


 雷达卡
雷达卡



前言
在企业希望利用大模型结合内部非公开信息构建智能问答系统时,RAG(检索增强生成,Retrieval-Augmented Generation)已成为不可或缺的核心技术。然而,在实际应用过程中,RAG 所依赖的数据准备流程往往复杂繁琐,成为阻碍其落地的主要瓶颈。本文将介绍一种基于事件驱动架构的高效解决方案——通过阿里云事件总线 EventBridge 实现多源 RAG 数据处理,为企业 AI 应用打造稳定、自动、可扩展的数据管道,显著降低数据处理难度。

(来自阿里云大模型平台服务百炼 - 知识库功能 文档示例)
RAG:为何能有效缓解模型“幻觉”?
大语言模型(LLM)如同一位知识渊博的“学霸”,具备强大的语言表达和推理能力,但其输出内容有时会脱离事实,出现虚构信息或引用过时资料的现象,这种现象被称为“模型幻觉”。
造成这一问题的根本原因在于:该“学霸”的全部知识均来源于训练阶段所接触的静态数据集。尽管这些数据覆盖广泛,包括百科全书、新闻报道、专业文献等,但仍存在两个关键局限:
- 知识领域局限性: 模型对特定企业内部制度、私有业务规则、客户数据等封闭信息缺乏了解;例如无法获取公司员工手册或电商平台未公开的交易记录。
- 知识时效性缺陷: 模型的知识截止于训练数据的时间节点,无法感知实时动态变化,如股市行情波动、突发事件进展或最新政策发布。
为了使模型从“凭记忆答题”转变为“查证后作答”,RAG 技术应运而生。其核心思想可概括为:“先检索,再生成”。
具体流程分为两步:
- 检索(Retrieval): 面对用户提问,系统首先从一个持续更新的外部知识库中查找最相关的文档片段,如产品说明书、内部公告或技术文档。
- 生成(Generation): 将检索结果与原始问题一同输入大模型,作为上下文依据,引导模型基于真实资料生成准确、可追溯的回答。
借助这种方式,不仅大幅减少了错误信息的产生,还提升了回答的准确性与可信度。更重要的是,无需重新训练模型即可实现知识扩展,极大节省了成本与时间。正因如此,RAG 已成为企业构建高可靠性 AI 应用的首选路径。
RAG 落地难题:数据处理面临的三大挑战
尽管 RAG 的逻辑清晰,但在实践中,许多企业在数据处理环节遭遇重重障碍。AI 时代的数据形态已不同于传统以结构化为主的数据模式,而是呈现出海量、异构、多模态的特点,处理复杂度呈指数级上升。同时,业务对数据实时性的要求也日益提高,任何延迟都可能影响最终推理效果。
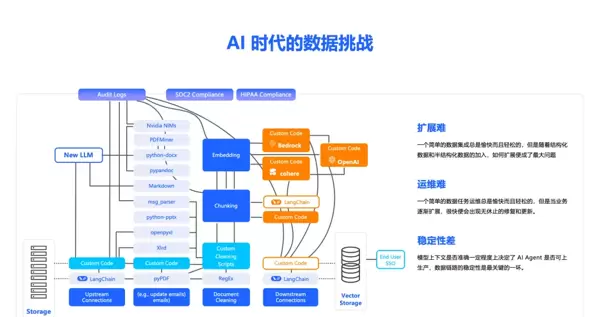
总体来看,企业在实施 RAG 时普遍面临以下“三重困境”:
1. 接入之难——异构数据源带来的“集成鸿沟”
现代企业的数据分布极为分散,存在于 ERP、CRM、OA 系统、IoT 设备乃至社交媒体等多个平台。这些数据类型多样,涵盖结构化数据(如数据库表)、非结构化内容(PDF 文件、网页、音视频)以及半结构化格式(JSON、XML)。若采用传统的点对点连接方式,每新增一个数据源都需要定制开发接口,导致系统扩展困难、响应迟缓,严重制约 AI 应用的迭代效率。
