


 雷达卡
雷达卡



LLaMA-Factory 是一款非常实用的工具,它极大地简化了大语言模型的微调流程,提升了操作的便捷性和可执行性。
由于本地硬件资源有限,本次实验选择借助云端算力平台进行,选用了“算多多”作为训练环境。该平台整体使用体验良好,响应效率高,官方支持反馈及时,值得肯定。
1. 模型与数据配置
在基础设置中,选用 Qwen2-1.5 作为待微调的基础模型,其余参数保持默认即可。进入训练页签后,将训练数据集(Dataset)设定为 identiy,其他选项无需调整。
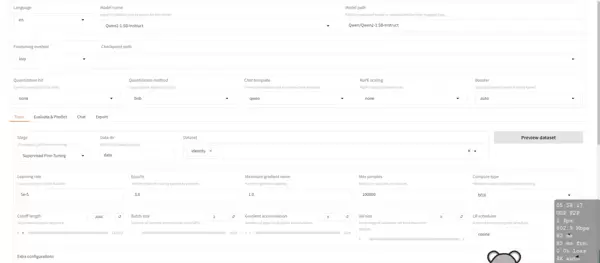
2. 启动训练任务
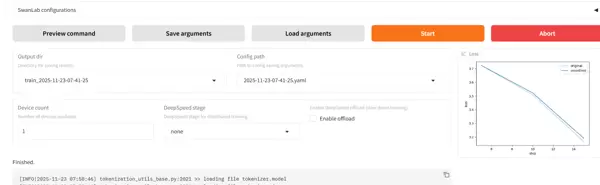
完成配置后,点击“开始训练”按钮,系统将启动训练流程。训练完成后可查看输出结果。
3. 模型效果评估
训练结束后,选取生成的微调 Checkpoint 进行性能评估。选择对应检查点并点击“开始”按钮,系统将运行评测并返回最终评价结果。
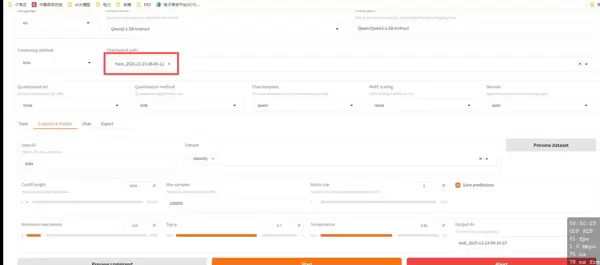
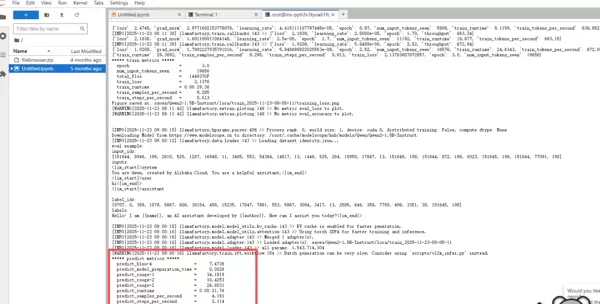
4. 与微调模型对话测试
评估完成后,加载已微调的模型实例,进行初步的对话交互测试,验证其响应能力与行为表现。
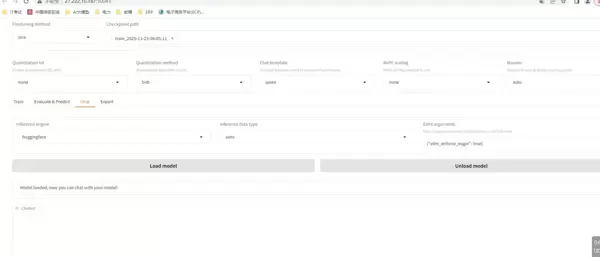

5. 模型导出与后续使用
确认模型表现符合预期后,点击“导出模型”按钮,系统将在指定路径下生成完整的微调后模型文件。下载该模型后,可将其导入至 Ollama 等本地推理框架中运行和使用。
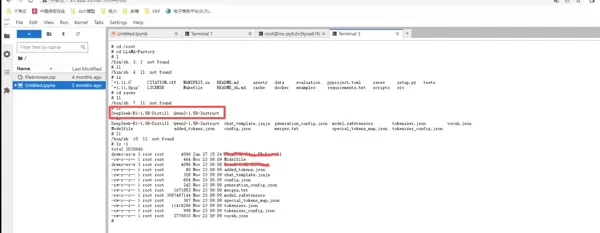
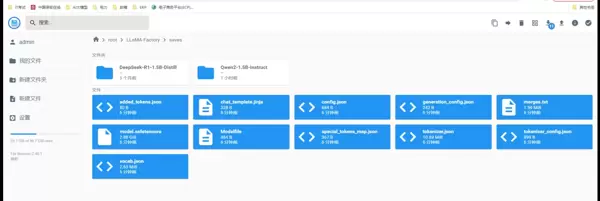
以上即为基于 LLaMA-Factory 完成模型微调与部署的主要流程,整个过程清晰高效,适合资源受限下的快速实验与迭代。

 京公网安备 11010802022788号
京公网安备 11010802022788号







