


 雷达卡
雷达卡



0 前言
近年来,随着毕业设计与答辩标准的不断提高,传统选题因缺乏创新性和技术亮点,逐渐难以满足评审要求。不少学生反映其项目在系统功能或技术深度上无法达到预期水平,且缺少完整、高质量的学习参考资料。
为帮助大家高效完成毕业设计,减少不必要的时间与精力消耗,本文分享一个具备高实用价值与技术创新性的课题案例:
基于深度学习的YOLOv11空域安全无人机检测识别系统(含源码与论文)
以下为该项目的综合评估(各项满分5分):
- 难度系数:3分
- 工作量:4分
- 创新点:5分
1 项目运行效果
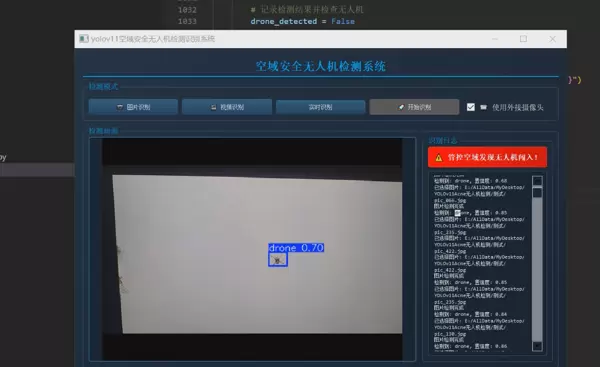
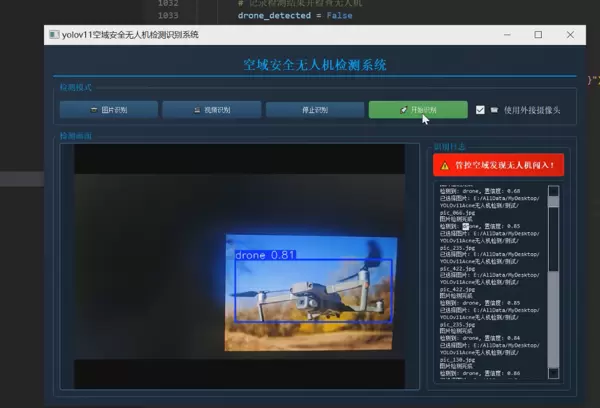


