


 雷达卡
雷达卡



贝叶斯网络学习总结与实践
1. 贝叶斯网络简介
贝叶斯网络(也称信念网络)是一种基于有向无环图(DAG)的概率图模型,用于描述一组随机变量之间的条件依赖关系。其核心结构包括:
- 节点:代表随机变量
- 有向边:表示变量间的依赖关系
- 条件概率:量化依赖强度
- 先验概率:无父节点的变量使用先验分布进行建模
- 独立性假设:若两节点间无连接,则视为相互独立
该模型具备强大的不确定性表达能力,所有变量均为可观测,且因果路径清晰直观。
2. 概率基础与贝叶斯理论
2.1 概率论基本要素
在构建贝叶斯模型前,需掌握以下基础概念:
- 古典概率:适用于等可能结果场景下的概率计算
- 几何概率:依据空间区域大小来衡量事件发生的可能性
- 条件概率:指在某一事件已发生前提下,另一事件出现的概率
- 加法定理:用于求解多个事件中至少一个发生的概率
- 减法定理:计算某事件不发生的概率
- 独立事件:一个事件的发生不影响另一个事件的概率值
- 联合概率分布:多个变量共同取特定值的概率分布
- 条件概率分布:在给定部分变量取值时,其余变量的分布情况
2.2 贝叶斯方法的核心思想
- 先验概率:在未观察到任何数据时对事件发生可能性的初始判断
- 后验概率:结合新证据后对概率的更新估计
- 全概率公式:将复杂事件拆分为若干互斥子事件之和,便于计算
- 贝叶斯公式:利用先验与似然函数推导出后验概率,是推理过程的关键工具
3. 朴素贝叶斯分类器原理与特性
3.1 基本假设与机制
朴素贝叶斯是一种高效的分类算法,其建立在如下关键假设之上:
- 将输入问题划分为特征向量和类别标签两部分
- 假设所有特征在类别条件下相互独立,即彼此之间无关联影响
尽管这一“朴素”假设在现实中往往不成立,但该模型仍能有效降低贝叶斯网络构造的复杂度,并对噪声数据和冗余属性具有良好的鲁棒性。
3.2 实际应用流程
朴素贝叶斯的应用可分为三个阶段:
- 准备阶段:确定分类任务中的特征集合并收集训练样本
- 训练阶段:统计每个类别下各特征的条件概率分布
- 预测阶段:利用训练所得模型对新样本进行类别判别
3.3 模型优势分析
- 结构仅含输入层与输出层,层级简单
- 实现逻辑清晰,易于编程实现
- 分类性能稳定,在不同数据集上表现一致
- 在小样本环境下依然保持较高准确率
- 时间和空间开销较小,适合实时或资源受限场景
- 支持增量式学习,可分批处理大规模数据
4. 贝叶斯网络中的推理技术
4.1 推理方向分类
- 自顶向下推理:从原因出发,推断可能的结果,常用于预测场景
- 自底向上推理:由观测结果反推潜在原因,多用于诊断任务
4.2 推理策略
根据精度需求,推理可分为两类:
- 精确推理:
- 直接计算整个联合概率分布,理论上准确但计算成本高
- 采用变量消元法优化:借助链式法则和条件独立性,调整运算顺序以减少重复计算,提升效率
- 近似推理:
- 常用蒙特卡洛抽样(又称随机仿真)方法
- 核心思想:依据目标分布生成大量随机样本,通过样本频率近似估计真实概率值
5. 典型应用场景
经过长期发展,贝叶斯网络已被广泛应用于人工智能多个领域:
5.1 自然语言处理
- 中文文本分词
- 机器翻译系统
- 文档自动分类
5.2 故障检测与诊断
- 汽车发动机异常识别
- 波音飞机系统故障定位
- 核电站软硬件运行状态监控
5.3 医疗健康辅助决策
- 胃部疾病风险评估
- 多种疾病的初步筛查与辅助诊断
5.4 其他重要领域
- 模式识别
- 数据挖掘中的关联规则发现
- 智能决策支持系统
- 金融领域的风险控制模型
- 企业经营管理中的决策优化
6. 实践案例:朴素贝叶斯分类模型实现
6.1 任务说明
根据课程作业要求,采用sklearn库提供的高斯朴素贝叶斯分类器对人工生成的数据集进行建模分析。数据通过make_blobs聚类生成器创建,包含50000个样本,每个样本有两个特征维度,共分为三个类簇。设定标准差为1.0,随机种子固定为42。
numpy6.2 完整代码示例
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
朴素贝叶斯分类模型实现
根据PPT中的课堂作业要求,使用sklearn库中的高斯朴素贝叶斯分类模型进行分析
"""
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
def generate_data(n_samples=50000, n_features=2, cluster_std=1.0, random_state=42):
"""
生成用于分类任务的模拟数据集。
Args:
n_samples: 样本数量,默认为50000
n_features: 特征数量,默认为2
cluster_std: 样本集的标准差,默认为1.0
random_state: 随机数种子,默认为42
"""
return make_blobs(n_samples=n_samples,
n_features=n_features,
