


 雷达卡
雷达卡



1. RAG系统的评估


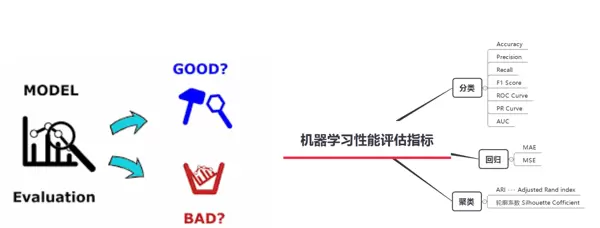
RAG系统主要由两个核心组件构成:
检索评估与
响应评估对检索模块的评估,通常称为“检索评估”,虽然在判断上存在一定的主观性,但依然可以借助信息检索领域的经典指标进行量化分析。常用的衡量标准包括准确率(Precision)、召回率(Recall)以及排名准确度等,这些指标能够有效反映系统在查找相关文档时的表现。
而生成模块的评估,也即“响应评估”,实际上是对RAG系统最终输出结果的整体质量进行评判,其复杂程度更高。该评估不仅需要确认生成的回答是否基于所提供的上下文内容(事实一致性),是否准确回应了用户的原始问题(查询相关性),还需进一步考察回答的语言流畅度、安全性以及是否符合社会主流价值观。
为了全面评估生成内容的质量,通常会结合使用定量指标(如BLEU、ROUGE)和定性指标(例如回答的相关性、语义连贯性、语境契合度、扎实性及忠实度)。鉴于这些维度难以完全自动化衡量,人类的主观评分仍是在评估流程中不可或缺的一环。
1.1 RAG评估专用数据集结构
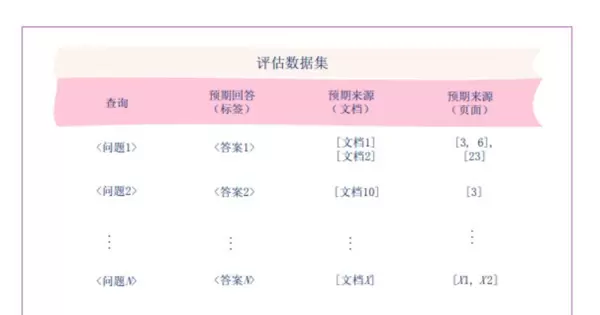
针对RAG(检索增强生成)系统设计的专用“评估数据集”是一种标准化的性能测试模板。它通过构建明确的“问题—答案—来源”三元组关系,用于验证系统在信息检索和答案生成两个环节的可靠性与准确性。
此类数据集通常包含四个关键字段,分别对应RAG评估的核心要素:
- 查询:用户提出的具体问题,例如“2025年AI芯片市场规模是多少”,作为RAG系统的输入指令;
- 预期回答(标签):与问题匹配的标准答案,例如“1200亿美元”,用于比对RAG生成内容的准确性;
- 预期来源(文档):答案应出自的知识库文档名称,如“Gartner 2025年AI报告”,用以检验检索模块是否定位到正确的资料;
- 预期来源(页面):答案所在文档中的具体页码,例如“第3页”,实现对信息位置精准性的双重验证。
在使用该数据集进行测试时,需将RAG系统的实际输出与数据集中预设的期望值进行对比:
- 检查系统检索出的文档及其页面是否与“预期来源”一致,以此评估检索准确性;
- 核对生成的回答是否与“预期回答”相符,从而判断回答准确性;
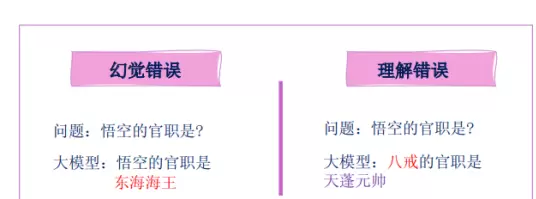
- 确认所生成的答案是否真正来源于指定的“预期来源”,防止出现无依据的推断或“幻觉”现象,确保回答的依据性。
举例说明图中“问题1”的测试场景:
当向RAG系统输入“问题1”后,若其成功检索到“文档1、文档2”的第3、6、23页,并且生成的回答与“答案1”一致,则表明该系统在此项测试中表现达标。
简而言之,这一数据集中的“问题”相当于考题,“预期回答”和“预期来源”则是标准答案,可用于系统化、可量化的RAG能力测评。
1.2 RAG评估三角模型
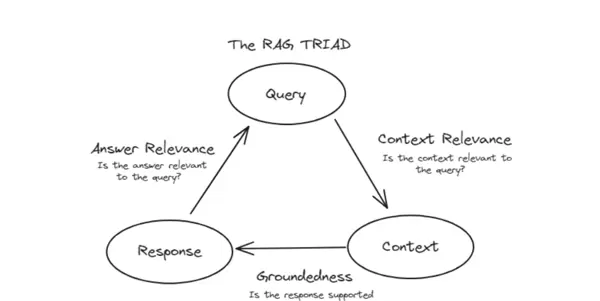
