


 雷达卡
雷达卡



本文深入剖析 QLoRA(Quantized Low-Rank Adaptation)的技术细节与实践方法,基于 Tim Dettmers 等人发表的论文《QLoRA: Efficient Finetuning of Quantized LLMs》,从理论到实现全面解析其高效微调机制。
一、挑战背景:大模型微调的显存瓶颈
在 QLoRA 出现之前,对大规模语言模型进行微调面临严峻的显存消耗问题:
- 全量微调:以 65B 参数的 LLaMA 模型为例,完整训练需要超过 780GB 的显存,相当于数十张 A100 显卡并行运行。
- 普通 LoRA 微调:虽然可训练参数大幅减少,但底座模型仍需以 16-bit 精度(如 BF16 或 FP16)加载。仅是加载权重就需 130GB 以上显存,单张 A100(80GB)无法承载。
QLoRA 实现了突破性进展——它能够在单张 48GB 显卡上完成 65B 模型的微调,且最终性能与 16-bit 全量微调相当。
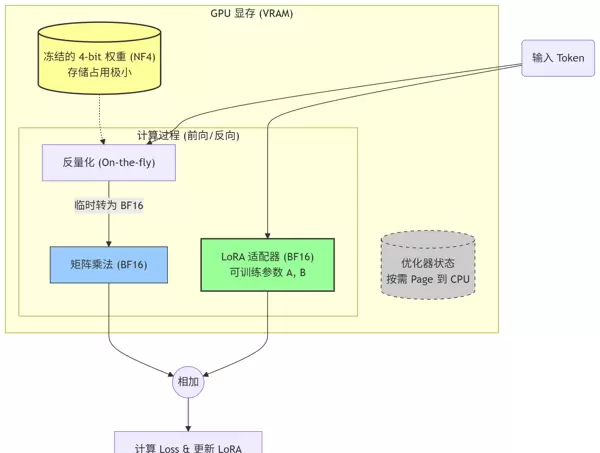
二、技术核心:QLoRA 的三大创新机制
QLoRA 并非简单地将 4-bit 量化与 LoRA 结合,而是通过三项关键技术保障精度不损失,同时极大降低资源需求。
数学表达式说明
模型输出由两部分组成:
Y = BF16(W4bit × X) (冻结的量化底座) + BF16(LBLA × X) (可训练的 LoRA 适配器)
说明:在前向计算中,4-bit 权重被动态反量化为 BF16 进行矩阵运算,计算完成后立即释放高精度副本,仅保留 4-bit 存储状态。
创新点一:4-bit NormalFloat (NF4) —— 面向正态分布优化的量化类型
传统 4-bit 量化(如 Int4 或 Float4)假设权重分布均匀,但实际上神经网络的权重多服从正态分布,集中在零值附近。
NF4 是 QLoRA 提出的一种新型数据格式,利用正态分布的累积分布函数(CDF)划分量化区间,实现更精细的数值映射。
类比理解:传统量化像“均码服装”,不适合所有体型;而 NF4 则是“量体裁衣”,专为权重分布特征设计,显著减少信息损失。
创新点二:双重量化(Double Quantization)—— 极致压缩元数据开销
问题:量化过程中需存储缩放因子(Scale Factors),通常每 64 个参数共享一个 32-bit 值,平均每个参数增加约 0.5 bit 开销。
解决方案:QLoRA 对这些缩放因子本身再次进行 8-bit 量化。
效果:将额外开销从 0.5 bit/param 降至 0.127 bit/param。对于 65B 模型,节省显存约 3GB。
创新点三:分页优化器(Paged Optimizers)—— 抵御显存溢出的利器
借助 NVIDIA 统一内存(Unified Memory)机制,当 GPU 显存不足以容纳优化器状态时,系统会自动将数据按页迁移至 CPU 内存(RAM)。
该机制如同“保险丝”,防止因短时显存峰值导致训练中断(OOM),虽可能略微降低速度,但保证了稳定性。
bitsandbytespeft三、代码实战:基于 Hugging Face 的 QLoRA 实现
实现 QLoRA 的关键依赖库包括:bitsandbytes(支持 NF4 量化)和 peft(提供 LoRA 功能)。
4.1 环境安装
pip install -q -U torch transformers peft bitsandbytes trl accelerate4.2 核心配置:启用 NF4 与双重量化
这是 QLoRA 区别于标准 LoRA 的核心所在——模型加载阶段的量化设置。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model
# ================= 1. QLoRA 核心配置 (BitsAndBytes) =================在进行模型量化与微调时,首先需要配置 BitsAndBytes 以实现低精度加载。以下是核心配置项:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 启用 4-bit 量化加载
bnb_4bit_quant_type="nf4", # 使用 NF4 数据类型(论文推荐)
bnb_4bit_use_double_quant=True, # 启用双重量化,进一步降低显存占用
bnb_4bit_compute_dtype=torch.bfloat16 # 计算过程使用 BF16,提升速度并防止数值溢出
)接下来加载预训练模型,此处以 Qwen2.5-7B-Instruct 为例:
model_id = "Qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config, # 应用上述量化配置
device_map="auto", # 自动分配模型层至可用设备
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token # 解决填充 token 缺失问题
SFTTrainer为了确保训练稳定性,在应用 LoRA 之前需对模型进行预处理:
# 冻结大部分参数,并将 LayerNorm 层转换为 fp32 以增强数值稳定性
model = prepare_model_for_kbit_training(model)
随后配置 LoRA 适配器参数。尽管使用的是 QLoRA,但此步骤与标准 LoRA 一致:
peft_config = LoraConfig(
r=64, # 秩(rank),QLoRA 可适当增大
lora_alpha=16,
