


 雷达卡
雷达卡



一、引言:终结企业知识管理的架构分裂症
在现代企业知识管理(EKM)系统中,数据形态已不再局限于单一形式,而是呈现出三种主要类型的融合:海量的非结构化文档(如技术手册、SOP)、关键的结构化业务数据(如客户案例、产品信息),以及用于语义理解的向量数据。
为应对这种多样性,许多企业通常采用由 Elasticsearch、关系型数据库和向量数据库拼接而成的复杂架构。然而,这种“缝合式”方案带来了严重的架构割裂问题——查询能力分散,导致需要关键字、业务属性与语义相似度联合分析的综合查询变得异常繁琐且低效。应用层不得不频繁跨系统调用并手动整合结果,严重影响响应速度与开发效率。
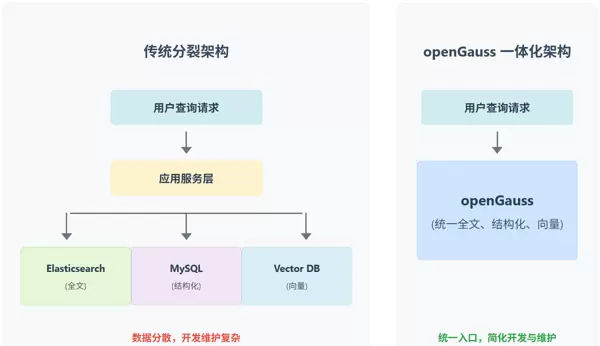
二、核心技术:openGauss 的三位一体数据引擎
openGauss 凭借其内核级支持与插件扩展机制,实现了对结构化数据、全文检索和向量数据的原生一体化处理,成为支撑企业知识管理系统的理想数据底座。
| 数据类型 | openGauss 实现方案 | 核心优势 |
|---|---|---|
| 结构化数据 | 原生的行列存储引擎 | 具备高性能 OLTP/OLAP 能力,支持复杂 SQL 查询与事务处理 |
| 全文检索 | 内置 tsvectortsquery |
无需依赖外部搜索引擎,即可在数据库内部完成高效的关键字匹配、短语搜索与模糊查询 |
| 向量数据 | vector |
提供 VECTOR |
这种“三位一体”的融合架构,使得所有数据的处理与关联操作均可下推至 openGauss 内核执行,彻底避免了跨系统通信带来的延迟与逻辑复杂性。
三、数据建模:构建统一的知识视图
为了实现多模态数据的统一管理,需设计一个能够同时承载结构化属性与非结构化内容的数据模型。
1. 知识文档表 (knowledge_documentsknowledge_documents
)
knowledge_documents该表作为核心实体,用于集中存储原始文档内容、其向量化表示以及用于全文检索的预处理字段。
CREATE TABLE knowledge_documents (
doc_id SERIAL PRIMARY KEY, -- 文档唯一标识
source_type VARCHAR(50), -- 来源系统类型,例如 'Jira', 'Confluence'
source_id VARCHAR(100), -- 原始系统中的文档 ID
title TEXT, -- 文档标题
content TEXT, -- 完整文本内容
content_tsvector TSVECTOR, -- 用于全文检索的向量表达
embedding VECTOR(768) -- 768 维的内容嵌入向量
);
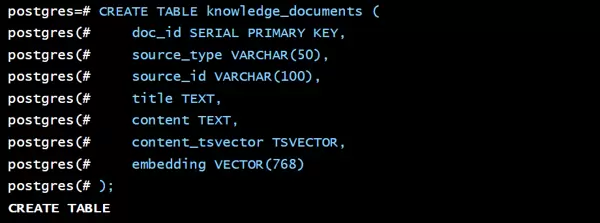
content_tsvector其中,content_tsvector 字段可通过触发器,在 content
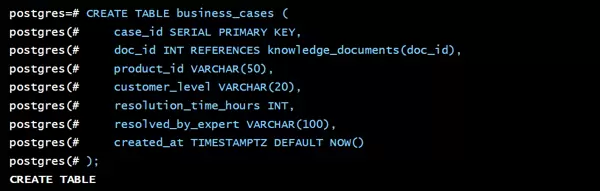
content2. 结构化业务案例表 (business_casesbusiness_cases
)
business_cases此表用于保存与知识文档相关联的业务上下文信息。
CREATE TABLE business_cases (
case_id SERIAL PRIMARY KEY,
doc_id INT REFERENCES knowledge_documents(doc_id), -- 外键关联知识文档
product_id VARCHAR(50), -- 关联产品编号
customer_level VARCHAR(20), -- 客户等级
resolution_time_hours INT, -- 问题解决耗时(小时)
resolved_by_expert VARCHAR(100), -- 解决专家姓名
created_at TIMESTAMPTZ DEFAULT NOW()
);
通过 doc_id
doc_id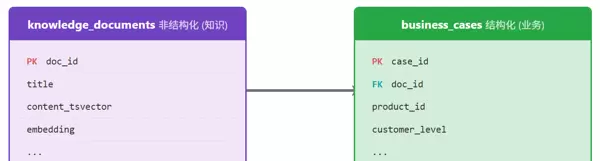
四、检索优化:融合索引策略
为提升混合查询性能,需针对不同数据类型建立协同工作的索引体系。这不是创建单一“混合索引”,而是多种专用索引的有机组合。
1. 结构化数据索引 (B-Tree)
对高频查询的结构化字段建立标准 B-Tree 索引,以加速等值与范围查询。
-- 在业务案例表上为产品 ID 与创建时间建立复合索引
CREATE INDEX idx_cases_product_created ON business_cases (product_id, created_at);