RAG(检索增强生成)系统的核心质量评估框架被称为“RAG TRIAD”——即评估三角模型。该模型从三个相互关联的维度出发,构成了衡量RAG输出质量的“体检表”。三者相辅相成,缺一不可。
三角的三个顶点分别代表RAG处理流程中的三个关键阶段:
- Query:用户的原始提问,例如“2025年AI芯片市场规模是多少”;
- Context:系统从外部知识库中检索获得的相关信息,例如“Gartner 2025年AI芯片报告”中的相关内容;
- Response:大模型结合Query与Context生成的最终答复。
每个维度都对应一个关键判断问题,共同决定整体输出质量:
(1)Context Relevance(上下文相关性)
核心问题:Is the context relevant to the query?(检索到的上下文是否与用户问题相关?)
作用:评估RAG的“检索能力”,即能否找到与问题高度匹配的信息。
反例:用户询问“2025年AI芯片市场”,系统却返回“2023年手机芯片报告”,则此维度未达标。
(2)Groundedness(回答的依据性)
核心问题:Is the response supported by the context?(生成的回答是否有上下文支撑?)
作用:检验RAG的“诚实性”,避免模型编造信息(即产生“幻觉”)。
反例:上下文中明确指出“2025年AI芯片市场规模为1200亿美元”,但回答声称“1500亿美元”,则此项不通过。
(3)Answer Relevance(回答的相关性)
核心问题:Is the answer relevant to the query?(生成的回答是否切题?)
作用:衡量RAG的“回答能力”,即是否真正解决了用户的问题。
反例:用户问的是市场规模,回答却详述“AI芯片的技术原理”,属于答非所问,维度不达标。
评估三角的核心逻辑在于:三个维度必须同时满足
高质量的RAG输出要求:
- 首先确保Context与Query相关,即检索到了有用且匹配的信息;
- 其次保证Response基于Context生成,杜绝虚构内容;
- 最后确认Response与Query直接相关,真正做到精准作答。
在RAG系统中,若任一关键维度未达到标准,其输出结果即被视为“无效”或“低质量”。例如,即便检索模块成功获取了相关的上下文信息(Context),但生成的回答偏离了用户原始问题,该结果仍属于失败的案例。因此,RAG的质量保障依赖于三个核心要素的协同作用:精准的检索、准确的内容匹配以及可靠的生成回答。这三者共同构成了RAG系统的“质量铁三角”,是确保整体性能稳定的基础。
2. 检索器性能评估
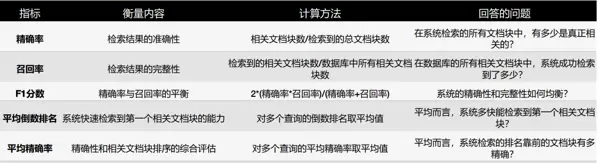
2.1 精确率(Precision)
精确率用于衡量被检索出的文本块中有多少与当前查询真正相关,计算方式为:检索到的相关文本块数量除以总检索出的文本块数量。该指标试图回答:“在所有返回的结果中,有多少是用户真正需要的?”
高精确率意味着系统能够有效过滤无关内容,提升信息呈现的准确性。这一点在医疗诊断、法律条文等对信息准确性要求极高的领域尤为重要,有助于避免误导性信息的传播。