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
] # 按照论文建议,对所有线性投影层进行微调
)
将配置注入原始模型,生成可训练的 PEFT 模型:
model = get_peft_model(model, peft_config)
查看当前可训练参数的规模和占比:
model.print_trainable_parameters()
# 示例输出: trainable params: 33,554,432 || all params: 7,xxx,xxx,xxx || trainable%: 0.45%
最后,结合 TRL 库中的 SFTTrainer 来简化训练流程。首先定义训练参数:
from transformers import TrainingArguments
from trl import SFTTrainer
from datasets import load_dataset
# 加载自定义数据集(JSONL 格式)
dataset = load_dataset("json", data_files="your_data.jsonl", split="train")
training_args = TrainingArguments(
output_dir="./qwen_qlora_results",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4, # 遵循 QLoRA 论文建议的学习率
logging_steps=10,
max_steps=500,
fp16=False,
bf16=True, # 若硬件支持(如 30/40 系列或 A100),强烈建议启用
optim="paged_adamw_32bit", # 关键设置:使用分页优化器避免内存峰值
save_strategy="steps",
save_steps=100,
warmup_ratio=0.03,
group_by_length=True, # 按长度分组样本,提高训练效率
)
初始化 SFTTrainer 实例:
trainer = SFTTrainer(
model=model,
train_dataset = dataset,
peft_config = peft_config,
dataset_text_field = "text",
max_seq_length = 1024,
args = training_args,
)
print("开始 QLoRA 微调...")
trainer.train()
# 保存 LoRA 权重
trainer.model.save_pretrained("./final_adapter")
第五部分:显存占用对比分析
QLoRA 为何能在显存使用上如此高效?以下以一个参数量为 7B 的模型为例进行详细计算:
| 组件 | 全量微调 (FP16) | 普通 LoRA (FP16) | QLoRA (NF4) |
|---|---|---|---|
| 模型权重 | 14 GB (16-bit) | 14 GB (16-bit) | ~3.5 GB (4-bit) |
| 梯度 (Gradients) | 14 GB | 极小 (仅 LoRA 部分) | 极小 (仅 LoRA 部分) |
| 优化器状态 | 28 GB (AdamW) | 极小 (仅 LoRA 部分) | 极小 + 可 Page 到 CPU |
| 激活值 (Activations) | 取决于 Batch/SeqLen | 取决于 Batch/SeqLen | 同 LoRA |
| 总计显存需求 | > 60 GB | ~20 GB | ~6-8 GB |
结论:得益于极低的显存消耗,QLoRA 使得 7B 规模的模型能够在配备 8GB 显存的消费级显卡(如 RTX 3070 或 4060 Ti)上顺利运行;而对于更大的 70B 模型,则可在双卡 3090/4090 或单张 A6000 上完成微调任务。
第六部分:QLoRA 的局限性与避坑指南
尽管 QLoRA 具备显著优势,但在实际应用中仍需注意以下几个关键问题:
- 推理速度略慢:
由于在推理过程中需要频繁执行
(从 4-bit 解压到 16-bit)以及Dequantize
,整体推理速度通常比原生 FP16 模型慢 20% 至 30%。Quantize
解决方案:训练完成后,将训练得到的 Adapter 权重合并至原始基座模型,并以 FP16 格式保存。这样可恢复接近原生的推理性能。
- 无法直接合并回 4-bit 基座:
训练生成的 FP16 精度 LoRA 权重不能直接加载到 4-bit 量化的基座模型上,否则会因精度不匹配导致错误。
正确做法:应先加载完整精度(16-bit)的基座模型,完成 LoRA 权重合并后,再根据需要对合并后的模型进行量化处理。
- 超参数敏感度较高:
虽然 QLoRA 对
具有一定容忍度,但仍推荐采用learning_rate
进行配置。2e-4
将
设置为lora_dropout
或0.05
,有助于提升训练过程的稳定性和最终收敛效果。0.1
总结
QLoRA 是推动大模型微调走向平民化的重要技术里程碑。
原理层面:通过引入 NF4 数据类型、双重量化机制以及支持分页的优化器策略,在几乎不损失模型精度的前提下,极大压缩了显存占用。
实现层面:仅需数行代码即可集成并启用 QLoRA 微调流程,
BitsAndBytesConfig应用价值:该技术赋予个人开发者和中小企业自主定制私有化大模型的能力,摆脱对公有云 API 的依赖。
如今,只需一块普通的 RTX 系列显卡,你就能训练出一个真正理解自身业务逻辑的专属语言模型。

 京公网安备 11010802022788号
京公网安备 11010802022788号







