


 雷达卡
雷达卡



在学习 Transformer 和 Attention 机制的过程中,整理了一些基础性笔记,记录如下。
参考资料:https://www.bilibili.com/video/BV1v3411r78R
一、Self-Attention 的典型应用场景(基于 Seq2seq 框架)
Seq2seq 模型广泛应用于多种序列到序列的任务中,其中 Self-attention 是其核心组件之一。常见的应用包括:
- 语音识别:将语音信号转换为对应的文字内容。
- 文本翻译:实现不同语言之间的自动翻译。
- 语音翻译:直接将一种语言的音频转化为另一种语言的音频输出。该技术对缺乏书面形式的语言或方言特别有用,例如某些地方戏曲或口语变体。

上图展示了一个实际案例:利用约1500小时带有中文字幕的台语(疑似闽南语)乡土剧视频数据进行训练。尽管未对背景音乐噪声、语音与字幕时间错位等问题做预处理(即“硬train”),模型仍展现出较强的闽南语语音识别与中译能力。
- 聊天机器人(ChatBot):通过对话数据集训练,使模型能够生成合理的回复。这类任务可被抽象为“Question-Answering”(问答)模式。

许多自然语言处理任务都可以建模为 QA 形式,如机器翻译、文章摘要生成、情感分类等,并使用 Transformer 架构进行训练。
然而,对于特定任务而言,虽然 QA 框架可用,但未必最优。有时采用专为某任务设计的轻量级模型反而更高效——所谓“杀鸡不必用牛刀”。

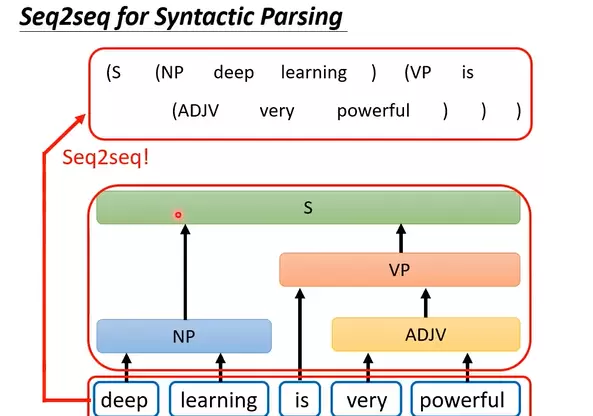
- 文法剖析(Syntactic Parsing):将句子结构解析成语法树,帮助理解句法关系,也可通过 seq2seq 方式建模。
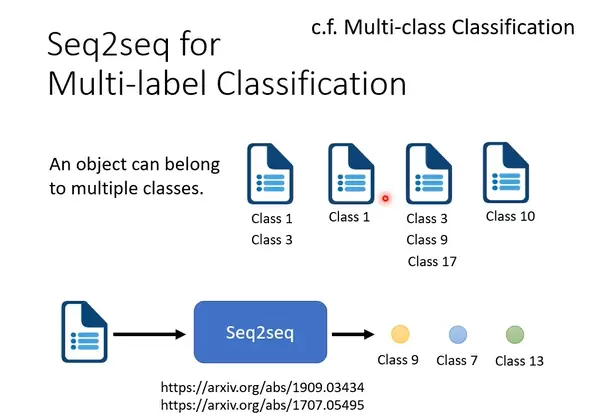
- 多标签分类(Multi-label Classification):一个输入可能同时属于多个类别。注意区别于多类别分类(Multi-class Classification),后者要求每个样本仅归属一个类别。
- 图像对象识别:尽管这不是 seq2seq 的典型用途,但仍可通过将其视为“从图像到描述序列”的映射来实现目标检测,虽略显“硬解”,但在某些场景下可行。