2.2 召回率(Recall)
召回率反映的是系统对全部相关文本块的覆盖能力,即检索出的相关项占数据库中所有相关项的比例。它关注的问题是:“在所有应该被找到的相关内容中,系统实际找到了多少?”
较高的召回率可显著降低关键信息遗漏的风险。如果召回不足,模型可能因缺乏必要背景而产生不完整甚至错误的回答。例如,在法律案件分析中,漏检重要判例将直接影响结论的完整性与可信度。

2.3 F1 分数
由于精确率和召回率往往存在此消彼长的关系——提高一个通常会导致另一个下降——因此需要一种综合指标来平衡二者。F1 分数作为精确率与召回率的调和平均值,正是用来量化这种权衡关系的关键工具,帮助识别适用于特定场景的最佳检索配置。

2.4 平均倒数排名(MRR)
平均倒数排名(Mean Reciprocal Rank, MRR)聚焦于第一个相关文档的排序位置,用以评估系统快速定位有效答案的能力。MRR值越高,说明系统越能在靠前位置返回有用结果,从而提升用户体验。
公式中,Q代表总的查询数量,rankq表示第q次查询时首个相关文本块的排名。该指标仅取第一个相关项排名的倒数进行计算,因此更强调“首条命中”的效率:排名越靠前,倒数值越大,MRR得分也越高。
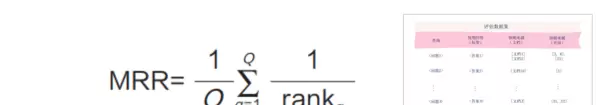
2.5 平均精确率(MAP)
平均精确率(Mean Average Precision, MAP)是一种跨多个查询的整体评估方法,不仅考察结果的相关性,还重视相关文档在排序中的位置分布。通过对每个查询在不同截断点上的精确率进行加权平均,MAP能够更全面地反映排序质量。
其中,Q为总查询数,而Average Precision(AP)则是针对单个查询计算得出,充分考虑了相关文档出现的先后顺序。MAP广泛应用于搜索引擎优化及电商平台的商品推荐系统等对排序敏感的场景。

2.6 P@K(Precision at K)
P@K 衡量的是前K个返回结果中的精确率,即在这K项中包含多少真正相关的内容。其分子为前K个结果中相关文档的数量,分母为固定值K。该指标特别适用于用户只关注前几条结果的应用场景。
例如,在新闻检索系统中,P@K可用于确保用户搜索时看到的前几条资讯高度契合主题,从而提升阅读效率与满意度。

以下是对上述各项检索评估指标的简要总结及其主要特点概述:
3. 生成器(响应)质量评估
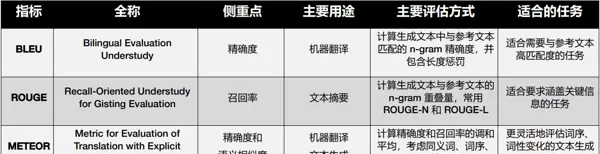
3.1 BLEU:基于n-gram匹配的评估指标
BLEU(Bilingual Evaluation Understudy)通过计算生成回答与参考答案之间n-gram的重叠程度来评估生成质量,侧重于精确率的表现。n-gram指连续的n个词(token)组成的序列,常见的有1-gram至4-gram。
公式中,BP代表长度惩罚(Brevity Penalty),用于防止过短回答获得虚高评分:当生成文本短于参考文本时,BP小于1;否则等于1。Pn表示n-gram精确率,wn为各阶n-gram的权重,通常设为相等。
举例来说,若参考答案为“the cat is on mat”,而生成结果为“the cat on mat”,则在BLEU-1计算中,匹配的1-gram包括“the”、“cat”、“on”、“mat”共4个词,生成句中共4个词,因此1-gram精确率为1。
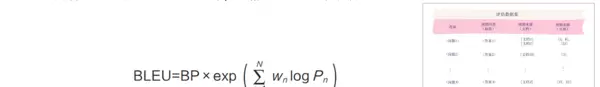
3.2 ROUGE:另一种基于n-gram匹配的评估方法
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一类面向召回率的自动摘要评估指标,常用于衡量生成文本与参考文本之间的相似度。与BLEU不同,ROUGE更关注“有多少参考内容被成功生成出来”,即强调召回能力而非精确率。
常见变体包括ROUGE-N(基于n-gram共现)、ROUGE-L(基于最长公共子序列)等,适用于不同的生成任务场景,如摘要生成、问答系统输出评估等。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation,通常译为“面向召回的摘要评估替代工具”)是一种通过计算生成回答与参考答案之间n-gram重叠程度来评估文本质量的方法。该指标综合考虑了精确率和召回率,提供了一种相对均衡的评价机制。

