


 雷达卡
雷达卡



RAG-ARC:新一代模块化检索增强生成框架
检索增强生成(RAG)技术凭借其动态知识更新能力、较高的性价比以及出色的落地适应性,至今仍是构建大语言模型(LLM)应用的核心架构之一。然而,随着应用场景日益复杂,单一的技术路线已难以全面满足多样化需求。
当前主流的 RAG 解决方案如 LightRAG、RAG-Flow 与 GraphRAG 各有侧重:
- LightRAG 注重轻量高效,但在处理复杂推理任务时可能表现受限;
- RAG-Flow 强调流程自动化和开箱即用体验,在应对高度定制化的企业级场景时灵活性不足;
- GraphRAG 擅长深度语义推理,但其高昂的图构建与计算成本限制了广泛应用。
是否有可能在效果、成本与灵活性之间实现更优平衡?
为此,数创弧光(DataArc)正式开源全新一代 RAG 框架——RAG-ARC。
以处理 750k token 文本为例:
- GraphRAG 构建耗时超过 20 小时;
- LightRAG 缩短至 105 分钟;
- 而 RAG-ARC 仅需 8 分钟!

什么是 RAG-ARC?
RAG-ARC 是一个模块化的检索增强生成框架,致力于提供功能全面、架构灵活且运行高效的工程化解决方案。它支持多路径检索、图结构提取及融合排序机制,有效应对非结构化文档(如 PDF、PPT、Excel 等)处理中的关键挑战,包括信息丢失、检索准确率低以及多模态内容识别困难等问题。
设想一种场景:你的 RAG 系统可以像“搭乐高”一样,根据实际需要(例如简单问答或复杂推理)自由组合最优组件——这正是 RAG-ARC 的设计理念。
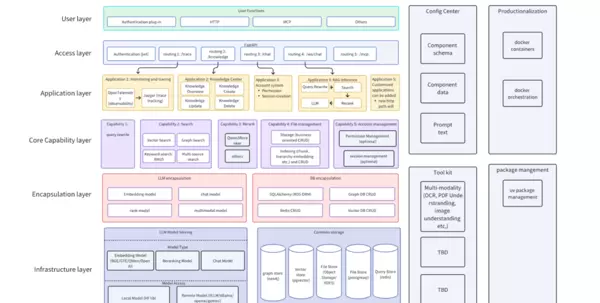
图1 ?RAG-ARC 系统架构概览
如上图所示,RAG-ARC 采用清晰的分层结构:
- 文档解析
- 多路径检索
- 融合排序
- 生成输出
数据层:支持多种格式文档解析(DOCX、PDF、PPT、Excel、HTML等),具备 OCR 识别与布局分析能力,确保原始信息完整提取。
核心层:集成文本分块、向量化、多路径检索、图结构抽取与重排序等功能模块,提升整体检索质量与效率。
应用层:提供统一 API 接口和业务逻辑封装,兼容标准 RAG 与高级 GraphRAG 模式,便于快速集成与扩展。
该设计赋予开发者对全流程的精细控制能力,实现高度可定制化部署。
核心优势对比
从工程实践与业务价值角度出发,我们将 RAG-ARC 与 GraphRAG、LightRAG、RAG-Flow 等主流框架进行系统性对比分析:
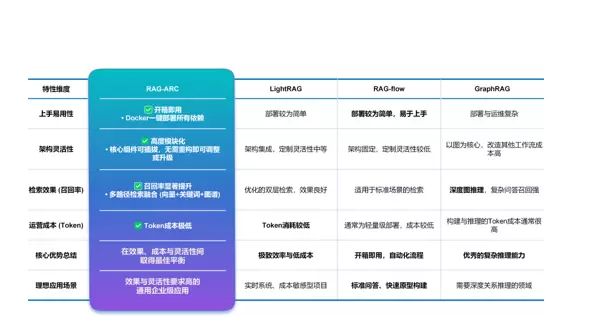
图2 ?RAG-ARC 与主流 RAG 框架对比
各框架特点分明:
- GraphRAG:擅长复杂推理;
- LightRAG:追求极致轻量;
- RAG-Flow:强调自动化流程体验;
- RAG-ARC:通过模块化设计、多路径检索融合机制及显著的 Token 成本优化,在效果、灵活性与运营成本之间达成优异平衡。
RAG-ARC 展现出均衡而强大的综合能力,成为面向复杂企业级应用的理想选择。
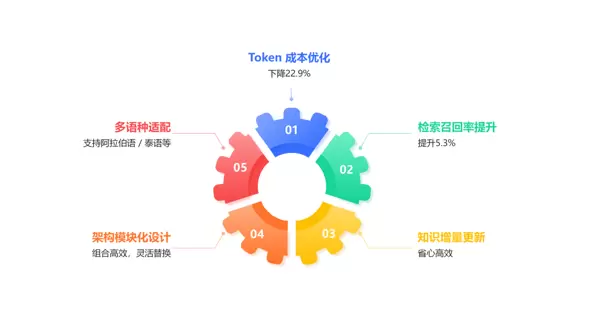
图3 ?RAG-ARC 展现“五边形”综合能力
RAG-ARC 主要优势
显著降低 Token 成本
在 HippoRAG2 基础上优化提示词策略与检索逻辑,平均 Token 消耗降低 22.9%。相同预算下,模型可处理更多对话或更复杂的查询请求。
