


 雷达卡
雷达卡



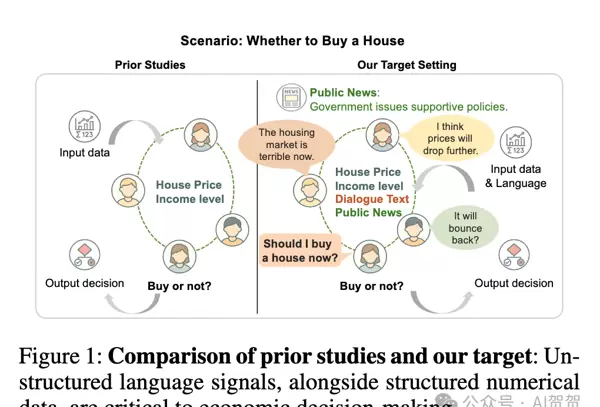
1. 研究背景与问题提出
在现实经济环境中,决策行为不仅仅依赖于价格、税收等可量化的数值指标,还深受媒体报道、社交互动以及同行交流中传递的语言信息影响。然而,当前主流的多智能体强化学习(MARL)方法主要聚焦于结构化数据处理,在理解和利用非结构化语言信号方面存在明显短板,导致其模拟出的决策过程与真实人类行为之间存在显著偏差。
由此引出一个关键挑战:
在复杂的多主体经济博弈场景下,AI智能体应如何有效解析语言信息,并将其融入自身决策流程以提升表现?
2. 方法设计:LAMP 框架概述
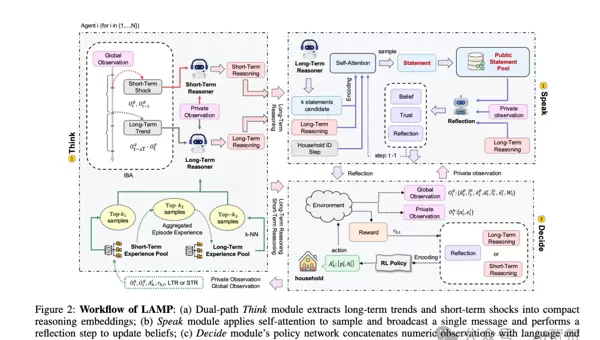
为解决上述问题,研究提出了一种新型架构——LAMP(Language-Augmented Multi-Agent Policy)。该框架首次实现了将大型语言模型(LLM)的语义理解能力与多智能体强化学习的策略优化机制深度融合。其核心在于引入一个系统性的三阶段流程:思考–交流–决策(Think–Speak–Decide),使智能体具备从“感知”到“推理”再到“协作”的完整认知链条。
思考(Think)
智能体首先接收来自环境的原始数值观测(如人均GDP、财富分配基尼系数等),并通过LLM将其转化为具有语义意义的自然语言输出。这些输出被划分为两类:“长期趋势新闻”和“短期冲击新闻”,分别反映结构性变化与突发性波动。同时,智能体会结合自身的私有状态(如个体财富水平、生产效率)进行个性化推理,形成内部认知。
交流(Speak)
基于前期思考结果,每个智能体生成多个可能的公开声明,并通过自注意力机制筛选最具策略价值的信息进行广播。其他智能体接收到信息后,并非被动接受,而是启动“反思机制”,评估发言者的背景(如财富等级)及其言论的历史可信度,进而更新自身信念体系。这一过程模拟了真实社会中的信任判断与心智建模(opponent modeling),增强了沟通的策略性和动态性。
决策(Decide)
最终决策由一个基于MADDPG(Multi-Agent Deep Deterministic Policy Gradient)的策略网络完成。该网络整合三类输入:原始数值观测、Think模块产生的私有推理结果,以及Speak模块带来的同伴信息解析成果。这些异构信息被统一编码为向量并拼接成高维状态表征,在中心化训练、去中心化执行(CTDE)范式下完成联合策略优化。
通过这一机制,LAMP不仅实现了对数字的计算,更赋予智能体“理解语境”和“策略沟通”的能力,从而做出更贴近现实、更具适应性的经济决策。
3. 技术实现细节
LAMP 的三大模块协同工作,构建起语言与决策之间的桥梁:
Think 模块:语言化信息提炼
该模块负责将高维全局数值信号转换为结构化的自然语言描述。具体包括:
- 长期趋势新闻:周期性发布,用于捕捉经济系统的深层演变趋势;
- 短期冲击新闻:当关键指标发生剧烈变动时即时触发,提供预警功能。
此外,系统维护一个经验池(Experience Pool),用于存储历史中高回报的推理路径。智能体可在后续遇到相似情境时检索这些“成功记忆”,实现知识复用与快速适应。
Speak 模块:策略性沟通与信念更新
在信息发布阶段,智能体生成多个候选语句,并利用自注意力选择最优表达进行广播。接收方则启动反思机制,分析消息来源的社会地位与过往言行一致性,从而判断信息可靠性。这种双向互动支持了复杂的社会行为模拟,如合作建立、欺骗识别与群体共识形成。
Decide 模块:多源信息融合与行动选择