2. 运维之艰——复杂链路引发的“维护噩梦”
RAG 的数据处理链条涉及多个阶段:数据采集、清洗、切分、向量化、存储和检索等。整个流程如同一个高度耦合的“黑箱”,任一环节出错都可能导致整体失效。在实际运行中,常遇到数据源接口变更、字段缺失、编码异常或服务器负载激增等问题,故障排查耗时长,修复过程繁琐,给运维团队带来巨大压力。
3. 可靠性之忧——数据管道的“稳定性危机”
数据管道的稳定性直接决定 AI 应用的表现质量。一旦发生数据丢失、重复提交、延迟传输或质量下降等情况,模型输出就可能出现偏差,进而影响决策判断和用户体验。传统架构通常采用紧耦合设计,单个组件故障易引发连锁反应,且缺乏完善的监控与告警机制,问题往往在造成后果后才被发现。
由此可见,亟需一种新型数据处理范式,能够支持灵活接入、高可用运行和自动化管理,从而支撑 RAG 在企业环境中的长期稳定运作。
破局关键:以事件驱动重塑 AI 数据流
面对上述挑战,事件驱动架构(Event-Driven Architecture, EDA)提供了强有力的解决思路。在该架构中,“事件”是基本单元,代表系统中某项状态的变化行为。
在 RAG 场景下,数据的每一次新增、修改、处理或入库操作,均可被抽象为一条独立事件。通过引入事件总线机制,可以实现各系统间的松耦合通信,使得数据流动更加灵活、实时且具备弹性伸缩能力。阿里云 EventBridge 正是基于此理念构建,支持多源异构数据的统一接入与分发,为 RAG 提供底层支撑,助力企业打造高效、智能的数据处理体系。
当新的训练数据被上传至系统时,会触发数据接收事件;数据经过清洗与转换流程后,将生成数据处理完成事件;随后在向量化操作结束时,产生向量生成事件;最终当数据成功写入向量数据库时,触发数据入库事件。

通过这种“事件驱动”的机制,AI 数据处理的整个链路实现了标准化、可视化、可控制和可追踪,带来以下三方面的核心优势:
1. 松耦合设计
整个数据流程被拆解为多个独立的事件节点与处理模块。数据工程团队、算法团队以及平台团队可以各自独立地开发、部署和迭代所负责的组件,无需依赖或了解其他团队的具体实现方式。某一模块的更新或调整不会波及其他部分,显著提升了系统的容错能力和迭代效率。
2. 高度可扩展与运行稳定
各处理单元可根据实际负载情况独立进行横向扩展。一旦某个环节成为性能瓶颈,只需增加该组件的实例数量,而无需对整体系统扩容。同时,结合智能监控与自动故障恢复机制,系统能够实时识别异常并快速响应,保障数据流链路的持续稳定运行。
3. 端到端低延迟响应
在诸如智能客服、实时推荐等对响应速度要求极高的场景中,毫秒级延迟至关重要。事件驱动架构能确保事件一经发生即被立即捕获,并迅速触发后续处理流程。这使得 RAG 系统的知识库几乎可以实时吸收新数据,让大模型始终基于最新的信息进行推理与输出。
