


 雷达卡
雷达卡



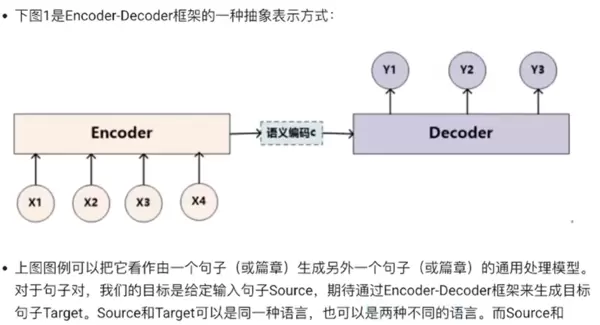
注意力机制是一种在深度学习模型中广泛使用的技术,尤其在自然语言处理和计算机视觉领域表现突出。它通过模拟人类对信息的选择性关注,使模型能够聚焦于输入数据中最相关的部分,从而提升整体性能。
Attention 机制的核心思想是为输入序列中的每个元素分配一个权重,这些权重决定了模型在处理当前任务时应给予各个部分的关注程度。该机制能够动态调整不同位置信息的重要性,增强了模型对上下文的理解能力。
Soft Attention(软注意力)是其中一种常见的实现方式。它通过对所有输入位置计算出连续的注意力权重,实现可微分的注意力分布,便于通过反向传播进行端到端训练。这种注意力方式允许模型在每一步都参考整个输入序列,具有较强的表达能力和稳定性。