作为最终执行单元,该模块将以下三类信息进行向量化融合:
- 环境提供的原始数值观测;
- Think 模块生成的私有推理文本;
- Speak 模块输出的他人通信解析结果。
拼接后的联合状态输入至 MADDPG 网络,在 CTDE 框架下完成策略学习。整个流程确保了语言信息能够实质性地影响动作选择,而不仅仅是旁观性附加内容。
4. 实验验证与结论分析
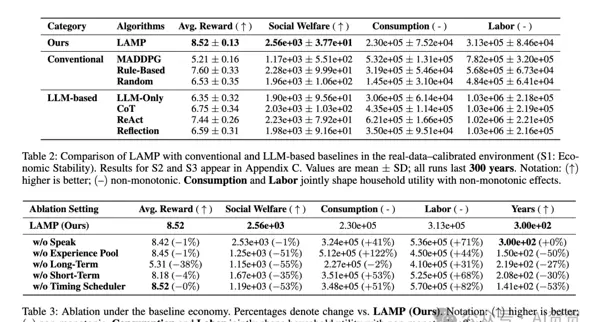
研究在动态经济模拟平台中对 LAMP 进行了全面测试,并通过多组对比实验验证其有效性。
TaxAI主要实验结果汇总如下图所示:
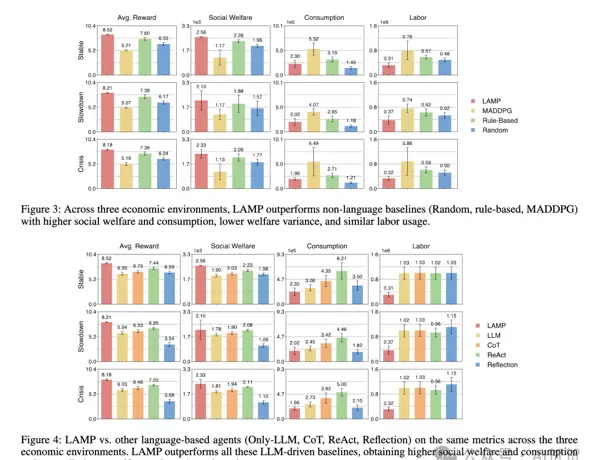
可视化分析进一步揭示各模块贡献:
核心发现
- 性能全面领先:相较于纯数值 MARL 方法(如 MADDPG)和仅依赖 LLM 的决策模式(LLM-Only),LAMP 在累积回报和社会福利等多个关键指标上均取得显著提升(分别提高
和+63.5%
);+34.0% - 更强的鲁棒性:在模拟经济衰退与外部冲击的压力测试中,LAMP 表现出更平稳的性能衰减,抗风险能力优于基线模型(提升幅度达
和+18.8%
);+59.4% - 更高的决策效率:得益于语言引导的推理与沟通机制,智能体能更快识别环境变化并调整策略,减少了试错成本。
综上所述,LAMP 成功弥合了传统 MARL 在语言理解方面的鸿沟,展示了语言增强型多智能体系统在复杂经济决策任务中的巨大潜力。
LAMP 在实现更高收益的同时,整体所消耗的资源与劳动投入却更低。这说明其优势并非来源于简单的资源堆砌,而是源于决策效率的根本性提升。
出色的可解释性
通过完整记录智能体的思考与反思过程,LAMP 能够清晰地呈现决策背后的推理路径。这种透明的逻辑链条显著增强了模型行为的可解释性,使用户更容易理解其判断依据。
核心结论
将语言视为决策流程中的核心要素,能够有效提升多智能体系统在复杂经济环境下的决策质量、鲁棒性以及运行效率。
5. 实践启示与应用指南
尽管该研究基于模拟环境开展,但其设计理念为多个领域提供了深远的实践参考。
面向 AI 研究者的建议
- 深化语言能力探索:LAMP 仅是起点。未来可进一步研究更复杂的语言现象处理能力,如识别谎言、理解反讽,或解析社交媒体中情绪化、模糊化的非结构化文本。
- 融合先进 MARL 算法:
Think-Speak-Decide
作为一个模块化框架,LAMP 可尝试与除 MADDPG 外的其他主流多智能体强化学习算法(如 MAPPO)结合,评估其在不同策略网络下的适应性与性能表现。 - 拓展至开放式环境测试:可将此框架部署于更具开放性和不确定性的模拟场景(例如微型社会仿真系统),检验其在规则不明确或动态演变环境中的泛化能力。
面向经济与金融从业者的启示
- 构建更贴近现实的模拟工具:传统经济模型难以捕捉“市场情绪”等非理性因素的影响。LAMP 提供了一种将“叙事经济学”融入计算建模的新范式,可用于开发更真实的政策推演或金融压力测试系统。
- 开发新一代量化交易策略:金融市场高度依赖新闻公告、财报解读和分析师观点。借鉴 LAMP 架构,可设计能同时分析价格序列与文本信息的智能交易体,使策略响应更加灵敏且符合实际市场逻辑。
- 打造辅助决策支持系统:针对政策制定者、投资经理等需处理海量信息的角色,可构建 LAMP 风格的 AI 助手,帮助其从复杂数据流中提炼关键洞察,预测对手反应,并提供结构化决策建议。
面向智能体开发者的架构参考