二、Transformer 模型架构解析(基于 Seq2seq 结构)
(一)整体结构:Encoder-Decoder 框架
最初的 Seq2seq 模型主要用于文本翻译任务,其基本结构由编码器(Encoder)和解码器(Decoder)组成。
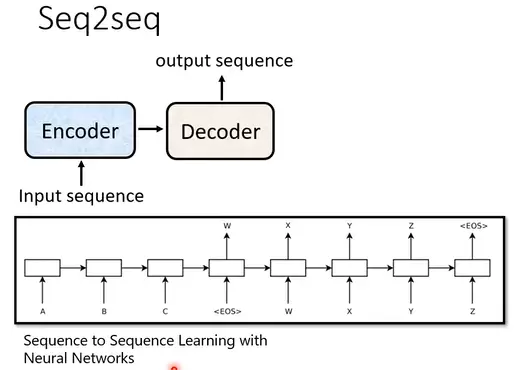
上图展示了早期的 Seq2seq 架构,用于将源语言句子编码后解码为目标语言。
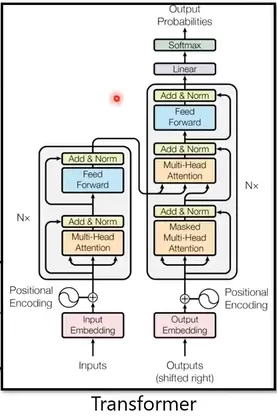
随后提出的 Transformer 模型在此基础上进行了重大改进,完全依赖注意力机制,摒弃了传统的循环神经网络结构。
1. 编码器(Encoder)结构
编码器负责将输入序列转换为一组富含上下文信息的向量表示。其内部主要由多个相同的模块堆叠而成。

每个 Encoder 模块的核心是 Self-Attention 机制,它允许模型在处理某个词时考虑到整个输入序列中的其他词。

具体来看,每一个 Encoder block 包含两个子层:
- 多头自注意力层(Multi-Head Self-Attention)
- 前馈全连接网络(Fully-Connected Network, FC)
这两个子层均采用了残差连接(Residual Connection)和层归一化(Layer Normalization)策略。

如上图所示,在 Self-Attention 层中,输出为输入与注意力结果的加和,再经过 LayerNorm 处理,确保训练稳定性。

紧接着是前馈神经网络部分。同样地,FC 层的输出也会与输入进行残差连接,并通过 LayerNorm 进行归一化处理。
2. 解码器(Decoder)结构
2.1 自回归解码器(Autoregressive Decoder, AT)
最常见的解码方式是自回归式生成,即逐个生成输出序列中的 token。
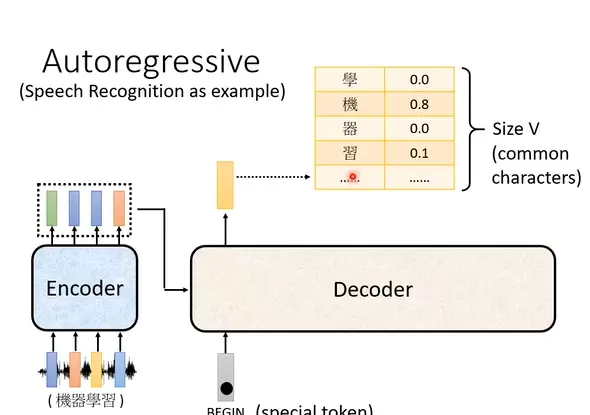
自回归解码器的初始输入是一个特殊标记“BEGIN”,表示生成开始。此外,它还会接收来自 Encoder 的上下文信息(这部分将在后续说明)。
每当一个 token 被预测出来后,它会被作为下一步的输入,继续预测下一个 token,如此循环直至遇到结束符。
每次输出是一个长度为 V 的概率向量(V 表示词汇表大小)。以中文为例,若词表包含所有常用汉字,则 V 即为汉字总数,向量中每一项代表对应字出现在当前位置的可能性。

