


 雷达卡
雷达卡



在计算机视觉领域,深度学习的应用远不止图像分类。尽管此前我们主要聚焦于图像分类模型——即输入一张图片并输出一个标签,例如“这张图可能是一只猫”或“那张图可能是一只狗”——但实际上,这仅是众多任务中的一种。掌握以下三项核心的计算机视觉任务,对于理解该领域的整体架构至关重要。
图像分类(Image Classification)
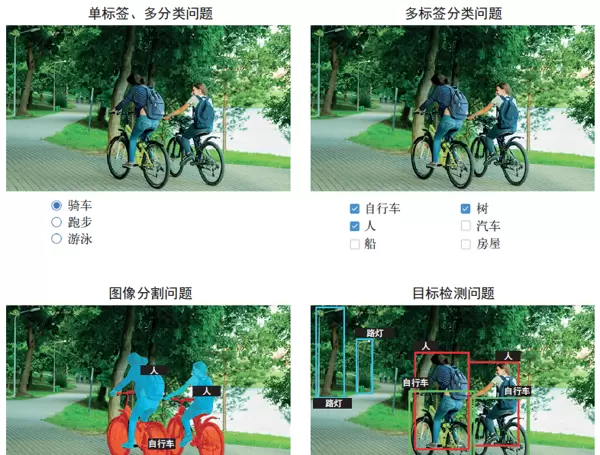
图像分类的目标是为输入图像分配一个或多个类别标签。它可以分为单标签分类和多标签分类两种形式:前者要求图像只能属于一个类别,而后者允许图像同时属于多个类别。例如,在谷歌照片中搜索关键词时,系统背后调用的是一个包含超过20,000个类别的大规模多标签分类模型,该模型基于数百万张图像训练而成,如图9-1所示。
目标检测(Object Detection)
目标检测旨在识别图像中感兴趣的物体,并在其周围绘制矩形框(称为边界框),同时标注每个框所对应的类别。这一技术广泛应用于自动驾驶场景中,比如通过摄像头实时检测车辆、行人以及交通标志等关键元素。虽然其功能强大,但由于实现复杂度较高,本书作为入门读物暂不深入讲解。有兴趣的读者可参考Keras官网提供的RetinaNet示例,该项目仅用约450行代码便实现了从零构建和训练一个完整的目标检测模型。
图像分割(Image Segmentation)
图像分割的核心任务是将图像划分为若干具有语义意义的区域,每个区域通常对应特定类别,如图9-1所示。与简单的分类不同,图像分割能够实现像素级别的识别。典型应用包括视频通话中的虚拟背景替换——通过模型精确区分人物主体与背景环境,从而实现实时背景切换。
总体而言,图像分类、图像分割和目标检测构成了计算机视觉中最基础且最重要的三大任务。大多数实际应用场景都可以归结为这三者之一。此外,还有一些更专业的任务也值得关注,例如图像相似性评分(判断两张图的视觉接近程度)、关键点检测(如识别人脸特征点)、姿态估计以及三维网格重建等,但这些属于进阶内容。
第8章已经详细探讨了图像分类的实际用途。接下来我们将重点转向图像分割,这项技术不仅实用性强,而且适用范围广泛,结合你已掌握的知识即可着手实践。
深度学习中的图像分割
使用深度学习进行图像分割,意味着利用模型对图像中每一个像素进行类别预测,从而将整幅图像划分成多个有意义的区域,如“道路”、“汽车”、“人行道”或简单分为“前景”与“背景”。这种细粒度的分析能力支撑着诸多高价值应用,涵盖医学影像分析、自动驾驶、机器人导航、视频剪辑及图像编辑等领域。
你需要了解两种主要类型的图像分割:
语义分割(Semantic Segmentation)
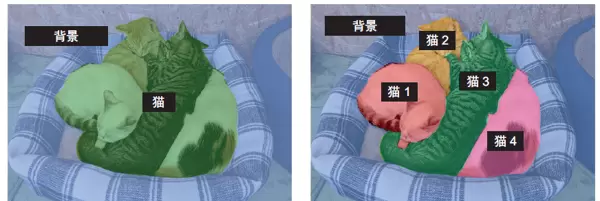
语义分割将每个像素按其所属的语义类别进行标记,例如“猫”。如果图像中出现多只猫,所有与猫相关的像素都会被统一归类为“猫”,不会区分个体。如图9-2所示,这是一种基于类别的像素级分类方法。
实例分割(Instance Segmentation)
实例分割在此基础上进一步细化,不仅要识别类别,还需区分同一类别下的不同对象实例。例如,当图像中有两只猫时,模型会分别标记为“猫1”和“猫2”,实现个体级别的分离。如图9-2所示,这种方法提供了更高的空间解析精度。
本节将以语义分割为主要研究对象,借助猫狗图像数据集来学习如何有效地区分图像中的主体与背景。
我们采用Oxford-IIIT宠物数据集,该数据集包含7390张猫狗图像,每张图像均配有相应的前景-背景分割掩码。所谓分割掩码,就是图像分割任务中的“标签”,它是一幅与原始图像尺寸相同的单通道图像,其中每个像素值代表对应位置的类别归属。在本例中,掩码的像素值具有如下含义:
- 1 —— 表示前景
- 2 —— 表示背景
- 3 —— 表示轮廓
首先,我们需要下载并解压数据集,此过程将使用shell命令工具wget和tar完成。
!wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
!wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
!tar -xf images.tar.gz
!tar -xf annotations.tar.gz原始图像以JPG格式存储于images/目录下(如images/Abyssinian_1.jpg),而对应的分割掩码则以同名PNG文件存放在annotations/trimaps/目录中(如annotations/trimaps/Abyssinian_1.png)。
接下来,构建输入图像路径列表及其对应的掩码路径列表:
input_img_paths = sorted(
[os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")])
target_paths = sorted(
[os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")])
import os
input_dir = "images/"
target_dir = "annotations/trimaps/"
input_img_paths = sorted(
[os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")])
target_paths = sorted(
[os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")])为了直观了解数据形态,我们可以查看部分样本图像与掩码。以下代码将展示一张示例图,如图9-3所示。