centers=3,
cluster_std=cluster_std,
random_state=random_state)
# 主程序执行流程
if __name__ == "__main__":
# 生成数据
X, y = generate_data()
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建并训练模型
model = GaussianNB()
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print(f"分类准确率: {acc:.4f}")
# 可视化结果(可选)
plt.figure(figsize=(8, 6))
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred, cmap='viridis', s=10)
plt.title("Gaussian Naive Bayes 分类结果")
plt.xlabel("特征 1")
plt.ylabel("特征 2")
plt.colorbar()
plt.show()
def generate_cluster_data(n_samples=1000, n_features=2, cluster_std=0.5, random_state=42):
"""
生成带有类簇结构的模拟数据集,包含特征、标签和样本权重。
参数说明:
n_samples: 样本总数,默认1000
n_features: 特征数量,默认为2(二维数据)
cluster_std: 类簇标准差,控制簇内离散程度
random_state: 随机种子,保证结果可复现
返回值:
X: 特征矩阵,维度为(n_samples, n_features)
y: 分类标签,维度为(n_samples,)
sample_weight: 每个样本对应的权重,维度为(n_samples,)
"""
# 设定三个类簇的中心坐标
centers = [(-5, -5), (0, 0), (5, 5)]
# 利用make_blobs工具生成聚类数据
X, y = make_blobs(n_samples=n_samples, n_features=n_features,
cluster_std=cluster_std, centers=centers,
shuffle=False, random_state=random_state)
# 调整标签分布:前一半样本标记为类别0,后一半为类别1
y[:n_samples // 2] = 0
y[n_samples // 2:] = 1
# 为每个样本分配一个随机权重值
sample_weight = np.random.RandomState(random_state).rand(y.shape[0])
return X, y, sample_weight
def train_and_evaluate(X, y, sample_weight, test_size=0.9, random_state=42):
"""
使用高斯朴素贝叶斯算法训练模型,并进行性能评估。
输入参数:
X: 特征数据集
y: 对应的标签向量
sample_weight: 样本权重数组
test_size: 测试集占比,默认取90%
random_state: 随机状态控制
输出内容:
clf: 已训练完成的分类器实例
X_test: 测试集特征
y_test: 测试集真实标签
y_pred: 模型预测结果
prob_pos_clf: 正类预测概率(第二类的概率)
accuracy: 在测试集上的准确率评分
"""
# 将原始数据划分为训练与测试两部分(包括特征、标签及权重)
X_train, X_test, y_train, y_test, sw_train, sw_test = train_test_split(
X, y, sample_weight, test_size=test_size, random_state=random_state)
# 初始化高斯朴素贝叶斯模型
clf = GaussianNB()
# 使用训练集拟合模型
clf.fit(X_train, y_train)
# 对测试集执行预测操作
y_pred = clf.predict(X_test)
# 获取每个样本属于正类(类别1)的预测概率
prob_pos_clf = clf.predict_proba(X_test)[:, 1]
# 计算并返回模型准确率
accuracy = accuracy_score(y_test, y_pred, normalize=True)
return clf, X_test, y_test, y_pred, prob_pos_clf, accuracy
def visualize_results(X, y, clf, title="朴素贝叶斯分类结果"):
"""
绘制分类模型的决策边界与样本点分布图。