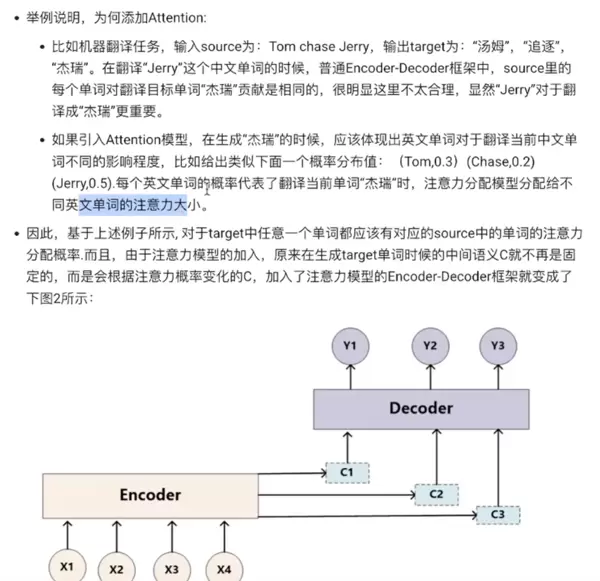

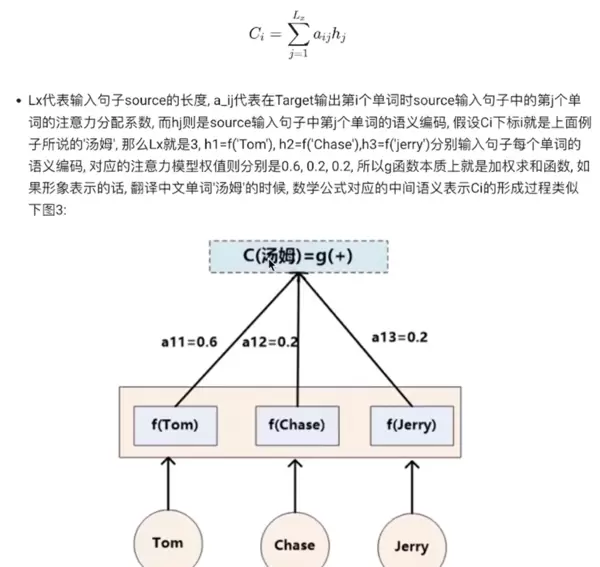
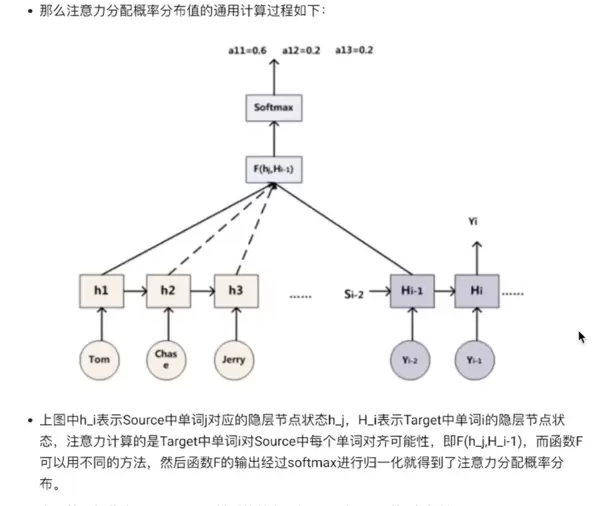
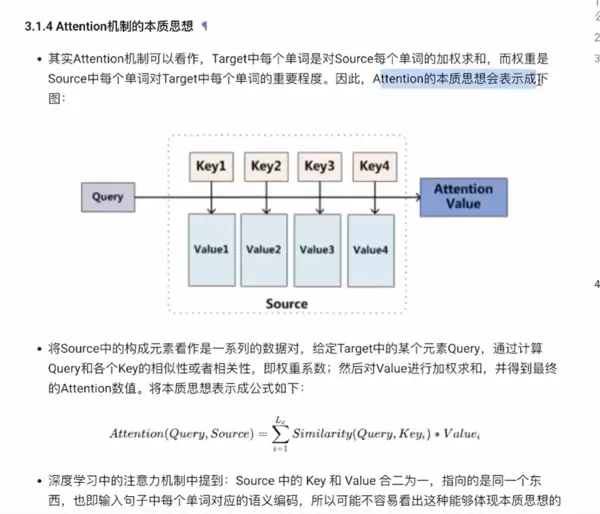
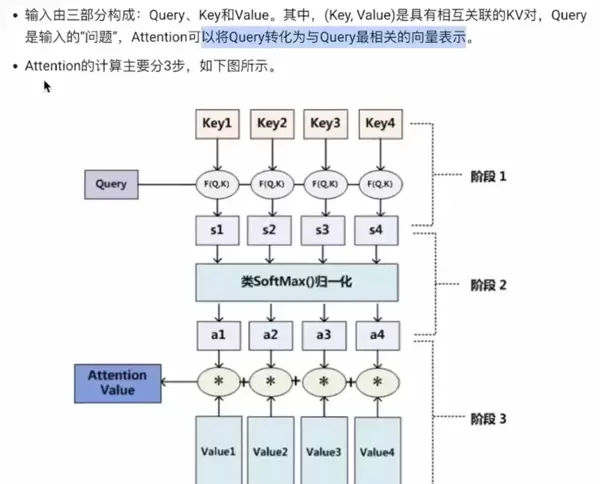

与 Soft Attention 相对的是 Hard Attention(硬注意力),它在每个时刻仅选择输入序列中的某一个特定位置进行处理,而非加权所有位置。这种方式不可微,通常需要借助强化学习等方法进行训练,虽然计算上更具挑战性,但在某些场景下能带来更高的效率和解释性。

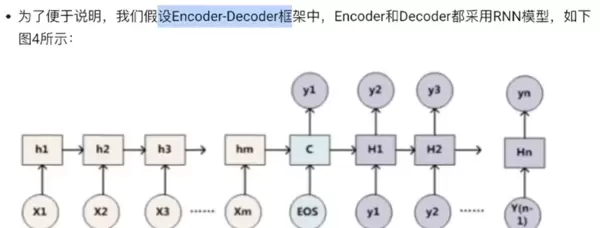
自注意力(Self-Attention)则是另一种重要的变体,常用于 Transformer 架构中。它通过计算序列内部各元素之间的相互关系,捕捉长距离依赖信息。自注意力机制使得模型能够在不依赖循环结构的情况下,高效地建模全局上下文,显著提升了并行化能力和训练速度。



 京公网安备 11010802022788号
京公网安备 11010802022788号