这种逐步生成的方式类似于当前主流大模型(如 ChatGPT)的工作机制:输出内容逐词生成,每一步都依赖之前已生成的内容作为输入。
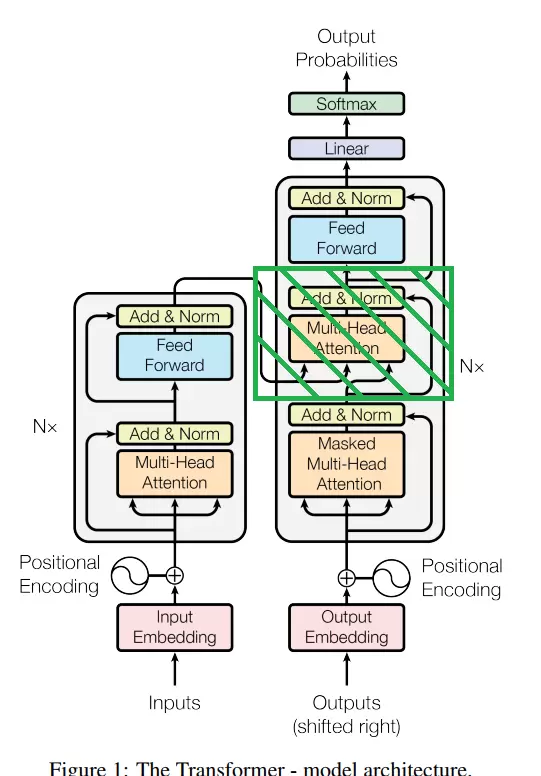
上图为完整的 Transformer 结构图。左侧为 Encoder,右侧为 Decoder。若移除 Decoder 中间那个绿色阴影模块(即 Encoder-Decoder Attention 层),则其结构与 Encoder 基本一致。
也就是说,Decoder 在结构上与 Encoder 相似,但额外增加了跨编码器的注意力机制。此外,Decoder 的第一个注意力层使用的是 Masked Multi-Head Attention,以防止未来信息泄露。

所谓的“Masked”是指:在预测当前位置的输出时,只能利用此前已知的 tokens,而不能看到当前或之后的信息。例如,在预测 b 时,只能基于 [a, a] 等前面的信息进行推断。
在进行序列预测时,模型对输入信息的利用方式具有明确的阶段性特征。例如,在预测 b2 时,仅依赖于 [a1, a2] 的信息;而当预测 b3 时,则引入 [a1, a2, a3] 作为上下文依据。
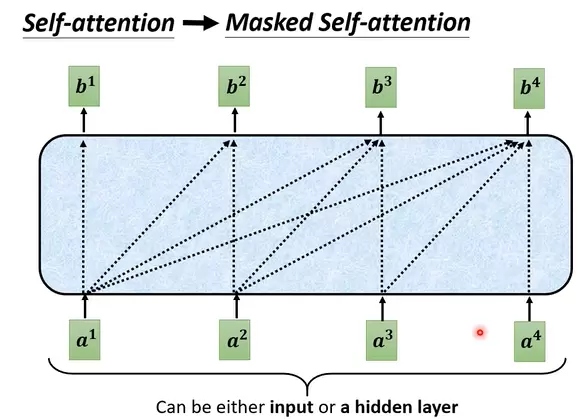
这种设计符合自然的语言生成逻辑。在 Transformer 架构中,encoder 负责处理完整的输入序列,因此采用的是未经过掩码(unmasked)的自注意力机制;而 decoder 则需要按照时间顺序逐个生成输出,后续输出应基于已生成的内容,类似于人类表达思想的过程。为此,decoder 引入了 masked self-attention 机制,防止当前位置“看到”未来的信息,从而保证生成过程的有序性与合理性。
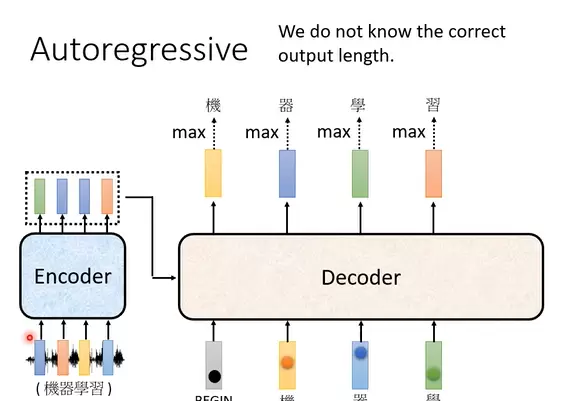
另一个关键问题是:decoder 如何判断何时停止输出?假设当前已输出“机器学习”四个字,若无终止信号,模型可能将最后一个字“习”作为下一时刻的输入,并进一步预测出“惯”,形成“习惯”这一错误延续。
为解决该问题,系统引入一个特殊的标记“END”,用于指示输出结束。当模型在生成若干内容后输出“END”符号时,即判定整个序列生成完成,从而终止后续操作。