提升检索稳定性
针对“信息找不全”的常见问题,优化检索路径与剪枝机制,整体召回率提升 5.3%,系统更能稳定捕捉隐藏的关键内容。
简化知识更新流程
支持知识图谱的增量更新。新增文档无需全量重构图谱,大幅减少维护成本与等待时间,提升运维效率。
增强系统架构灵活性
所有核心组件均采用模块化设计,检索器、大模型等模块可按需替换,如同拼接乐高积木。用户可自由搭配技术栈或独立升级某一部件,无需重构整个系统。
支持小语种扩展
具备阿拉伯语、泰语等小语种的文本检索与 OCR 识别能力,更好服务于阿拉伯地区及泰国市场,助力全球化部署。
GitHub 地址:
https://github.com/DataArcTech/RAG-ARC
若您认为该项目具有参考价值,欢迎给予 Star 支持并分享给更多开发者。同时,我们鼓励您通过 Issue 提交反馈与建议,共同推动 RAG-ARC 的持续迭代与完善。
支持阿拉伯语、泰语等多种语言的Embedding模型,结合专业级OCR引擎,能够高效应对阿语复杂的书写结构与泰语独特的语法体系。
简而言之:性能更强,资源消耗更低,维护更简便,部署更灵活,并具备对小语种的良好支持能力。
若希望了解RAG-ARC在HotpotQA、2Wiki、Musique三大复杂问答数据集上的实际表现,请继续浏览至本文第3部分——RAG-ARC实战效果。
适用场景
企业级知识库与客服系统
痛点:企业内部的技术手册、产品文档和客户案例常分散于多种格式文件中,导致客服人员难以快速定位准确信息。
RAG-ARC解决方案:
- 统一处理PDF、PPT、Excel等多类型文档
- 增量更新机制支持新文档上线而无需重建整个知识库
- Token使用成本降低22.9%,显著提升大规模客服对话场景下的经济性
- 采用多路径检索策略,同时支持语义理解与字面匹配,无论是解析业务描述还是查找具体产品型号,均可精准命中
法律咨询与案例检索
痛点:法律从业者需精确检索相关法条与判例,传统关键词搜索易遗漏语义相近但表述不同的关键内容。
RAG-ARC解决方案:
- 多路径检索确保法条的精确匹配与判例的语义相似性双重覆盖
- 引入重排序机制,将最相关的判例优先展示
- 支持法律文档版本管理与变更追溯,适应法规持续更新的需求
金融风控与合规审查
痛点:金融机构需分析海量交易记录与监管文件,识别潜在且复杂的风险模式。
RAG-ARC解决方案:
- 通过知识图谱挖掘实体间的隐性关联(例如多个交易方背后的实际控制人)
- 支持增量更新,快速响应频繁变动的监管政策
- 模块化架构便于接入实时数据流,实现动态风险监测
个人知识管理
痛点:个人积累的阅读笔记、收藏文章及工作文档缺乏有效组织,难以高效检索。
RAG-ARC解决方案:
- 轻量级部署方案适合个人用户本地运行
- 兼容PDF、Excel、Markdown、HTML等常见文档格式
- 语义检索功能支持自然语言查询,例如:“我记得去年看过一篇关于注意力机制优化的文章”
RAG-ARC 详细上手教程
环境安装
仅需几行代码即可创建所需模块。用户可根据已有模块或自定义构建专属工作流。
git clone https://github.com/DataArcTech/RAG-ARC.git
cd RAG-ARC
uv sync ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??
