能力、代码与智能体任务执行能力,以及知识语言与上下文处理功能。
核心结论速览
从整体数据来看,Gemini 3 Pro 在所有参评的大模型中展现出压倒性的综合优势,在绝大多数测试项目中均位居榜首。
- 综合王者:Gemini 3 Pro 在学术推理、数学解题、科学分析、多模态识别、编程能力及智能体任务等多个维度全面领先,领先幅度显著。
- 强劲对手:GPT-5.1 紧随其后,位列第二。尤其在涉及代码执行的数学问题和智能体编码任务上,与 Gemini 3 Pro 表现相当接近,部分场景难分伯仲。
- 中坚力量:Gemini 2.5 Pro 与 Claude Sonnet 4.5 处于第二梯队,整体表现稳定但与头部模型存在明显差距,尤其是在前沿复杂任务上的适应能力有待提升。
分领域深度剖析
该Benchmark覆盖了评估大模型性能的关键维度,以下按能力类别进行详细拆解:
一、核心认知与推理能力
此部分重点考察模型的逻辑思维、学术素养与抽象推理水平,相当于对“硬智商”的全面检验。
学术与科学推理
- Humanity's Last Exam:Gemini 3 Pro 得分为45.8%,远高于GPT-5.1(13.7%)和Claude(13.7%),显示出其在处理高度复杂的跨学科推理任务中的绝对优势。值得注意的是,Claude虽具备基础推理能力,但不支持外部工具调用。
- GPQA Diamond(高难度科学问答):四款模型在此项均表现出色,准确率均超过83%,表明第一梯队模型已具备深厚的科学知识储备。其中,Gemini 3 Pro 以91.9%的成绩小幅领先,体现其在深度专业领域的更强稳定性。
数学能力
- AIME 2025(高阶数学竞赛题):在无工具辅助的情况下,Gemini 3 Pro 凭借95%的通过率遥遥领先;而当允许使用代码执行功能时,Gemini 3 Pro 与 GPT-5.1 均达到惊人的100%正确率,充分说明工具集成对解决复杂数学问题的巨大增益。
- MathArena Apex(极难数学挑战):Gemini 3 Pro 以23.4%的得分断层领先,其余模型得分均低于2%,凸显其在应对类似国际数学奥林匹克级别难题时的超凡实力。
视觉与常识推理
- ARC-AGI-2(抽象图形推理):Gemini 3 Pro 获得31.1%的得分,大幅超越GPT-5.1(13.6%)。此项测试旨在模拟人类通用智能的模式识别能力,Gemini 3 Pro 的表现尤为突出,显示出更强的类人推理潜力。
二、多模态理解能力
该模块评估模型对图像、图表、文档乃至视频等非文本信息的理解与整合能力。
综合多模态理解
- MMMU-Pro(融合大学学科知识的图文理解任务):Gemini 3 Pro 以81%居首,GPT-5.1(76%)紧随其后,Gemini 2.5 Pro 与 Claude 同为68%,并列第三。
专业场景下的多模态表现
- ScreenSpot-Pro(屏幕内容理解):Gemini 3 Pro 以72.7%的表现遥遥领先,推测可能针对安卓系统界面进行了专项优化;Claude 得分为36.2%,尚可接受,其余模型表现较弱。
- CharXiv Reasoning(复杂图表信息合成):Gemini 3 Pro 以81.4%领先,其他三者得分集中在69%左右,差距明显。
- Video-MMMU(视频内容问答):各模型整体表现良好,Gemini 3 Pro 再次以87.6%拔得头筹。
三、代码与智能体能力
这是衡量现代大模型是否具备“自主行动力”的关键指标,涵盖编程能力、工具调用与长期任务执行等高级功能。
纯代码生成能力
- LiveCodeBench Pro(竞技编程Elo评分):Gemini 3 Pro 获得2439分,远高于第二名 Gemini 2.5 Pro 的1775分,体现出其在算法设计与代码效率方面的统治级优势。
智能体任务执行
- 终端操作:在 Terminal-Bench 2.0 测试中,Gemini 3 Pro 达到54.2%的任务完成率,领先其他模型,表明其能有效解析并执行命令行指令。
- 软件工程任务:在 SWE-Bench Verified(真实GitHub问题修复)中,GPT-5.1 以77.2%略胜于 Gemini 3 Pro 的76.2%,两者均处于行业顶尖水平。
- 工具使用与长周期任务:在 t2-bench(工具调用)和 Vending-Bench 2(虚拟资产积累)中,Gemini 3 Pro 显著领先。特别是在模拟商业环境中,其实现了高达$5478的净资产增长,远超其他竞争者,展现出强大的持续决策与资源管理能力。
四、知识、语言与长上下文处理能力
这一部分聚焦于事实准确性、多语言支持及对超长文本上下文的理解与记忆能力。
事实性与多语言表现
- FACTS/SimpleQA:用于评估模型回答基础事实类问题的准确性。Gemini 3 Pro 在多语种环境下保持较高一致性,显示出其在知识库构建与检索机制上的成熟度。
(事实性知识):在相关测试中,Gemini 3 Pro 取得了70.5%至72.1%的成绩,显著优于其他模型,反映出其具备更精准的内部知识体系,并且在减少“幻觉”现象方面表现更优。
MMMLU/Global PIQA (多语言与跨文化常识):各主流顶级模型在此项测试中成绩高度接近,整体准确率均超过89%,显示出在多语言理解与基础常识判断方面,领先模型之间的差距已非常微小。
长上下文能力:
MRCR v2 测试显示,在128k上下文长度条件下,Gemini 3 Pro 的准确率达到77%,位居第一。尤为突出的是,仅有 Gemini 3 Pro 与 Gemini 2.5 Pro 支持高达100万token的上下文输入,并在该极限长度下仍能取得26.3%的得分。相比之下,Claude 与 GPT-5.1 在此项标注为“not supported”,表明其不支持如此长的上下文处理,凸显出技术架构上的明显代差。
总结与洞察:
Gemini 3 Pro 实现全面领先 这一优势并非局限于个别评测维度,而是在学术任务、逻辑推理、数学解题、多模态理解、代码生成以及智能体行为等几乎所有关键领域均展现出领先地位。特别是在评估前沿能力的基准测试中(如 MathArena、ScreenSpot、Vending-Bench),其表现具有压倒性优势。
工具集成带来性能跃迁 从 AIME 数学测试结果可见,当模型被赋予使用代码执行工具的能力时,解题准确率实现质的提升。这预示着未来大模型的竞争将不仅聚焦于参数规模或训练数据,更体现在“模型+外部工具”协同生态的构建能力上。
长上下文成为核心竞争力 能否支持百万级token的上下文长度,并在此类极端场景中维持可用性能(如 Gemini 系列所示),正逐渐演变为区分模型代际的关键指标,构成显著的技术壁垒。
当前竞争格局分析
综合来看,Gemini 3 Pro 已成为当前性能的标杆;GPT-5.1 是其最有力的挑战者;而 Gemini 2.5 Pro 与 Claude Sonnet 4.5 则组成实力相近的第二梯队,彼此间竞争激烈且差距较小。

 京公网安备 11010802022788号
京公网安备 11010802022788号