2.2 非自回归式解码器(Non-Autoregressive Decoder, NAT)
如图所示,自回归解码器(Autoregressive Decoder)每次仅以一个起始符“BEGIN”启动,后续每一步的输入都来自前一时刻的输出结果;而非自回归解码器(NAT)则能够同时接收多个初始输入,并一次性并行地生成整句输出。

关于 NAT 解码器如何确定输出长度,通常有两种策略:
- 通过一个额外的长度预测模块预先估计目标序列的长度;
- 或直接生成较长的候选序列,然后截断“END”标记之后的所有内容。
NAT 的主要优势在于支持并行化处理,显著提升推理速度,且输出长度可控;但其性能普遍低于自回归模型(AT),存在诸如多模态分布难题(multi-modality problem)等缺陷。
(二)Encoder 与 Decoder 的交互机制
Encoder 和 Decoder 之间的信息传递依赖于一种称为 cross-attention 的结构,如下图所示。此结构对应于原始 Transformer 模型中绿色阴影部分 block 的内部细节。

具体而言,encoder 首先对输入序列进行编码,得到一组隐状态向量 [a1, a2, a3, ...]。这些向量经变换后生成键矩阵 K 和值矩阵 V,即图中的 [k1, k2, k3, ...] 与 [v1, v2, v3, ...]。
与此同时,decoder 端从第一个 token “BEGIN” 开始处理,构建查询矩阵 Q,即 [q, ...]。随后通过计算注意力得分:
softmax(Q × KT / √dk) V
得到加权后的输出表示 [v, ...],再送入全连接网络(FC)进行非线性变换,最终传递至下一层继续处理。
cross-attention 机制最早并非诞生于 Transformer,而是源自一项语音翻译任务的研究工作。下图展示了一个典型的应用实例:

图中横轴表示输入音频信号的帧位置,纵轴为输出文本中的字符顺序,颜色深浅反映不同音频帧所获得的注意力权重——颜色越深,表示该帧在生成对应字符时被赋予更高的关注程度。
输出过程自上而下逐个生成字符。每当产生一个新字母时,模型会结合当前上下文与全部音频输入,计算下一个最可能的字符。热力图清晰地揭示了:随着输出推进,注意力焦点沿着音频帧的时间轴逐步右移,但并非严格单向前进,偶尔也会回溯查看先前片段。
三、Transformer 的训练方法
(一)输出结果的评估指标
Transformer 使用交叉熵(Cross-Entropy)作为衡量输出质量的主要标准。如图所示,交叉熵用于量化模型在某一位置上的预测分布与真实标签(ground-truth)之间的差异。训练目标是使整体交叉熵最小化。
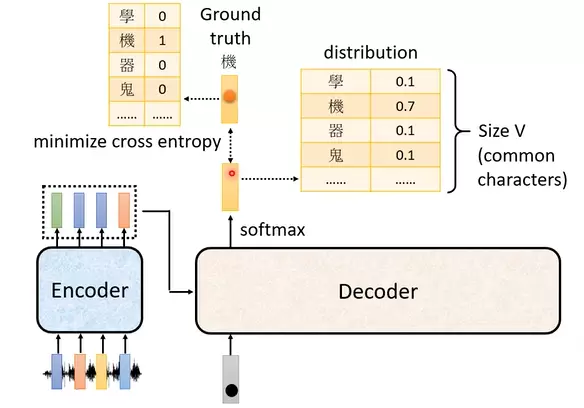
对于序列中每一个位置的输出,都会独立计算一次交叉熵损失,所有位置的损失总和构成最终的优化目标。