source .venv/bin/activate ?# 激活环境
cp .env.example .env ? ? # 创建环境配置,密钥等在里面,根据说明填入key当前可用模块及其配置代码可在以下位置获取:
config通过标准配置即可完成相应模块的初始化。
chat模块
import?json
from dotenv?import?load_dotenv
load_dotenv()
from config.encapsulation.llm.chat.openai?import?OpenAIChatConfig
JSON_CONFIG?=?"""
{
? ? "type": "openai_chat",
? ? "model_name": "gpt-4o-mini"
}
"""
# 注意,需要先在.env上填入相应的key
def?main(query: str)?-> None:
? ? config_data?= json.loads(JSON_CONFIG)
? ? llm_config = OpenAIChatConfig.model_validate(config_data)
? ? llm = llm_config.build() ? # 只需要两行代码即可完成llm的创建
? ? messages = [
? ? ? ? {"role":?"system",?"content":?"You are a helpful Chinese assistant."},
? ? ? ? {"role":?"user",?"content": query}
? ? ]
? ? response = llm.chat(messages)
? ? print("\nResponse:")
? ? print(response)
if?__name__ ==?"__main__":
? ? main("你是谁?")Extractor模块
该模块依赖于chat模块,通过调用大语言模型(LLM)实现三元组抽取任务。
对于存在依赖关系的模块,可通过嵌套方式进行配置。如下示例所示,在创建extractor时,内嵌了chat模块的完整配置。
import?asyncio
import?json
from pprint?import?pprint
from dotenv?import?load_dotenv
load_dotenv()
from config.core.file_management.extractor.hipporag2_extractor_config?import(
? ? HippoRAG2ExtractorConfig,
)
from encapsulation.data_model.schema?import?Chunk
JSON_CONFIG?=?"""
{
? ? "type": "hipporag2_extractor",
? ? "llm_config": {
? ? ? ? "type": "openai_chat",
? ? ? ? "model_name": "gpt-4o-mini"
? ? },
? ? "max_concurrent": 2 ? ? ? ? ? # 并发数量,该参数控制并发数量
}
"""
async def?main():
? ? config_data?= json.loads(JSON_CONFIG)
? ? extractor_config = HippoRAG2ExtractorConfig.model_validate(config_data)
? ? extractor = extractor_config.build()
? ? chunks = [
? ? ? ? Chunk(
? ? ? ? ? ? content=(
? ? ? ? ? ? ? ??"OpenAI 是一家人工智能研究机构,成立于 2015 年。"
? ? ? ? ? ? ? ??"其目标是确保通用人工智能造福全人类。"
? ? ? ? ? ? )
? ? ? ? ),
? ? ? ? Chunk(
? ? ? ? ? ? content=(
? ? ? ? ? ? ? ??"萨姆·阿尔特曼是 OpenAI 的联合创始人兼 CEO,长期关注 AI 安全问题。"
? ? ? ? ? ? )
? ? ? ? ),
? ? ? ? Chunk(
? ? ? ? ? ? content=(
? ? ? ? ? ? ? ??"微软于 2019 年与 OpenAI 建立战略合作关系,双方在云算力上紧密协作。"
? ? ? ? ? ? )
? ? ? ? ),
? ? ]
? ? processed_chunks =?await?extractor(chunks)
? ??for?idx, chunk in?enumerate(processed_chunks, start=1):
? ? ? ??print(f"=== Chunk #{idx} ===")
? ? ? ??pprint(chunk.graph.entities)
? ? ? ??pprint(chunk.graph.relations)
? ? ? ??print()
if?__name__?==?"__main__":
? ? asyncio.run(main())Embedding模块
import?json
from dotenv?import?load_dotenv
load_dotenv()
from config.encapsulation.llm.embedding.qwen?import?QwenEmbeddingConfig
JSON_CONFIG?=?"""
