


 雷达卡
雷达卡



4、字典特征提取 - DictVectorizer
DictVectorizer 是一种将包含特征名与特征值映射关系的字典列表转换为数值型矩阵的工具,特别适用于处理混合类型的数据特征。它能够自动识别并分别处理分类变量和数值变量:
- 分类特征:通过 One-Hot 编码方式展开为多个二元特征列。
- 数值特征:保持原始数值不变,直接保留到输出矩阵中。
这种机制使其在处理 JSON 结构或结构化数据导入时尤为高效,能无缝对接 scikit-learn 的机器学习模型输入要求。
以下是一个典型应用示例,展示如何将字典数据转化为可用于建模的特征矩阵:
import numpy as np
from sklearn.feature_extraction import DictVectorizer
# 示例数据,列表中的每个元素都是一个字典,代表一个样本
data = [
{'age': 25, 'city': 'New York', 'income': 50000},
{'age': 30, 'city': 'Boston', 'income': 65000},
{'age': 35, 'city': 'New York', 'income': 75000}
]
# 初始化 DictVectorizer
dict_vectorizer = DictVectorizer(dtype=np.float64,separator ="=",sparse=True,sort=True)
# 学习并转换数据
X_dict = dict_vectorizer.fit_transform(data)
print("转换后的特征矩阵:")
print(X_dict)运行后得到的结果如下:

关键参数说明:
- dtype:指定输出矩阵的数据类型。默认为 float64,也可设置为 np.float32 或 np.int32 等更节省内存的类型。
- separator:用于构造 One-Hot 编码后新特征名称的分隔符。例如,若原特征为 'animal',取值为 'cat',当 separator='=' 时,生成的新特征名为 'animal=cat';若设为 '_',则变为 'animal_cat'。可通过以下代码查看 dict_vectorizer 内部构建情况:
print("\n特征名称:")
print(dict_vectorizer.get_feature_names_out())从结果可见,数值型字段如 'age' 和 'income' 被原样保留,而类别型字段如 'city' 则被成功转换为 One-Hot 形式。

- sparse:控制返回矩阵是否为稀疏格式(默认 True)。由于 One-Hot 编码会产生大量零值,使用 scipy.sparse 稀疏矩阵可显著减少内存占用。若设为 False,则返回普通的 numpy.ndarray 密集数组,便于调试但可能消耗较多资源,尤其在高维特征下。
- sort:决定特征列是否按名称排序(默认 True)。启用后确保每次运行结果一致,提升实验可复现性。若关闭(False),列顺序依赖于字典插入顺序,在 Python 3.6+ 中虽有序但仍不推荐随意更改此设置,除非对原始顺序有特殊需求。
5、文本特征提取 —— 词袋模型(CountVectorizer)
CountVectorizer 可将一组文本文档转换成词频计数矩阵,即“词袋”表示法,是自然语言处理中基础且高效的向量化方法。
基本工作流程:
- 分词(Tokenization):将每篇文档拆分为独立词汇单元(tokens)。
- 构建词表(Vocabulary Building):收集所有唯一词汇,并分配索引编号。
- 编码与统计(Encoding & Counting):针对每个文档,统计各词在词表中的出现次数,形成向量。
最终输出矩阵中:
- 行 对应每一个文档;
- 列 对应词表中的每一个词(即特征);
- 值 表示该词在对应文档中的出现频率。
5.1 分词相关参数配置
对于中文文本处理,通常需要借助第三方库进行有效分词。以 jieba 为例,首先需安装该库:
pip install jieba -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.comimport jieba
from sklearn.feature_extraction.text import CountVectorizer
def chinese_tokenizer(text):
words = list(jieba.cut(text))
print(f"分词结果: {words}\n")
return words随后可执行一次简单分词测试:
vectorizer = CountVectorizer(tokenizer=chinese_tokenizer)
corpus = [
"我喜欢机器学习和深度学习。",
"深度学习是人工智能的一个重要分支。",
"机器学习让计算机能够从数据中学习。"
]
X = vectorizer.fit_transform(corpus)输出结果如下:

关于 CountVectorizer 的常用参数,最常使用的是 lowercase 参数:
vectorizer = CountVectorizer(tokenizer=chinese_tokenizer,lowercase=True)该参数默认为 True,表示在分词前将所有字符转为小写。这对英文等区分大小写的语言非常有用,避免 “Apple” 和 “apple” 被视为两个不同词汇。但对于中文而言,该参数无实际影响。
preprocessor(默认 None)
作用:允许传入一个自定义函数,完全替代内置的预处理步骤。
应用场景:适用于需要深度清洗文本的情况,如去除 HTML 标签、替换特殊符号、统一编码格式等。
示例如下:
import re
from sklearn.feature_extraction.text import CountVectorizer
# 1. 定义预处理函数
def custom_preprocessor(text):
text = text.lower()
# 移除HTML标签 (例如 <p>, </br>)
text = re.sub(r'<.*?>', '', text)
# 移除URLs
text = re.sub(r'http\S+|www.\S+', '', text)
# 只保留字母、数字和空格,移除所有其他特殊字符
text = re.sub(r'[^a-zA-Z0-9\s]', '', text)
# 移除多余的空格
text = re.sub(r'\s+', ' ', text).strip()
return text
# 2. 定义分词函数
def custom_tokenizer(text):
return text.split()
# 3. 初始化 CountVectorizer,并指定 preprocessor 和 tokenizer
vectorizer = CountVectorizer(
preprocessor=custom_preprocessor,
tokenizer=custom_tokenizer
)
corpus = [
"Hello World! This is a test.",
"HELLO again! www.example.com",
"<p>Hello</p> <b>World</b> 123..."
]
X = vectorizer.fit_transform(corpus)
print("预处理和分词后的特征名称:")
print(vectorizer.get_feature_names_out())
print("\n词频矩阵:")
print(X.toarray())处理后的输出效果:

5.2 停用词过滤参数(Stop Words)
停用词指那些在文本中频繁出现但语义贡献较小的词语,例如 “的”、“了”、“是”、“我” 等。移除这些词有助于降低噪声、减少特征维度、加快训练速度,有时还能提升模型性能。
stop_wordsstop_words 参数说明:
- 'english':使用 scikit-learn 自带的英文停用词列表。
- None(默认):不启用停用词过滤。
- list:支持传入用户自定义的停用词列表,灵活适配特定领域需求。
from sklearn.feature_extraction.text import CountVectorizer
# 示例文本
corpus = [
"I love machine learning and I also love deep learning.",
"Deep learning is a branch of machine learning.",
"Machine learning allows computers to learn from data."
]
# 使用内置的英语停用词表
vectorizer_with_stopwords = CountVectorizer(stop_words='english')
X_with_stopwords = vectorizer_with_stopwords.fit_transform(corpus)
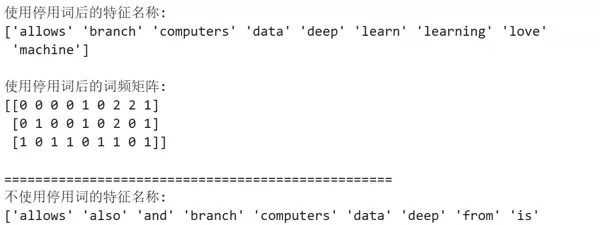
print("使用停用词后的特征名称:")
print(vectorizer_with_stopwords.get_feature_names_out())
print("\n使用停用词后的词频矩阵:")
print(X_with_stopwords.toarray())
# 对比:不使用停用词
vectorizer_without_stopwords = CountVectorizer()
X_without_stopwords = vectorizer_without_stopwords.fit_transform(corpus)
print("\n" + "="*50)
print("不使用停用词的特征名称:")
print(vectorizer_without_stopwords.get_feature_names_out())应用停用词过滤后的结果示例:
5.3 词表筛选参数(Vocabulary Filtering)
用于控制哪些词汇应被纳入最终特征空间,常见参数包括:
max_df其默认值为:
1.0max_df 参数详解:
- 功能:忽略文档频率高于设定阈值的词汇。
- 用途:剔除“过于普遍”的词,可能是通用停用词,也可能是特定语料下的高频无关词。
int:表示绝对出现次数。例如,
max_df=10意味着忽略在超过10个文档中出现的词汇。
float(取值范围在0.0到1.0之间):表示相对比例。例如,
max_df=0.95表示忽略出现在95%以上文档中的词语。
2.
min_df(默认值:
1作用:过滤掉文档频率低于指定阈值的词,用于剔除“过于罕见”的词汇,这些词可能是拼写错误、专有名词或缺乏统计意义的词语。
可选值:
- float(0.0 到 1.0 之间):表示比例形式的阈值。
- int:表示具体的频数。例如,
min_df=2
将会排除所有仅在一个文档中出现过的词。
3.
max_features(默认值:
None作用:限制最终生成词表的规模。若设置了该参数,
CountVectorizer将仅选取在整个语料库中词频最高的前
max_features个词作为特征词汇。
用途:这是一种简单而高效的降维手段。例如,设置
max_features=5000即只保留语料中最常见的5000个词作为模型输入特征。
注意:当同时配置了
max_dfmin_df和
max_features时,系统会先依据
max_dfmin_df进行低频与高频词的过滤,再根据词频从高到低排序,并截取前
max_features个词。
4.
vocabulary(默认值:
None作用:不自动从训练数据中构建词表,而是采用一个事先定义好的固定词表。
用法:可传入一个字典对象
{word: index}或一个包含关键词的列表。后续的向量化过程将仅基于此预设词表进行转换。
用途:
- 在特定任务(如情感分析)中,可能存在一个已验证有效的固定情感词典,可直接使用。
- 确保训练集与测试集使用完全一致的特征空间,避免因数据划分不同导致词表差异。
- 便于实现增量学习或在线学习场景下的模型更新。
示例说明:首先对中文文本进行分词处理,然后执行特征提取操作。所使用的停用词来源于开源社区广泛采用的标准停用词表 stopWords.txt,其中包含了大量无实际意义的中英文常见词及标点符号。
import jieba
from sklearn.feature_extraction.text import CountVectorizer
def cut_word(text):
"""
jieba中文分词
:param text: 待分词的文本
:return: 分词后用空格连接的字符串
"""
new_text = " ".join(list(jieba.cut(text)))
return new_text
# 普通写法
new_corpus = []
# 示例文本数据
corpus = [
'A股国产软件概念股全线大涨,开普云、正元智慧、君逸数码等好多强势大涨,另有好多只概念股大涨。消息面上,全新一代中国操作系统——银河麒麟操作系统在“2025中国操作系统产业大会”正式发布。',
'上海壹号院五批次好多开盘,数套房源1小时开盘售罄,劲销好多。至此好多,上海壹号院今年好多累计好多开盘总销售金额超,好多继续保持全国单盘销冠位置。',
'当日,在江苏南京举行的2025江苏省城市足球联赛好多第九轮比赛中,南京队对阵盐城队。南京市在部分商场、街区等地设置好多观赛“第二现场”,使用大屏幕同步直播赛事,同时好多设有游戏互动区、烟火市集区,让球迷们度过欢乐时光。'
]
for c in corpus:
new_corpus.append(cut_word(c))
print(new_corpus)
# 高手写法 推导式 一句话搞定
# new_corpus = [' '.join(list(jieba.cut(x))) for x in corpus]
# print(new_corpus)
# 初始化 CountVectorizer
# min_df: 忽略文档频率低于此值的词
# stop_words: 移除停用词
vectorizer = CountVectorizer(
min_df=1,
stop_words=[line.strip() for line in open('stopWords.txt', encoding='UTF-8').readlines()]
)
# 学习词汇字典并转换文本数据
X = vectorizer.fit_transform(new_corpus)
# 查看生成的词汇表
print("词汇表(特征名):")
print(vectorizer.get_feature_names_out())
# 查看稠密矩阵(实际应用中矩阵通常非常稀疏,用.toarray()查看,但用X直接计算)
print("\n特征向量矩阵:")
print(X.toarray())
print("\n稀疏矩阵:")
print(X)输出结果:若将“每天”加入停用词列表,则该词不会被当作有效特征输出。



 京公网安备 11010802022788号
京公网安备 11010802022788号