总体来看,采用事件驱动架构的系统在敏捷性、扩展性和可靠性方面实现了显著提升,为 AI 应用的大规模落地提供了坚实的技术基础。
EventBridge 多源 RAG 数据处理方案:打造面向 AI 的高效数据通道
阿里云事件总线 EventBridge 基于事件驱动理念,深度整合 AI 能力于数据处理全流程,为企业及开发者提供专为 AI 场景定制的、端到端智能化数据处理中间件。

借助全新的 ETL for AI Data 功能,EventBridge 推出多源 RAG 处理方案,全面自动化 RAG 数据准备的各个环节——涵盖从多源异构数据的提取、清洗、分块、向量化,直至最终入库的完整流程。
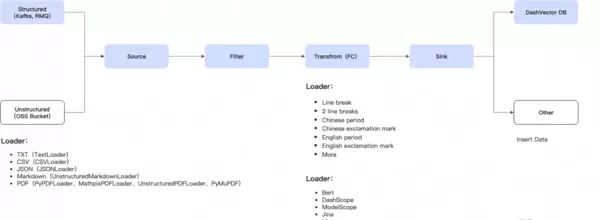
目前,开发者仅需通过 EventBridge 提供的图形化配置界面,即可轻松实现以下能力:
1. 多样化数据源无缝集成
支持接入主流数据来源,包括对象存储(OSS)、消息队列(如 Kafka、RocketMQ、MQTT)、日志服务(SLS)以及数据库服务(如 MySQL),全面覆盖结构化数据(如表格、数据库记录)、非结构化数据(如 PDF、网页、图片、音视频)以及半结构化数据(如 JSON、XML、YAML、CSV)。
2. 智能化数据转换流程
自动执行文档加载(Loader)、文本切分(Chunking)和向量嵌入(Embedding)等关键步骤。内置多种核心技术,支持多种格式的非结构化数据智能解析,构建了完整的 Loader 技术体系,包含多种分块策略、单文件加载与批量处理模式,保障大规模数据的高效可靠处理;对于结构化数据,采用流式处理架构,支持高吞吐量下的实时数据流转,实现复杂的流式计算与聚合操作。
3. 一键式向量数据入库
提供统一接口对接主流向量数据库(如 DashVector、Milvus),同时也兼容传统数据库中的向量扩展插件。用户只需通过图形界面拖拽配置数据源、处理逻辑和目标数据库,系统即可自动生成完整的向量数据处理与存储流程。内置丰富预设模板,便于快速搭建典型数据管道。同时配备完善的监控仪表板与告警机制,支持实时查看处理状态、性能指标和错误日志,便于及时排查问题。
实战案例:从零构建基于事件驱动的实时 RAG 应用
接下来,我们将通过一个完整的实践案例,演示如何利用阿里云事件总线 EventBridge、对象存储 OSS、函数计算 FC、向量检索服务 DashVector 和大模型服务平台百炼,快速搭建一套实时 RAG 应用系统。
方案概览
首先,使用 EventBridge 构建一条高效的 ETL 数据管道:系统能够自动从对象存储 OSS 实时拉取原始数据,通过函数计算 FC 自定义清洗、分块与向量化逻辑,并将处理后的结果持续写入向量检索服务 DashVector,形成一个动态更新的知识库。
其次,利用函数计算 FC 的 Web 函数功能构建一个简易的 RAG 应用前端,调用百炼平台的大模型能力进行推理,以 DashVector 中的向量数据作为外部知识支撑。