{
? ? "type": "qwen_embedding",
? ? "loading_method": "huggingface",
? ? "model_name": "sentence-transformers/all-MiniLM-L6-v2", ? ? # 模型名称或者模型路径
? ? "device": "cuda:0",
? ? "use_china_mirror": true ? ? ?# 是否使用国内镜像源
}
"""
def?main()?-> None:
? ? config_data?= json.loads(JSON_CONFIG)
? ? embedding_config = QwenEmbeddingConfig.model_validate(config_data)
? ? embedding_model = embedding_config.build()
? ? texts = [
? ? ? ??"OpenAI 于 2015 年成立。",
? ? ? ??"萨姆·阿尔特曼是 OpenAI 的 CEO。"
? ? ]
? ??
? ? embeddings = embedding_model.embed(texts)
? ??
? ??for?text,?vector in?zip(texts, embeddings):
? ? ? ??print(f"文本: {text}")
? ? ? ??print(f"向量维度: {len(vector)}")
if?__name__?==?"__main__":
? ? main()GraphStore模块
此模块需依赖Embedding模型以完成向量化存储。
import?json
from pprint?import?pprint
from dotenv?import?load_dotenv
load_dotenv()
from config.encapsulation.database.graph_db.pruned_hipporag_igraph_config?import(
? ? PrunedHippoRAGIGraphConfig,
)
from encapsulation.data_model.schema?import?Chunk, GraphData
GRAPH_CONFIG_JSON?=?"""
{
? ? "type": "pruned_hipporag_igraph",
? ? "storage_path": "./data/demo_graph_index",
? ? "add_synonymy_edges": true, ? ?# 同义边,启动后可以提高召回率
? ? "embedding": { ? ? ? ?# 嵌入子模块
? ? ? ? "type": "qwen_embedding",
? ? ? ? "loading_method": "huggingface",
? ? ? ? "model_name": "sentence-transformers/all-MiniLM-L6-v2",
? ? ? ? "device": "cpu",
? ? ? ? "cache_folder": "./models/all-MiniLM-L6-v2",
? ? ? ? "use_china_mirror": true
? ? }
}
"""
def?build_sample_graph_data()?-> Chunk:
? ? entities?= [
? ? ? ? {"id":?"e1",?"entity_name":?"OpenAI",?"entity_type":?"组织",?"attributes": {}},
? ? ? ? {"id":?"e2",?"entity_name":?"2015年",?"entity_type":?"日期",?"attributes": {}},
? ? ? ? {"id":?"e3",?"entity_name":?"萨姆·阿尔特曼",?"entity_type":?"人物",?"attributes": {}},