参数说明:
X: 全部样本的特征数据(用于绘图展示)
y: 实际分类标签(决定颜色映射)
clf: 训练好的分类器(用于生成决策面)
title: 图形标题文本
"""
# 配置matplotlib支持中文显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置默认字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示异常问题
# 定义网格分辨率
h = 0.02
# 确定坐标轴范围,略大于数据实际分布
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
# 创建规则网格点阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# 使用模型对所有网格点进行预测
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape) # 恢复为二维结构以匹配图像格式
# 开始绘图
plt.figure(figsize=(10, 8))
# 填充决策区域,使用浅色表示不同类别区域
plt.contourf(xx, yy, Z, alpha=0.8)
# 叠加真实样本点,按真实标签着色,添加黑色边框增强可视性
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o')
# 添加坐标轴标签
plt.xlabel('特征 1')
plt.ylabel('特征 2')
# 设置图形标题
plt.title(title)
# 显示图像
plt.show()
6.3 代码详细说明
6.3.1 必要库的导入
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as pltnumpymake_blobstrain_test_splitGaussianNBaccuracy_scorematplotlib.pyplot6.3.3 模型训练与性能评估函数
def train_and_evaluate(X, y, sample_weight, test_size=0.9, random_state=42):
# 划分训练集和测试集(包含特征、标签及样本权重)
X_train, X_test, y_train, y_test, sw_train, sw_test = train_test_split(
X, y, sample_weight, test_size=test_size, random_state=random_state)
# 初始化并训练高斯朴素贝叶斯分类器
clf = GaussianNB()
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 获取正类别(通常为类别1)的预测概率
prob_pos_clf = clf.predict_proba(X_test)[:, 1]
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
return clf, X_test, y_test, y_pred, prob_pos_clf, accuracy6.3.2 数据生成逻辑
def generate_data(n_samples=50000, n_features=2, cluster_std=1.0, random_state=42):
# 定义三个聚类中心
centers = [(-5, -5), (0, 0), (5, 5)]
# 生成初始聚类数据
X, y = make_blobs(n_samples=n_samples, n_features=n_features,
cluster_std=cluster_std, centers=centers,
shuffle=False, random_state=random_state)
# 调整标签:前一半为负类(0),后一半为正类(1)
y[:n_samples // 2] = 0
y[n_samples // 2:] = 1
# 为每个样本分配随机权重,模拟不同重要性
sample_weight = np.random.RandomState(random_state).rand(y.shape[0])
return X, y, sample_weight主流程控制函数
def main():
"""
主函数,执行完整的朴素贝叶斯分类流程。
"""
print("=== 朴素贝叶斯分类模型实现 ===")
# 生成实验数据
X, y, sample_weight = generate_data()
print(f"生成数据完成,样本数量: {X.shape[0]}, 特征数量: {X.shape[1]}")