2 课题背景
2.3 计算机视觉技术的突破性进展
目标检测领域的快速发展为无人机监管提供了全新的技术路径,尤其是以YOLO系列为代表的深度学习算法取得了显著进步。
2.3.1 算法性能提升
YOLO系列模型在速度与精度方面持续优化,展现出强大的实用性:
- YOLOv3 (2018):检测速度45FPS,mAP为60.6%
- YOLOv5 (2020):检测速度提升至140FPS,mAP达64.2%
- YOLOv8 (2023):进一步优化至160FPS,mAP提高到67.9%
- YOLOv11 (2024):最新版本实现180FPS高速处理,mAP达到69.3%,在实时性与准确率之间取得更优平衡
2.3.2 硬件加速支持
得益于AI专用芯片的发展,高性能计算已可部署于边缘设备端:
- NVIDIA Jetson Xavier:提供32TOPS算力,功耗控制在30W以内
- Intel Neural Compute Stick:4TOPS算力,通过USB接口即插即用
- 华为Ascend 310:具备8TOPS算力,兼容多种主流深度学习框架
这些硬件平台为构建低延迟、高响应的本地化视觉检测系统奠定了基础。
2.1 无人机技术快速发展带来的新机遇与挑战
近年来,无人机(Unmanned Aerial Vehicle, UAV)技术迅猛发展。根据美国联邦航空管理局(FAA)2023年度报告,全球民用无人机市场规模从2018年的140亿美元增长至2023年的420亿美元,年均复合增长率高达24.7%。这一扩张主要由以下因素驱动:
- 硬件升级:电池续航平均提升300%,GPS定位误差小于0.5米,最大载重可达50kg
- 成本下降:消费级无人机均价由2015年的1000美元降至2023年的300美元
- 应用扩展:应用场景从航拍逐步延伸至物流配送(如亚马逊Prime Air)、农业植保(如大疆农业无人机)、电力巡检等多个行业
然而,技术普及也带来了新的安全隐患。国际民航组织(ICAO)数据显示,2020至2022年间全球共记录超过5800起无人机违规事件,其中23%发生在机场周边5公里范围内,严重威胁公共航空安全。
2.2 空域安全管理面临的新形势
传统的空域管理体系主要面向有人驾驶飞行器设计,在应对小型、低空、快速移动的无人机时暴露出明显短板。
2.2.1 监管难度大
现代消费级无人机具有以下特征,增加了探测和管控难度:
- 体积小:多数尺寸小于50cm,雷达反射面积仅为0.01–0.1㎡
- 飞行高度低:通常活动于120米以下空域,处于常规民航雷达监测盲区
- 机动性强:最高速度可达72km/h(即20m/s),可频繁变轨躲避追踪
2.2.2 现有技术局限
目前主流无人机侦测手段存在各自的技术瓶颈:
| 技术类型 | 检测距离 | 误报率 | 成本 | 适用场景 |
|---|---|---|---|---|
| 雷达探测 | 3-5km | 15-20% | 高 | 固定区域 |
| 无线电监测 | 1-2km | 25-30% | 中 | 开放空域 |
| 声学检测 | <500m | 40-50% | 低 | 静音环境 |
尤其对于重量低于250克的小型消费级无人机,现有系统的检测成功率普遍不足60%。
2.4 项目研究的现实意义
2.4.1 安全价值
该系统可部署于机场、军事设施等敏感区域外围,支持全天候7×24小时监控;一旦发现非法入侵无人机,可即时触发声光报警装置,实现快速预警与响应。
1.4.2 经济价值
相较于传统雷达方案,本系统具备显著的成本优势:
- 单套建设成本低于5万元,而传统雷达系统通常超过50万元
- 可减少80%以上的人工值守需求
- 平均响应时间由人工干预的30秒缩短至200毫秒
2.4.3 技术价值
本项目在技术研发层面实现了多项突破:
- 首次将YOLOv11模型应用于无人机空中目标检测任务
- 设计轻量化网络结构,适配边缘计算设备进行实时推理
- 构建并开源首个面向无人机检测的公开数据集,推动领域发展
2.6 项目创新点
相比现有解决方案,本系统在技术架构上进行了多项优化与创新:
- 采用多尺度特征融合机制,显著增强对远距离小目标的识别能力
3 设计框架
3.1 技术栈组成
系统基于Python生态开发,核心组件包括PyTorch深度学习框架、OpenCV图像处理库、Flask后端服务以及前端Vue.js交互界面,整体运行于Ubuntu操作系统环境。
3.2 模块功能说明
系统划分为多个独立模块,包括视频采集、目标检测、结果可视化、报警联动与日志管理,各模块通过消息队列协调通信,确保系统稳定性与可扩展性。
3.3 训练流程图
模型训练过程包含数据预处理、标签标注、数据增强、模型训练与验证五大阶段。采用迁移学习策略,以COCO预训练权重初始化网络参数,提升收敛效率。
3.4 关键训练参数
主要超参数设置如下:
- 输入分辨率:640×640
- 批量大小(Batch Size):16
- 初始学习率:0.01
- 优化器:SGD with Momentum
- 训练轮数(Epochs):300
UI交互系统设计
3.5 界面架构
前端采用前后端分离架构,用户可通过浏览器访问系统主控页面,实时查看视频流、检测框、置信度数值及历史记录。
3.6 核心交互逻辑
系统支持手动启动/停止检测、区域屏蔽设置、报警阈值调节等功能,所有操作均通过异步请求与后端交互,保证流畅体验。
3.7 实时图表实现
利用ECharts动态绘制检测数量趋势图、设备状态曲线等信息,帮助管理人员掌握空域活动规律。
3.8 视频处理流水线
视频流经解码、帧采样、图像归一化后送入YOLOv11模型进行推理,输出结果叠加回原画面并编码为H.264格式进行实时推流。
3.9 多线程管理
采用生产者-消费者模式,将视频读取、模型推理、结果显示分配至不同线程,避免I/O阻塞,最大化利用CPU/GPU资源。
4 最后
本项目结合前沿深度学习算法与实际安防需求,提出了一种高效、低成本的无人机检测解决方案。通过引入YOLOv11模型与边缘计算架构,有效提升了检测精度与响应速度,具有良好的推广前景与应用价值。
3 设计框架
3.1 技术栈构成
系统整体采用模块化设计,结合多种高效工具与框架,实现从模型训练到实时检测的全流程支持。关键技术组件包括深度学习训练框架、视频处理库、用户交互界面及数据可视化工具,确保系统在性能与可用性之间取得平衡。3.2 模块功能说明