? ? ? ? {"id":?"e4",?"entity_name":?"CEO",?"entity_type":?"职位",?"attributes": {}},
? ? ]
? ? relations = [
? ? ? ? ["OpenAI",?"成立于",?"2015年"],
? ? ? ? ["萨姆·阿尔特曼",?"担任",?"CEO"]
? ? ]
? ? graph_data = GraphData(entities=entities, relations=relations, metadata={"source":?"demo"})
? ? chunk = Chunk(
? ? ? ? id="chunk-demo-1",
? ? ? ? content="OpenAI 于 2015 年成立,萨姆·阿尔特曼担任 CEO。",
? ? ? ? graph=graph_data,
? ? )
? ??returnchunk
def?main()?-> None:
? ? config_data?= json.loads(GRAPH_CONFIG_JSON)
? ? graph_config = PrunedHippoRAGIGraphConfig.model_validate(config_data)
? ? graph_store = graph_config.build()
? ? chunk = build_sample_graph_data()
? ? # 直接在 Chunk 上附加抽取结果,然后使用 build_index 批量入库
? ? graph_store.build_index([chunk])
? ? graph_store.save_index(config_data['storage_path']) # 保存到磁盘中
? ? info = graph_store.get_graph_db_info()
? ? print("=== 图谱存储信息 ===")
? ? pprint(info)
if?__name__ ==?"__main__":
? ? main()GraphRAG模块
import?json
from dotenv?import?load_dotenv
load_dotenv()
from config.core.retrieval.pruned_hipporag_config?import?PrunedHippoRAGRetrievalConfig
RETRIEVAL_CONFIG_JSON?=?"""
{
? ? "type": "pruned_hipporag_retrieval",
? ? "graph_config": { ? ? ? ? ? ? ? ? ? ? # 引用GraphStore子模块
? ? ? ? "type": "pruned_hipporag_igraph",
? ? ? ? "storage_path": "./data/demo_graph_index",
? ? ? ? "add_synonymy_edges": true,
? ? ? ? "embedding": {
? ? ? ? ? ? "type": "qwen_embedding",
? ? ? ? ? ? "loading_method": "huggingface",
? ? ? ? ? ? "model_name": "sentence-transformers/all-MiniLM-L6-v2",
? ? ? ? ? ? "device": "cpu",
? ? ? ? ? ? "cache_folder": "./models/all-MiniLM-L6-v2",
? ? ? ? ? ? "use_china_mirror": true
? ? ? ? }
? ? },
? ? "enable_llm_reranking": true,
? ? "expansion_hops": 2,
? ? "include_chunk_neighbors": true,
? ? "enable_pruning": true,
? ? "fact_retrieval_top_k": 10,