以先前示例为例,假设参考答案为“the cat is on mat”,而模型生成的回答为“the cat onmat”。针对ROUGE-1(即基于1-gram的匹配),可识别出“the”、“cat”、“on”和“mat”共4个匹配项。由于参考答案中共有5个1-gram单元,因此ROUGE-1得分为0.8。对于ROUGE-2(即2-gram匹配),匹配到的片段为“the cat”和“on mat”两项,而参考答案中包含4个2-gram组合,故ROUGE-2得分则为0.5。
METEOR(Metric for Evaluation of Translation with Explicit Ordering,常译作“具有显式排序的翻译评估指标”)在评估生成内容与参考文本之间的相似度时,引入了更深层次的语言特征分析。它不仅关注词汇层面的匹配,还结合同义词匹配、词干归并以及词序一致性等因素,从而实现比BLEU和ROUGE更优的语义捕捉能力。
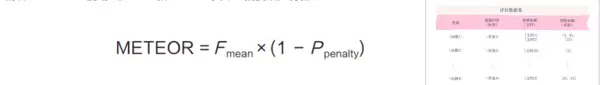
METEOR的计算包括两个主要部分:一是精确率与召回率的调和平均值(F mean),用于衡量整体匹配水平;二是惩罚项(P penalty),用于对词序错乱或结构不一致等情况进行扣分处理。在上述例子中,生成回答包含4个词,其中全部4个词均能匹配到参考答案中的对应项,因此精确率为1。参考答案共5个词,其中有4个被成功匹配,召回率为0.8。由此计算得到F mean = (2 × 1 × 0.8) / (1 + 0.8) = 1.6 / 1.8 ≈ 0.89。由于生成结果遗漏了“is”这一连接词,导致语法连贯性下降,METEOR会施加一个惩罚项,在本例中假定P penalty为0.1,则最终METEOR得分约为0.801。
BLEU、ROUGE与METEOR三种基于n-gram匹配的自动评估指标各有侧重,适用于不同场景下的文本生成质量分析。它们在实际应用中的表现差异可通过对比图表直观呈现。
3.4 基于语义相似性的评估方法

3.5 忠实度与扎实性相关指标
为提升大模型输出的可靠性,以下几种指标专注于评估其内容的真实性与依据来源的准确性:
文档精确率与页面精确率:这类指标用于判断大模型所引用的文档及其具体页码是否准确无误。要求模型在回应中明确标注信息出处,有助于降低虚构内容的出现概率。
幻觉检测与一致性检查:此类评估旨在识别模型是否存在“幻觉”现象,即生成的内容虽看似合理但无法从提供的上下文中推导得出。采用二进制评分方式(0或1),即使回答本身正确,若缺乏上下文支持,仍判定为错误。
大模型评分量表:借助更强的大型语言模型作为评判者,对生成回答进行打分,例如使用0至5分的评分体系。评分标准可根据具体业务需求灵活设定,适应多样化的应用场景。
人工评估:由具备专业知识的领域专家对模型输出进行人工审核,验证其事实准确性及是否合理引用了检索所得的信息源。
4. RAG系统评估框架与工具
4.1 RAGAS
4.2 Trulens

4.3 DeepEval

4.4 Phoenix提供的可视化界面

 京公网安备 11010802022788号
京公网安备 11010802022788号