此外,在训练过程中广泛使用一种称为“teacher forcing”的技术:无论模型在上一时刻实际输出为何,当前步骤始终以真实标签(ground truth)作为输入来预测下一个 token。这种方法有助于加快收敛速度,并提高训练稳定性。

(二)扩展知识:复制机制(Copy-Mechanism)
在某些任务中,模型的输出并不一定完全由其自身生成,而是可以从输入内容中直接复制部分内容。例如,在聊天机器人场景下,输出中的某些词汇常常来源于输入文本;同样,在文章摘要任务中,输出往往提取自原文的关键段落。因此,设计一种能够从输入中选择性复制信息的机制显得尤为重要。


为了提升模型对输入信息的利用效率,避免出现遗漏关键内容的问题(如在文本翻译或语音合成过程中忽略部分输入),可以引入“引导学习”(Guided Attention)策略。硬性训练(hard training)方式可能导致模型跳过某些输入片段,从而影响输出完整性。通过人为设定处理顺序与注意力模式,可确保所有输入都被合理关注。相关技术包括 Monotonic Attention 和 Location-aware attention,它们能有效约束模型按指定路径处理输入序列。

在解码阶段,传统的贪心搜索策略通常选择每一步概率最高的输出(如图中红色路径所示),但这种方式可能无法得到全局最优结果。相比之下,绿色路径虽然在局部并非最优,却可能通向更优的整体输出。为此,集束搜索(Beam Search)被广泛采用——它保留多个候选路径,以增加找到更优解的可能性。
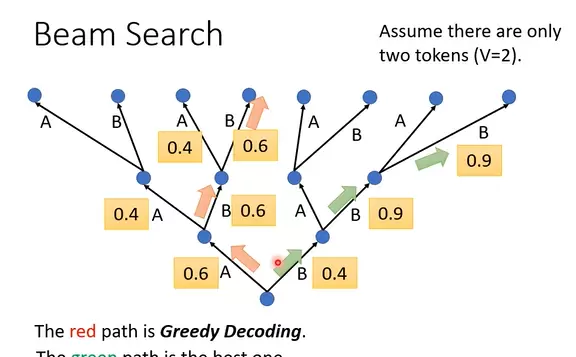
然而,集束搜索并非在所有情况下都适用。由于该方法在一定程度上引入了搜索路径的多样性,相当于增加了随机性成分。对于语音识别等强调精确性的任务,这种不确定性可能带来负面影响;但在文本续写、创意写作或语音合成等需要创造性的任务中,适度的随机性反而有助于生成更加自然和多样的内容。

关于输出质量的评估标准,也存在优化空间。传统方法常使用交叉熵损失逐词衡量预测准确性(如左图所示),即每个词独立计算误差。但这种方法忽略了句子整体结构和语义连贯性。另一种思路是将整个生成句与真实标签(ground-truth)进行对比,采用如 BLEU score 这类基于n-gram匹配的评价指标(如右图所示),更能反映实际语义相似度。
不过,这类整体评估方法计算开销较大,模型复杂度高,实际应用中并不总是推荐使用。若确实希望引入 BLEU score 作为优化目标,可结合强化学习(Reinforcement Learning)的方法,通过“硬train一发”的方式直接优化评价指标,从而获得更理想的生成效果。

此外,在训练过程中还可以采用计划采样(Scheduled Sampling)策略,逐步用模型自身的预测输出替代真实输入,同时引入一定的噪声干扰(例如随机替换部分输入字符),以此增强模型鲁棒性,使其在推理阶段面对不完美输入时仍能保持良好表现。


 京公网安备 11010802022788号
京公网安备 11010802022788号