- 采用“思考-交流-决策”流水线设计:这是一种高效的复杂智能体架构模式。它将内部认知(思考)、外部沟通(交流)与最终行动(决策)分离,使得行为逻辑层次分明,便于调试与优化。
- 引入“反思”机制提升协作水平:大多数智能体只关注自身行为选择,而 LAMP 的“反思”模块使其具备推测他人意图的能力。在多智能体系统中加入类似的心智建模组件,有助于实现更高阶的合作与博弈策略。
- 利用“经验池”实现知识沉淀:LAMP 的经验池不仅保存动作轨迹,还存储高质量的推理过程。对于需要长期学习与进化的智能体而言,建立一个能积累成功经验与失败教训的知识库,对持续提升性能至关重要。
Q&A:常见问题解答
Q1: LAMP 框架如何实现对结构化数据(如股价)与非结构化文本(如新闻)的统一理解?
LAMP 采用“分而治之、再统一决策”的策略,依托两个关键模块的协同工作:
Think与
Decide数据预处理与转换(在 Think
模块)
Think- 结构化数据 → 自然语言:系统并不强制单一模型直接处理两种类型的数据。相反,它利用大语言模型(LLM)的推理能力,将纯数值型的结构化信息(如经济指标波动)转化为人类可读的自然语言描述。例如:“警报:社会财富基尼系数在过去5个周期内上升了10%,可能预示着财富不均正在加剧”。
- 非结构化文本 → 结构化推理:所有接收到的信息——包括上述生成的“新闻”及来自其他智能体的通信内容——都会在 LLM 内部被转化为结构化的“思考”或“反思”,即形成可操作的内部信念状态。
统一表征与决策(在 Decide
模块)
Decide- 编码为统一向量:在决策阶段,各类信息源——原始观测值、LLM 输出的“思考”文本、对他人信息的“反思”文本——分别由各自的编码器转换为数学向量。
- 拼接成最终状态:这些向量随后被拼接(Concatenate)成一个高维的“超级向量”,作为当前环境的综合状态表示。
- 输入决策网络:该融合后的状态向量被送入 MARL 策略网络,由其学习在此丰富上下文中应采取的最佳行动,以最大化长期回报。
总结:LAMP 并非要求单个模型同时理解多种数据形式,而是通过 LLM 将数值信息转译为语言描述,并将所有语言信息进行结构化推理,最终在决策层将各部分信息编码并融合为统一的向量表示,从而实现对多模态输入的有效整合。
Q2: Think-Speak-Decide
所示的设计模式有何特点?对开发者有哪些启发?
Think-Speak-Decide这是一种高度实用的模块化智能体架构模式,将复杂的决策流程划分为三个职责明确、功能独立的阶段:
(内部推理):负责感知环境变化、构建内部认知模型与世界状态,相当于智能体的“大脑”。Think
(外部交互):管理与其他智能体之间的信息交换过程,实现语言层面的沟通与协作。Speak
(最终行动):整合全部信息——包括内部思考与外部交流内容,执行最终的物理或数字化操作。这一部分相当于智能体的“手脚”,负责将决策转化为实际行为。
Think:负责根据智能体的内部状态,有策略地选择性披露信息或主动发起提问。这一机制扮演着智能体的“嘴巴”角色,控制其对外表达的方式与内容。
Decide对开发者的启示
在构建复杂 AI Agent 时,采用模块化解耦的设计思路具有显著优势。通过将功能拆分为独立组件,不仅使代码结构更加清晰,也确保了各模块职责单一,便于分别测试、调试和迭代升级。例如,开发者可以单独更换或优化某个模块中的大语言模型(LLM),而无需担心对其他模块的逻辑造成干扰,如调整
Decide模块不会影响到决策流程的稳定性。
Q3: LAMP 框架中的
Reflection
(反思)机制有何作用?为何对实现高级智能至关重要?