首先,我们通过代码展示该样本对应的目标结果,具体如图9-4所示。


由于数据集规模较小,所有数据都可以直接加载到内存中进行处理。接下来,我们将输入数据与目标标签分别载入两个NumPy数组,并进一步划分为训练集和验证集。

随后,开始构建模型结构。

调用 model.summary() 后的输出显示:模型的前半部分与图像分类任务中常用的卷积神经网络类似,均由多个 Conv2D 层堆叠而成,且滤波器数量逐步增加。在此过程中,图像经过三次两倍下采样,最终得到形状为 (25, 25, 256) 的激活特征图。这一阶段的主要功能是将原始图像压缩为尺寸更小的特征表示,每个空间位置(即像素点)都包含了原图较大区域的信息,相当于一种空间信息的浓缩过程。
不过,本模型在下采样方式上与第8章中的分类模型存在关键差异:此前我们使用 MaxPooling2D 层实现降维,而本例则采用带步幅的卷积操作进行下采样(若对卷积步幅机制不熟悉,可参考第8.1.1节“理解卷积步幅”)。之所以如此设计,是因为图像分割任务高度依赖于空间位置信息——模型需要为每一个像素生成对应的掩码输出。而2×2的最大池化操作会破坏局部位置细节:它仅从每个窗口提取一个最大值,却无法保留该值在4个候选位置中的具体来源。这种信息丢失虽在分类任务中影响不大,但在分割任务中会显著降低性能。相比之下,步进卷积能在有效缩小特征图的同时较好地维持空间对应关系。后续章节(例如第12章的生成模型)也会体现这一原则:当模型需关注特征的空间布局时,通常优先选用步幅卷积而非最大池化。
模型后半部分由多个 Conv2DTranspose 层堆叠构成。这类转置卷积层的作用是对特征图进行上采样(upsampling),以恢复至目标输出所需的分辨率。前半部分输出的特征图为 (25, 25, 256),但最终期望的输出应与目标掩码一致,即形状为 (200, 200, 3)。因此,必须执行一系列逆向变换来还原空间维度。Conv2DTranspose 层正是为此设计,可视为一种可学习的上采样机制。举例来说,若输入为 (100, 100, 64),经过一个参数为 Conv2D(128, 3, strides=2, padding="same") 的层后,输出变为 (50, 50, 128);再将其送入 Conv2DTranspose(64, 3, strides=2, padding="same") 层,则输出恢复为 (100, 100, 64),与原始输入尺寸匹配。由此可知,在通过若干 Conv2D 层将图像压缩至 (25, 25, 256) 后,利用对应的 Conv2DTranspose 层序列即可逐步重建出 (200, 200, 3) 的完整图像。
接下来对模型进行编译并开始训练:
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy")
callbacks = [
keras.callbacks.ModelCheckpoint("oxford_segmentation.keras",
save_best_only=True)
]
history = model.fit(train_input_imgs, train_targets,
epochs=50,
callbacks=callbacks,
batch_size=64,
validation_data=(val_input_imgs, val_targets))
我们绘制训练过程中的损失变化曲线,如图9-5所示。
epochs = range(1, len(history.history["loss"]) + 1)
loss = history.history["loss"]
val_loss = history.history["val_loss"]
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
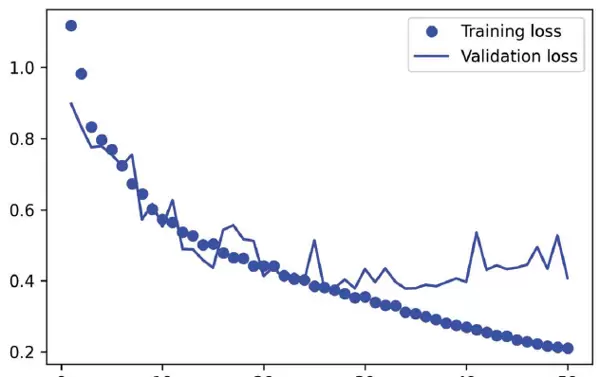
从图9-5可见,模型大约从第25轮起开始出现过拟合现象。因此,我们依据验证损失最低的状态重新加载最优模型,并演示其在实际样本上的分割预测效果,结果如图9-6所示。


预测所得的分割掩码整体表现良好,仅存在少量瑕疵,主要出现在前景与背景交界处的几何边缘区域。尽管如此,模型仍能较为准确地完成像素级分类任务。
尽管目前的模型看似依然运作良好,但你已经掌握了图像分类与图像分割的基本原理,并能够运用这些知识完成诸多任务。
然而,在实际工程实践中,资深工程师所设计的卷积神经网络远比此前展示的示例复杂得多。
这些专家凭借丰富的经验,能够在短时间内准确判断出如何搭建最先进的网络结构。而这种深层次的思维模式和架构直觉,正是你当前阶段尚未建立的部分。
为了缩小这一能力差距,深入理解架构模式(architecture pattern)变得至关重要。接下来,我们将进一步探讨这一主题。

 京公网安备 11010802022788号
京公网安备 11010802022788号