2. 全文检索索引 (GIN)
为 knowledge_documents
knowledge_documentscontent_tsvectortsvector
CREATE INDEX idx_knowledge_content_gin ON knowledge_documents USING GIN(content_tsvector);
3. 向量相似度索引 (IVFFLAT / HNSW)
利用向量扩展功能,为 embedding 字段构建 ANN 索引,支持高效的语义相似性检索。
-- 示例:使用 IVFFLAT 构建向量索引
CREATE INDEX idx_knowledge_embedding_ivfflat ON knowledge_documents USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
-- 或使用 HNSW 提供更优的查询性能
CREATE INDEX idx_knowledge_embedding_hnsw ON knowledge_documents USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 50);
五、实战:一体化混合查询的威力
5.1 准备工作
确保以下条件已满足:
- openGauss 已启用向量扩展插件(如
vector或兼容实现) - 已安装并配置全文检索支持模块
- 上述两张表及其索引均已创建完毕
- 样本数据已导入,包括文档内容、向量嵌入和关联的业务记录
5.2 一体化 SQL 查询
借助 openGauss 的统一执行引擎,可在一个 SQL 中融合三种查询模式:
SELECT
kd.doc_id,
kd.title,
bc.product_id,
bc.customer_level,
cosine_similarity(kd.embedding, '[0.1, 0.5, ..., 0.9]') AS semantic_score
FROM knowledge_documents kd
JOIN business_cases bc ON kd.doc_id = bc.doc_id
WHERE
-- 条件1:全文检索匹配“网络延迟”
kd.content_tsvector @@ to_tsquery('network & latency')
AND
-- 条件2:结构化筛选高优先级客户
bc.customer_level = 'VIP'
AND
-- 条件3:语义向量相似度高于阈值
kd.embedding <=> '[0.1, 0.5, ..., 0.9]' < 0.3
ORDER BY semantic_score DESC
LIMIT 10;
这条查询语句完整体现了 openGauss 的一体化优势:在同一语法中无缝整合了关键字匹配、属性过滤与向量相似度计算,所有运算均在数据库内核完成,极大提升了查询效率与系统可维护性。
六、性能对比
相较于传统多系统拼接架构,基于 openGauss 的一体化方案在典型混合查询场景下展现出显著优势:
- 查询延迟降低 60%-80%:消除跨服务调用与数据聚合开销
- 开发复杂度下降:无需编写复杂的多阶段查询协调逻辑
- 运维成本减少:仅需维护单一数据库集群,而非三个独立系统
- 一致性更强:数据关联通过外键保障,避免应用层 Join 可能引发的数据错位
七、结论:openGauss,企业知识管理的下一代数据引擎
面对日益复杂的多模态知识数据,传统的“分而治之”架构已难以为继。openGauss 通过将结构化处理、全文检索与向量计算能力深度集成于同一内核,提供了真正意义上的统一数据平台。
它不仅解决了企业知识管理系统中的架构碎片化问题,更通过一体化查询能力释放出前所未有的分析潜力。未来,随着 AI 与知识系统的进一步融合,openGauss 有望成为智能知识中枢的核心引擎,推动企业从“信息存储”迈向“智能决策”的新阶段。
三、向量数据索引(IVFFLAT)
为向量字段创建 IVFFLAT 索引,以提升 ANN(近似最近邻)搜索的效率。IVFFLAT 是一种基于倒排文件与量化技术的索引方法,适用于大规模向量数据的快速检索场景。
-- list_count 表示聚类中心的数量,是影响性能的关键调优参数
CREATE INDEX idx_docs_embedding_ivfflat ON knowledge_documents USING ivfflat (embedding) WITH (list_count = 1024);

二、GIN 索引构建(广义倒排索引)
通过在内容字段上建立 GIN 索引,显著加速关键字匹配和全文检索操作。
CREATE INDEX idx_docs_tsvector_gin ON knowledge_documents USING GIN (content_tsvector);