? ? "max_facts_after_reranking": 3,
? ? "damping_factor": 0.5,
? ? "passage_node_weight": 0.05
}
"""
def?main()?-> None:
? ? retrieval_config_data?= json.loads(RETRIEVAL_CONFIG_JSON)
? ? retrieval_config = PrunedHippoRAGRetrievalConfig.model_validate(retrieval_config_data)
? ? retriever = retrieval_config.build()
? ? query =?"OpenAI 的创始人是谁?"
? ? results = retriever.retrieve(query, top_k=3)
? ? print(f"=== 查询: {query} ===")
? ??for?idx,?chunk in?enumerate(results, start=1):
? ? ? ??print(f"结果 #{idx}")
? ? ? ??print(f"内容: {chunk.content}")
if?__name__?==?"__main__":
? ? main()注意事项
- 共享模块:为避免重复实例化造成资源浪费,共用子模块(如Embedding模型)可通过@shared_module注解实现共享;当配置相同时,多个模块将复用同一实例。
- 单例模块:数据库类资源(如Redis、PostgreSQL)应保证全局唯一,通过@singleton注解实现单例模式。
RAG-ARC 实战效果
RAG-ARC在检索效果与执行效率方面表现如何?以下基于三个公开评测集的数据,展现其在性能与成本上的双重优化成果。
1. 答案准确率更高
在HotpotQA、2Wiki、Musique三个复杂推理数据集中,RAG-ARC全面优于基线方法HippoRAG2。以需要多步推理的HotpotQA任务为例,准确率由83.2%提升至85.4%。
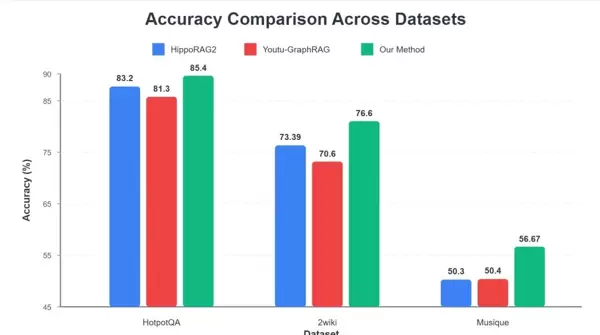
图4 ?RAG-ARC 在 HotpotQA 等复杂推理数据集的表现
2. 信息检索更全面
在衡量检索覆盖率的核心指标Recall@5上,RAG-ARC同样领先。在2Wiki数据集中,其Recall@5达到80.43%,相较基线方法的75.42%有明显提升,说明系统能更完整地召回相关信息。
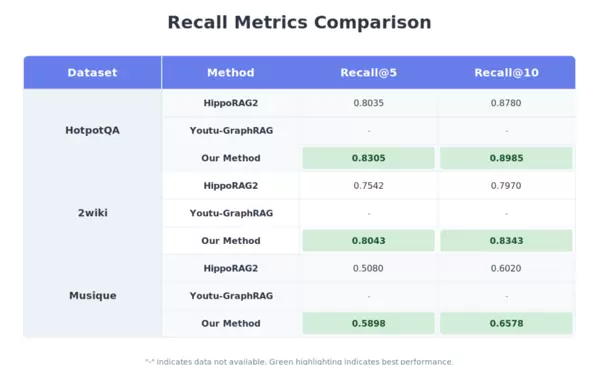
图5 ?RAG-ARC?在?2Wiki 等数据集检索表现最佳
3. 构图成本大幅降低
在知识图谱构建效率方面优势突出。在Musique数据集中,构图所需的Token消耗从基线方法约8700万降至约1000万,成本缩减至原先的十分之一左右,为知识库的高频迭代提供了坚实的技术支撑。
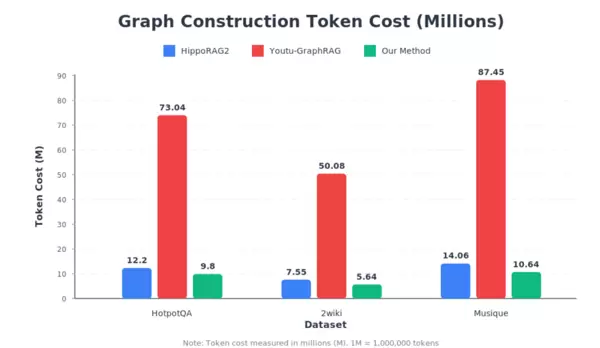
图6 ?RAG-ARC 所需 token 量最低
RAG-ARC作为新一代RAG框架中的全能型选手,融合了多路径检索、图结构提取、融合排序等多项创新技术,并实现了子图PPR计算与知识图谱的增量更新功能,在显著提升信息召回率的同时,有效降低了运营开销。
由粤港澳大湾区数字经济研究院(IDEA研究院)孵化的创新企业,专注于大模型数据合成领域。公司依托先进的技术实力与明确的商业路径,已成功完成多轮种子轮融资,累计融资金额达数千万元,展现出强劲的成长势头和发展前景。

【数创弧光 DataArc | 招贤纳士】
这是一家处于行业前沿的AI数据科技公司,正积极寻求人才加入,共同推动人工智能的发展。我们长期开放以下技术岗位,诚邀精英共筑AI未来:
- 语音算法工程师
- 大模型数据算法工程师
应聘方式:
请将简历发送至:hr@dataarctech.com
或登录Boss直聘平台,搜索“数创弧光DataArc”,了解更多职位信息,更多机会等待您的加入。

 京公网安备 11010802022788号
京公网安备 11010802022788号







