


 雷达卡
雷达卡



AquaCrop模型是一种专注于提升农作物水分生产效率的研究工具,广泛应用于全球农业水资源管理领域。该模型在制定科学灌溉方案以及应对水资源短缺问题方面展现出高度的实用价值。
一:模型原理与数据要求
本节介绍AquaCrop的核心理论基础及其所需输入信息的基本框架。
1. 模型基本原理与计算框架
模型基于作物蒸散与生物量累积之间的关系构建,通过模拟冠层覆盖度动态变化来估算产量响应水分状况的过程。其核心在于水分生产力分析,能够精确反映不同水环境下作物生长表现。
2. AquaCrop模型的应用范围
适用于多种气候区和耕作系统,可用于单季或多季作物模拟,支持从田间到区域尺度的水资源评估与优化管理。
3. 模型输入数据要求
运行模型需提供气象、土壤、作物特性和田间管理措施等多类数据,确保模拟结果具有代表性与准确性。
4. 模型应用实例简介
已有大量研究将AquaCrop应用于小麦、玉米、水稻等主要粮食作物的水分管理实践中,验证了其在实际生产中的有效性与适应性。
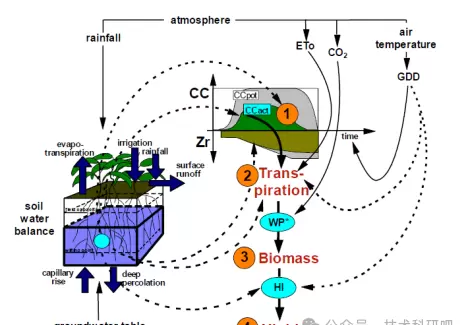
二:模型数据制备
高质量的数据是保证模拟精度的前提,以下为关键数据准备内容:
1. 农作物数据制备
包括作物种类、典型生长周期、关键生育阶段划分及对应水分敏感性特征,用于定义模型中作物响应机制。
2. 气象数据准备
需要日尺度的气温(最高、最低)、降水量、太阳辐射及参考蒸散量等参数,以驱动模型的能量与水分平衡计算。
3. 土壤数据制备
涵盖土壤质地分类、有效持水能力、田间持水量、萎蔫点及渗透特性等指标,影响根区水分动态模拟精度。
4. 管理措施的输入
设定灌溉策略(如滴灌、漫灌)、施肥时间与量、病虫害防治操作等人为干预行为,体现实际农田管理情景。

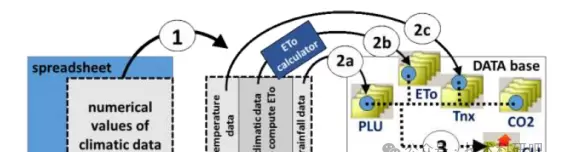
三:模型运行及结果分析
了解如何执行模型并解读输出结果对于实际应用至关重要。
1. 模型运行步骤
按照预设的数据格式导入各类输入文件,配置模拟时段与边界条件后启动运算流程,完成从初始化到结束的全过程模拟。
2. 模型输出
生成包括每日冠层发育、土壤水分状态、累积蒸散、生物量及最终产量在内的多项变量序列,支持进一步统计处理。
3. 模型结果分析(在线版)
利用可视化平台对输出结果进行图形化展示,便于识别趋势变化、异常点及关键影响因素,提升决策支持能力。
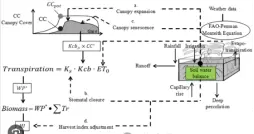

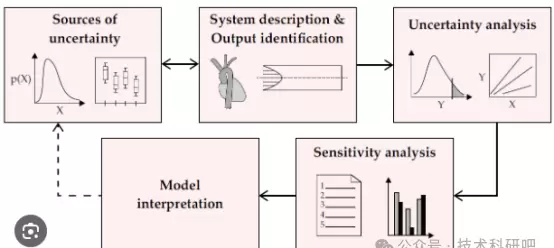
四:参数分析
深入理解模型参数的行为有助于提高模拟可靠性。
1. 敏感性分析方法
采用局部或全局敏感性分析技术,识别对输出波动贡献最大的关键参数组合。
2. 模型敏感参数
如归一化水分生产力系数、最大冠层覆盖度、根系扩展速率等常被确认为主要敏感因子。
3. 参数的不确定性分析方法
结合蒙特卡洛模拟或其他概率方法量化参数变异带来的预测区间波动。
4. 参数的不确定性分析
评估由于测量误差或经验取值导致的参数不确定对整体模拟结果的影响程度。
5. 参数调优建议
依据实测数据进行校准,优先调整高敏感且存在较大误差空间的参数,以提升模型拟合度。
五:源代码分析
针对希望深入了解模型内部机制的技术用户,可通过对源码的解析实现定制化开发。
1. 模型代码结构
整体采用模块化设计,各功能单元分工明确,便于维护与扩展。
2. 模型入口分析
主程序启动逻辑清晰,负责协调数据读取、初始化设置与循环计算过程。
3. 模型主要计算功能分析
核心算法集中于冠层动态模拟、水分胁迫判定及产量形成建模等关键环节。
4. 现代Fortran基础
掌握现代Fortran语法特性(如模块、派生类型、接口等)是理解和修改代码的基础。
5. 模型Fortran代码编译
使用兼容的Fortran编译器(如gfortran、Intel Fortran)进行项目构建,确保无语法错误并生成可执行文件。

 京公网安备 11010802022788号
京公网安备 11010802022788号