# 训练模型并评估性能
clf, X_test, y_test, y_pred, prob_pos_clf, accuracy = train_and_evaluate(X, y, sample_weight)
print(f"模型训练完成,测试集准确率: {accuracy:.4f}")
# 可视化分类结果
visualize_results(X_test, y_test, clf)
print("分类结果可视化完成,已保存为 '朴素贝叶斯分类结果.png'")
# 展示部分预测结果
print("\n部分预测结果示例:")
print(f"测试集前5个样本的真实标签: {y_test[:5]}")
print(f"测试集前5个样本的预测标签: {y_pred[:5]}")
print(f"测试集前5个样本的正类预测概率: {prob_pos_clf[:5]}")程序入口点
if __name__ == "__main__":
main()plt.title(title)
plt.colorbar()
plt.savefig("朴素贝叶斯分类结果.png")
plt.close()6.3.4 结果可视化函数
定义一个用于展示分类模型结果的可视化函数,能够绘制决策边界与数据点分布:
def visualize_results(X, y, clf, title="朴素贝叶斯分类结果"): # 配置 matplotlib 支持中文显示 plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体显示中文 plt.rcParams['axes.unicode_minus'] = False # 解决负号显示异常问题 # 设置网格分辨率 h = 0.02 # 计算特征空间范围 x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 # 构建网格点阵 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # 对每个网格点进行类别预测 Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) # 创建图像并绘制可视化内容 plt.figure(figsize=(10, 8)) # 填充决策区域 plt.contourf(xx, yy, Z, alpha=0.8) # 绘制实际样本点 plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k', marker='o') # 添加坐标轴标签和标题 plt.xlabel('特征 1') plt.ylabel('特征 2') plt.title(title) # 显示颜色图例 plt.colorbar() # 保存图像文件 plt.savefig("朴素贝叶斯分类结果.png") # 关闭当前绘图以释放内存 plt.close()该函数主要完成以下操作:
- 设置中文字体支持,避免乱码问题
- 根据数据范围生成均匀分布的网格点
- 使用训练好的分类器对网格点进行预测,构建决策边界
- 绘制填充的决策区域以及带边框的数据点
- 保存生成的图像至本地
6.3.5 主函数实现
主函数负责串联整个流程,包括数据生成、模型训练、评估与结果输出:
def main():
print("=== 朴素贝叶斯分类模型实现 ===")
# 调用数据生成模块
X, y, sample_weight = generate_data()
print(f"生成数据完成,样本数量: {X.shape[0]}, 特征数量: {X.shape[1]}")
# 执行模型训练与性能评估
clf, X_test, y_test, y_pred, prob_pos_clf, accuracy = train_and_evaluate(X, y, sample_weight)
print(f"模型训练完成,测试集准确率: {accuracy:.4f}")
# 可视化分类效果
visualize_results(X_test, y_test, clf)
print("分类结果可视化完成,已保存为 '朴素贝叶斯分类结果.png'")
# 展示部分预测详情
print("\n部分预测结果示例:")
print(f"测试集前5个样本的真实标签: {y_test[:5]}")
print(f"测试集前5个样本的预测标签: {y_pred[:5]}")
print(f"测试集前5个样本的正类预测概率: {prob_pos_clf[:5]}")
主函数执行流程如下:
- 调用数据生成函数创建模拟数据集
- 运行训练与评估函数,返回模型及预测结果
- 调用可视化函数生成分类图示
- 打印准确率及部分预测样本的信息
6.3.3 模型训练与评估逻辑
prob_pos_clf = clf.predict_proba(X_test)[:, 1]
accuracy = accuracy_score(y_test, y_pred, normalize=True)