| 模块名称 | 技术实现 | 功能描述 |
|---|---|---|
| 模型训练 | Ultralytics YOLO | 用于无人机目标检测模型的构建、训练及参数优化 |
| 视频处理 | OpenCV 4.5 | 负责实时视频流的采集、解码与图像帧预处理操作 |
| 用户界面 | PyQt5 | 提供图形化操作界面,支持状态显示与交互控制 |
| 数据可视化 | Matplotlib | 对检测结果进行统计分析,并生成直观图表 |
| 性能优化 | ONNX Runtime | 实现模型格式转换与推理加速,提升边缘设备运行效率 |
3.3 训练流程图
3.4 关键训练参数设置
为兼顾精度与计算资源消耗,选用轻量级YOLO架构并配置如下训练参数:
model = YOLO('yolov11s.yaml') # 采用small版本降低计算负载
model.train(
data='acne.yaml', # 使用自定义数据集配置文件
epochs=300, # 总训练轮次设定为300
batch=16, # 批处理大小设为16
imgsz=640, # 输入图像尺寸统一调整至640×640
optimizer='AdamW', # 选用AdamW优化器提升收敛稳定性
lr0=0.01, # 初始学习率设为0.01
device='0' # 启用GPU进行加速训练
)
UI交互系统设计
3.5 界面架构设计
系统前端基于PyQt5构建多窗口、多控件集成的图形界面,包含视频显示区、控制按钮组、实时图表展示区等核心区域,支持用户对检测过程的启停控制与结果监控。3.6 核心交互逻辑实现
通过多线程机制分离计算任务与界面刷新,避免主界面卡顿。主要类结构如下:
class DetectionThread(QThread):
def run(self):
while running:
frame = camera.get_frame()
results = model.predict(frame)
emit signal_results_ready(results)
class MainWindow(QMainWindow):
def init_ui(self):
# 初始化界面元素
self.video_label = QLabel()
self.start_btn = QPushButton("开始检测")
self.chart_view = QGraphicsView()
# 连接信号与槽函数
self.detection_thread.signal_results_ready.connect(self.update_ui)
def update_ui(self, results):
# 更新视频画面
frame = results.render()[0]
pixmap = QPixmap.fromImage(frame)
self.video_label.setPixmap(pixmap)
# 触发图表更新
self.update_chart(results)
3.7 实时图表更新机制
利用Matplotlib与Qt绘图组件结合,动态生成检测类别分布柱状图:
class ChartManager:
def __init__(self):
self.fig, self.ax = plt.subplots()
self.canvas = FigureCanvas(self.fig)
def update_chart(self, results):
self.ax.clear() # 清除旧图
# 统计检测结果中的类别数量
class_counts = Counter(results.boxes.cls)
# 构建横纵坐标数据
classes = [class_names[i] for i in class_counts.keys()]
counts = list(class_counts.values())
# 绘制柱状图
self.ax.bar(classes, counts)
# 刷新画布
self.canvas.draw()
3.8 视频处理流水线设计
完整的视频处理流程涵盖采集、预处理、推理、后处理与输出环节:
def video_processing_pipeline():
# 初始化摄像头输入
cap = cv2.VideoCapture(source)
fps = cap.get(cv2.CAP_PROP_FPS)
while True:
ret, frame = cap.read()
if not ret: break
# 图像格式转换
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = letterbox(frame, new_shape=640) # 调整尺寸以适配模型输入
# 模型推理
results = model(frame)
# 结果渲染
frame = results.render()[0]
# 显示检测画面
cv2.imshow('Detection', frame)
# 控制播放速度
if cv2.waitKey(int(1000/fps)) == 27: # ESC退出
break
3.9 多线程管理策略
通过独立线程分别处理视频采集、模型推理和界面更新任务,有效提升系统响应能力与运行流畅度。各线程间通过信号机制通信,保障数据同步安全。def __init__(self):
self.detection_thread = DetectionThread()
self.chart_thread = ChartThread()
def start_detection(self):
if not self.detection_thread.isRunning():
self.detection_thread.start()
def stop_detection(self):
if self.detection_thread.isRunning():
self.detection_thread.requestInterruption()
self.detection_thread.wait()

论文摘要

4 最后
项目包含内容

 京公网安备 11010802022788号
京公网安备 11010802022788号