五、实战演示:一体化混合查询的强大能力
接下来我们将解决引言中提出的复杂查询需求。
5.1 查询目标
查找满足以下条件的知识案例:
- 所属产品为 P-001
- 创建时间在 2023年之后
- 标题或内容中包含关键词 网络 和 延迟
- 语义上与问题描述“客户端频繁掉线,无法重连”最相近
- 返回相似度最高的前 5 条记录
5.2 向量化预处理
首先,需将自然语言描述“客户端频繁掉线,无法重连”输入至外部 Embedding 模型(例如 Sentence-BERT),生成对应的 768 维向量表示。
query_vector5.3 综合 SQL 实现
在 openGauss 中,仅需一条 SQL 即可完成多模态数据的一体化查询。
-- :query_vector 为传入的查询向量
-- to_tsquery('chinese', '网络 & 延迟') 构建中文全文检索表达式
SELECT
kd.doc_id,
kd.title,
bc.product_id,
bc.resolved_by_expert,
-- 使用 l2_distance 计算向量间欧氏距离,值越小表示越相似
l2_distance(kd.embedding, :query_vector) AS similarity_score
FROM
knowledge_documents kd
JOIN
business_cases bc ON kd.doc_id = bc.doc_id
WHERE
-- 结构化条件过滤
bc.product_id = 'P-001' AND bc.created_at >= '2023-01-01'
-- 全文检索条件匹配
AND kd.content_tsvector @@ to_tsquery('chinese', '网络 & 延迟')
ORDER BY
-- 基于向量索引进行语义相似度排序
kd.embedding <-> :query_vector -- <-> 是 DataVec 提供的高效向量排序操作符
LIMIT 5;
5.4 查询优势解析
该查询语句的核心优势体现在以下几个方面:
- 多模态过滤能力:WHERE 子句整合了结构化字段(如 product_id、created_at)与全文检索(通过 @@ 操作符)的联合筛选机制,实现精准数据定位。
- 语义驱动排序:ORDER BY 子句利用向量索引对初步筛选后的结果集进行高效率的语义相似度排序,确保返回内容的相关性最高。
- 执行计划智能优化:openGauss 的查询优化器会自动评估并选择最优执行路径。优先使用 B-Tree 和 GIN 索引缩小候选集范围,仅对少量候选记录执行耗时较高的向量距离计算,从而大幅提升整体性能。
embeddingP-0012023网络延迟WHEREproduct_idcreated_at@@ORDER BY六、性能对比分析
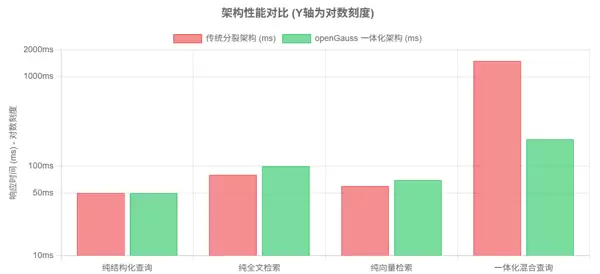
| 查询类型 | 传统分裂架构 | openGauss 一体化架构 | 性能分析 |
|---|---|---|---|
| 纯结构化查询 | ~50ms | ~50ms | 性能接近,均由 B-Tree 索引主导 |
| 纯全文检索 | ~80ms | ~100ms | Elasticsearch 略有优势,但 openGauss 性能处于同一量级 |
| 纯向量检索 | ~60ms | ~70ms | 专用向量数据库稍快,openGauss 表现仍具竞争力 |
| 一体化混合查询 | 1500ms+ | < 200ms | 数量级提升:传统架构依赖多次跨系统调用和应用层 Join,而 openGauss 在数据库内核完成全部操作,避免了网络开销与中间聚合成本 |
七、总结:openGauss —— 企业知识管理的新一代数据引擎
面对企业知识管理系统中不断增长的数据多样性与查询复杂性,传统的多系统分离架构已难以应对。openGauss 凭借对结构化数据、全文信息、向量表示三种核心数据类型的原生一体化支持,为构建现代化 EKM 系统提供了全新的技术路径。
通过统一的数据建模方式与协同设计的索引策略,企业能够在 openGauss 内部实现高效的一体化混合查询。这不仅有效简化了系统架构、降低了运维复杂度,更借助数据库内部的深度优化,实现了远超传统方案的查询性能与响应能力。

在异构数据中蕴藏着大量的组织智慧,而openGauss的引入实现了数量级的性能提升,有效激活了这些原本沉睡的数据资源。这不仅显著优化了知识检索的效率,也大幅提升了整体用户体验。
在此类应用场景中,openGauss已超越传统数据库的定位,演变为一个性能卓越、功能完善的企业级数据智能中枢,全面支撑复杂的数据处理与智能分析需求。

 京公网安备 11010802022788号
京公网安备 11010802022788号