最后,输入与知识库相关的问题,测试该 RAG 应用的回答准确性和响应速度。
架构说明
完成默认配置部署后,系统在阿里云上的运行环境如下图所示。实际部署过程中可根据资源规划调整具体设置,但整体架构与下图保持一致。
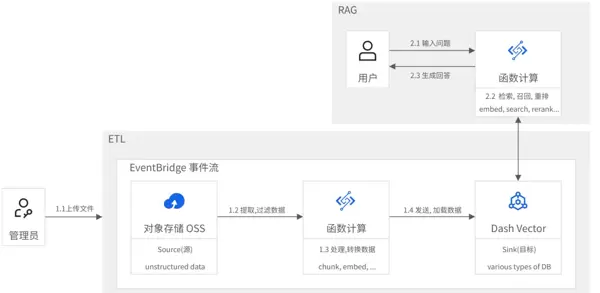
构建 RAG 应用:
创建 Web 函数:新建一个 Web 函数,注意与之前用于处理事件流的函数进行区分。该函数将作为 RAG 系统的后端服务入口。
编写应用逻辑:在函数中实现核心功能代码,使其能够接收用户输入的查询请求,调用向量检索服务 DashVector 进行知识匹配,并结合百炼大模型生成最终回答。需在代码中正确配置百炼 API-KEY、DashVector 的访问密钥及服务地址(Endpoint)等认证信息。
部署上线:完成编码后,将函数部署至云端,部署成功即表示 RAG 应用已准备就绪,可对外提供服务。
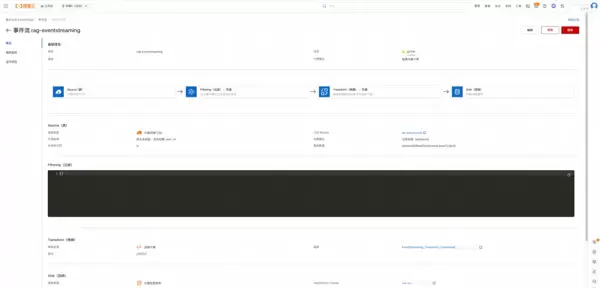
数据源与目标服务配置:
首先创建并设置对象存储 OSS Bucket 作为原始数据的来源(Source),同时创建并向量检索平台 DashVector 完成连接配置,作为数据投递的目的地(Sink)。
数据转换流程配置:
选择“内容向量化”函数模板来创建一个新的处理函数。在函数代码中填入有效的百炼 API-KEY。此函数将在数据流转过程中执行文本分块和向量化操作,是实现语义检索的关键环节。
效果验证流程:
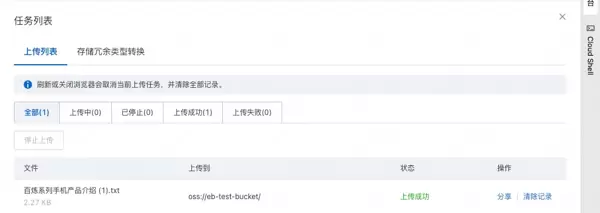
1. 更新知识库内容:
将包含私有信息的数据文件上传至已配置的 OSS Bucket 中。例如,上传一份名为《百炼系列手机产品介绍.txt》的文档,其中记录了虚拟厂商的设备参数。
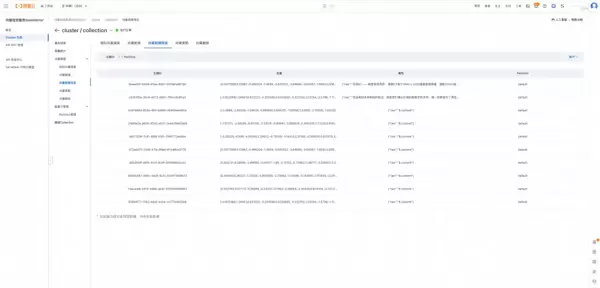
2. 检查向量数据生成情况:
当文件成功上传后,EventBridge 将自动侦测该事件并触发预设的数据处理链路。等待一段时间后,可登录 DashVector 控制台查看是否已成功生成对应的向量数据。
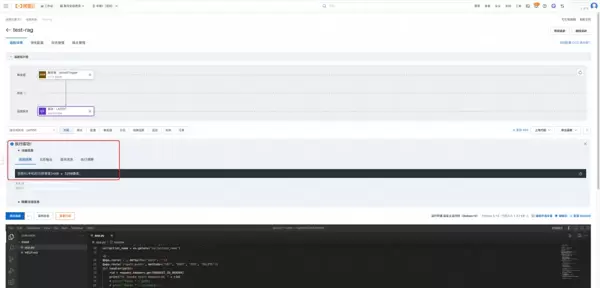
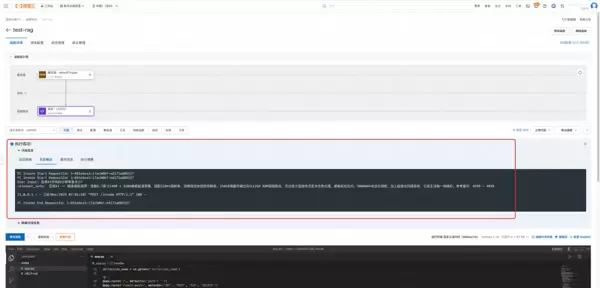
3. 发起问答测试:
通过已部署的 RAG 应用界面提交一个与上传文档相关的问题,如:“百炼 X1 手机的分辨率是多少?” 观察系统响应结果。
4. 获取并验证精准回复:
RAG 应用会自动从向量库中检索相关信息,并将召回的内容与原始问题一并发送给百炼大模型进行推理作答。很快即可获得基于私有知识库生成的准确答案。此外,通过查看函数执行日志,还能确认实际被检索出的原文片段,从而完整验证从数据摄入到语义回答的整个链路有效性。

 京公网安备 11010802022788号
京公网安备 11010802022788号