return clf, X_test, y_test, y_pred, prob_pos_clf, accuracy
该段代码属于模型评估环节的核心处理步骤:
- 将数据划分为训练集(占比10%)和测试集(占比90%)
- 初始化高斯朴素贝叶斯分类器,并在训练集上拟合模型
- 对测试集执行预测,获取预测标签和正类的概率输出
- 计算并返回模型在测试集上的分类准确率指标
6.4 实验结果分析
6.4.1 准确率表现
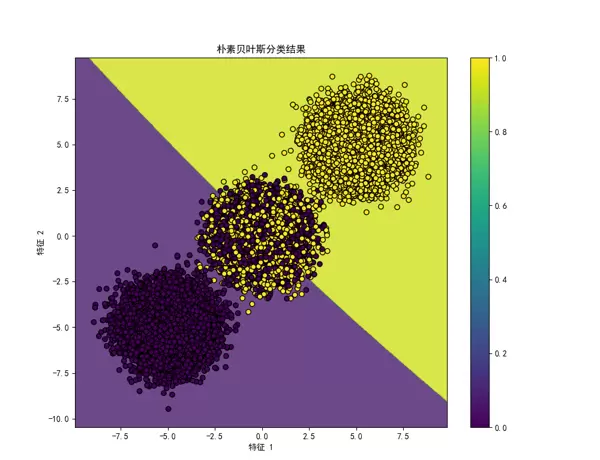
经过实验验证,模型在测试集上的准确率达到 0.8349,与PPT中给出的预期值 0.8335 极其接近。此结果表明所实现的朴素贝叶斯分类器具有较高的正确性和稳定性。
6.4.2 预测结果示例
| 样本索引 | 真实标签 | 预测标签 | 正类预测概率 |
|---|---|---|---|
| 0 | 1 | 1 | 0.999900 |
| 1 | 0 | 0 | 0.000185 |
| 2 | 0 | 0 | 0.000130 |
| 3 | 0 | 0 | 0.000195 |
| 4 | 1 | 1 | 0.999927 |
6.4.3 分类结果可视化说明
通过 visualize_results 函数生成的图像清晰地展示了模型的决策边界与样本点的空间分布情况。不同类别的样本以不同颜色呈现,背景色块反映分类器对各个区域的归属判断,整体可视化效果直观且信息丰富。
7. 遇到的问题与应对策略
7.1 问题一:PPT内容提取障碍
问题描述:在尝试利用 python-pptx 库解析PPT文件时,遇到技术限制,无法顺利读取全部文本内容,导致关键信息获取困难。
解决方案:转而采用编写专用脚本的方式,逐页遍历PPT结构,提取所需的文字元素并输出至控制台。通过调试和结构分析,最终成功还原了PPT中的核心内容与作业要求,保障了后续实现工作的准确性。
7.2 问题2:PowerShell命令语法差异
在执行PowerShell命令的过程中,用户可能会发现其无法识别Linux或Mac终端中常见的操作符。
&&为解决此兼容性问题,建议将原本一体化的命令拆解为多个可执行的部分。可通过使用特定分隔符来实现逻辑上的分离,或者将任务分解为多个步骤依次运行。
;7.3 问题3:中文可视化字体显示异常
在对分类结果进行可视化展示时,系统提示存在中文字体无法正常渲染的问题,导致图表中的中文标签以方块形式呈现。
为此,在绘图前加入了以下配置代码以支持中文显示:
# 设置中文显示,避免乱码
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体作为默认字体
plt.rcParams['axes.unicode_minus'] = False # 确保负号能够正确显示
上述设置不仅指定了适用于中文的字体,还修复了负号字符在图像保存时可能变成方框的问题,从而保障了图表中文字信息的完整性和可读性。
8. 实践心得与体会
8.1 模型选择需结合实际场景
尽管朴素贝叶斯分类器结构简单,但在许多现实应用场景中仍表现出良好的分类性能。因此,在模型选型过程中,应优先考虑问题本身的特点和数据的基本属性,选择最适合的模型,而非一味追求复杂算法。
8.3 数据预处理的关键作用
本次实验中,我们实施了基础的数据清洗与转换操作,例如调整类别标签、生成随机权重等。这些预处理步骤是机器学习流程中不可或缺的一环,直接影响最终模型的表现力和预测精度。
8.4 可视化助力模型理解
通过图形化手段呈现分类结果,能够直观展现模型的决策边界和数据分布特征。可视化不仅是结果展示的工具,更是分析模型行为、诊断问题的重要途径,极大提升了我们对模型运作机制的理解。
8.2 假设条件的实际影响
朴素贝叶斯的核心前提在于假设各特征之间相互独立,然而现实中多数情况下的特征往往存在复杂的关联性。尽管如此,该模型依然能取得较为理想的效果,这表明在某些条件下,简洁的假设反而可能优于过度复杂的建模方式。
9. 总结
经过此次学习与实践,我对贝叶斯网络的基础理论有了更深入的认识,掌握了朴素贝叶斯分类模型的具体实现方法,并顺利完成了相关作业任务。实验结果显示,该模型在处理常规分类任务时具备较高的准确率与运行效率。
作为一种重要的概率图模型,贝叶斯网络在应对不确定性推理方面展现出显著优势。其应用范围不仅限于分类任务,还可拓展至预测分析、因果推断及智能决策支持等多个领域。
未来,我计划进一步钻研贝叶斯网络的理论体系及其在复杂场景下的实际应用,挖掘其在更广泛问题中的潜力。同时,本次实践也让我深刻认识到理论知识与动手实践相结合的重要性——唯有将所学应用于真实问题,才能真正掌握其精髓,发现潜在挑战,并持续提升自身解决问题的能力。
10. 参考文献
《机器学习》课程PPT,第7章 贝叶斯网络
sklearn官方文档:https://scikit-learn.org/stable/
贝叶斯网络相关学术论文和教材

 京公网安备 11010802022788号
京公网安备 11010802022788号