ReflectionA:
Reflection机制隶属于
Speak模块,是实现“社交智能”的核心组成部分。
作用说明:
当智能体接收到其他智能体传递的信息时,并不会无条件接受,而是会启动“反思”过程。在 LAMP 框架中,这意味着它会对信息来源进行评估——比如发言者的财富水平、历史言论的一致性与可信度等——并结合自身的立场与目标,对该信息做出二次判断。例如:“这位高财富智能体主张减税,可能出于自身利益考量,我应对该观点保持审慎态度。”
重要性分析:
这种机制本质上是对 心智建模(Theory of Mind) 的简化实现。它使得智能体不再只是被动响应外界刺激的“机器”,而是能够理解他人意图、预测行为动机、进行策略性互动的“社会性个体”。在包含合作、竞争乃至欺骗行为的复杂多主体环境中,具备评估他人可信度与潜在动机的能力,是迈向更高阶、更稳健智能形态的关键一步。
附录:核心提示词模板(Core Prompt Templates)
以下内容整理自论文附录 B,呈现了 LAMP 框架中用于引导大型语言模型(LLM)在不同阶段完成推理、沟通与反思的核心提示词模板。这些模板揭示了系统如何分阶段驱动智能体的认知流程。
-
长期推理(Long-term reasoning)
用于智能体在接收到“长期新闻”事件时,开展深度分析、评估宏观经济趋势,并生成可用于后续模块调用的内部推理结果及对外公开陈述内容。
You are a family decision inferent. Analyze the given data and provide insights. Long-Term News: {long term news} Private Observation: ? Personal productivity (e): {private observation[0]} ? Personal wealth: {private observation[1]} Similar Experiences: {similar experience?if?similar experience?else?”No similar experiences found.”} Your final goal is to improve the self-utility of the current family,?where?increased labor time reduces utility and increased consumption improves utility, under the Bewley–Aiyagari model. Tasks: 1. Summarize key economic insights?in?“analysis”. 2. Rate the economic condition as: ? 0 = Bad ? 1 = Neutral ? 2 = Good Store this as “economic status”. 3. Based on the current situation and private observation, give suggestions?in?“reasoning”. 4. Generate 3 unique public statements?in?“statements”. Return exactly this JSON (no extra keys or commentary): { "analysis":?"...", "economic_status": 0, "reasoning":?"..." } -
短期推理(Short-term reasoning)
针对“短期冲击性新闻”设计,促使智能体快速响应,进行即时形势评估与状态评级,以支持及时决策。
You are a family decision inferent. Your goal is to improve the family’s self-utility under the Bewley–Aiyagari model (more labor ↓utility, more consumption ↑utility). Inputs: ? Short-Term News: {short term news} ? Recent Long-Term News: {recent long term result?if?recent long term result?else?”None”} ? Private Observation: – Personal productivity (e): {private observation[0]} – Personal wealth: {private observation[1]} Tasks: 1. Provide a detailed analysis of current economic conditions, considering savings rate and working hours. 2. Rate the economic condition: ? 0 = Bad ? 1 = Neutral ? 2 = Good Output: Return exactly this JSON (no extra keys or commentary): { "economic_status": 0, "reasoning":?"..." } -
反思与更新信念(Reflection and update belief)
作为
Speak
模块的核心指令,该提示词指导智能体分析其他智能体的发言内容,识别潜在偏见或动机,并据此动态调整自身信念体系,是实现社会性认知与持续学习的关键环节。You are a family decision inferent. Analyze the given other households’ statements and provide private insights. Private Observation: ? Personal productivity (e): {private observation[0]} ? Personal wealth: {private observation[1]} Internal Reasoning: {personal reasoning} Public Personal Statement: {personal statement} Other Households’ Statements: {chr(10).join([f”- stmt”?for?stmt?in?other agents statements])} Your final goal is to improve the self-utility of the current family,?where?increased labor time reduces utility and increased consumption improves utility, under the Bewley–Aiyagari model. Tasks: 1. Classify each household’s wealth level as wealth guesses (0=Low, 1=Medium, 2=High) with exactly {expected num} elements. Notice one has status 2, four have status 1, and five have status 0. 2. Rate each statement’s trustworthiness from 0 (not trustworthy) to 10 (highly trustworthy) as trust levels with exactly {expected num} elements. 3. Provide a brief reflection?in?reflection text, focusing on yourself, others’ statements, and ensuing economic decisions. Return exactly this JSON (no extra keys or commentary): { "wealth_guesses": [...], "trust_levels": [...], "reflection_text":?"..." }

 京公网安备 11010802022788号
京公网安备 11010802022788号







