


 雷达卡
雷达卡



Oracle Database 是当前企业级系统中应用最为广泛、技术最成熟且稳定性极高的关系型数据库之一。其发展历程悠久,相关背景在此不再详述。
关系型数据库概述
关系型数据库是基于关系模型构建的数据库系统,利用集合代数等数学理论对数据进行组织与处理。现实世界中的各类实体及其相互之间的关联,均可通过关系模型加以表达和实现。
在该模型中,数据以二维表格形式呈现。每张表由若干行(记录)和列(字段)构成,每一列具有固定的属性类型。这种结构简洁明了,具备高度的数据独立性,因而成为目前主流的数据库架构形式。
从数学角度看,一个“关系”可视为由行与列交叉形成的二维表:
- 表中的每一行称为元组,代表实体集中某个具体的实例;
- 每一列称为属性,并拥有唯一的属性名;
- 同一列的取值范围称为域,不同列可以共享相同的域;
- 任意两行不允许完全相同;
- 能够唯一标识每一行的单个属性或多个属性组合被称为主键或复合主键。
尽管关系模型与传统二维表格相似,但它遵循更严格的规范,具体包括:
- 所有属性值必须具备原子性,不可再分;
- 不允许存在重复的元组(即无重复行);
- 理论上行之间没有顺序之分,但在实际操作中可临时排序使用。
关键码的概念
在关系模型中,关键码是核心概念之一,用于唯一识别表中的记录。它可以是一个或多个属性的组合。主要类型如下:
- 超键:能唯一标识元组的属性或属性集;
- 候选键:最小化的超键,即不含多余属性的超键;当存在多个候选键时,从中选定一个作为主键;
- 主键:被选中的候选键,用于确保“任意两行不相同”的约束条件;
- 外键:若关系R包含另一个关系A的主键所对应的属性组T,则称T为R的外键,此时A为参照关系,R为依赖关系。
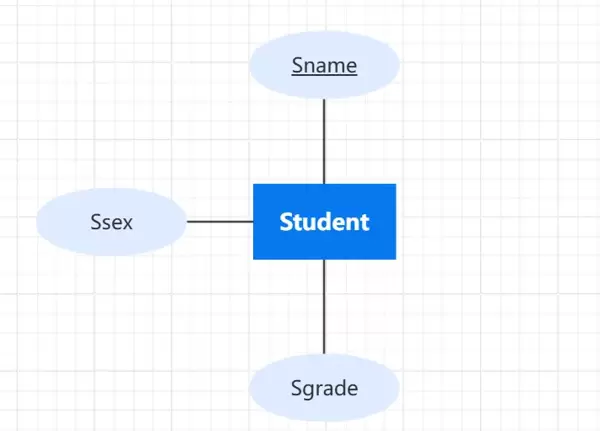
E-R 模型设计
在构建关系型数据库前,通常需要先建立逻辑模型。E-R模型(实体-联系模型)是一种常用的建模工具,它将现实世界的实体及其联系转化为图形化的逻辑结构。该模型由三大要素组成:实体、属性和联系。
1. 实体与属性
实体指客观存在且可相互区分的对象,每个实体通过一组属性来描述。具有相同属性特征的实体集合称为实体集,而单个实体则是该集合的一个成员。
在E-R图中:
- 实体用矩形表示,内部标注实体名称;
- 命名习惯上采用首字母大写的英文名词,如 Customer、Order 等;
- 同样规则适用于联系名和属性名。
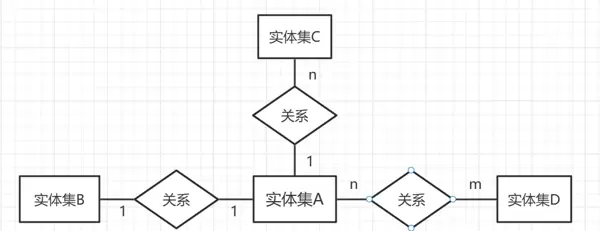
2. 联系类型
实体之间往往存在各种关联,这些联系需在E-R模型中明确体现。联系使用菱形符号表示,内含联系名称,并通过连线连接相关实体,在线旁注明联系的类型。
常见的二元联系类型有三种:
- 一对一 (1:1):对于实体集A中的每一个实体,实体集B中至多有一个实体与之对应,反之亦然;
- 一对多 (1:n):实体集A中的一个实体可对应实体集C中的多个实体,但C中的每个实体最多只对应A中的一个实体;
- 多对多 (m:n):实体集A中的每个实体可对应实体集D中的多个实体,反之亦然。
数据库设计范式
关系型数据库由一组相互关联的关系构成,每个关系包含两个方面:关系模式(结构定义)和关系值(具体内容)。关系模式规定了表的结构,而关系值反映某一时刻的实际数据状态。每个元组都符合模式定义,并按属性分配具体数值。
为了减少数据冗余并保证完整性,数据库设计需遵循规范化原则。规范化过程旨在构造出既能保持数据一致又能最小化重复存储的数据结构,其依据是关系模型的范式规则。
范式的引入有助于避免数据异常、更新错误及信息丢失等问题。常见的范式包括:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、BCNF、第四范式(4NF)直至第六范式(6NF)。一般情况下,满足前三范式即可满足大多数业务需求。
1. 第一范式(1NF)
作为其他范式的基础,第一范式是最基本的要求,任何关系数据库都必须满足以下条件:
- 每个属性仅包含单一值,不得出现多值属性;
- 每行必须拥有相同数量的属性值;
- 表中不能存在完全相同的行。
若数据库未达到第一范式,则不能被视为真正意义上的关系型数据库。
第一范式(1NF)是数据库规范化的基本要求。若数据表中的每一列都仅包含不可再分的基本数据项,即同一列中不允许多个值存在,则该表满足第一范式。这体现了数据的原子性特征——每个字段的值都是单一且最小的数据单元。
在符合第一范式的表中,每行记录代表一个独立实体,且每一列只能存储该实体的一个属性值。这意味着所有字段都必须是单一值,不能包含复合或重复的组。
例如,以下学生信息表不符合第一范式:
| 学号 | 姓名 | 性别 | 年龄 | 班级 |
| 9527 | 小明 | 男 | 20 | 计算机系三班 |
其中,“班级”列包含了“系别”和“班级”两个属性信息,违反了原子性原则。因此需要将其拆分为两个独立的列。
修正后的表格如下所示,此时已满足第一范式的要求:
| 学号 | 姓名 | 性别 | 年龄 | 系别 | 班级 |
| 9527 | 小明 | 男 | 20 | 计算机系 | 三班 |
第二范式(2NF)建立在第一范式的基础之上。也就是说,只有当数据表首先满足第一范式时,才可能进一步满足第二范式。
第二范式的核心要求是:表中的每一个非主键属性必须完全依赖于整个主关键字,而非其任何一部分。尤其在复合主键的情况下,不允许出现某个非主键属性仅依赖于主键的一部分的情况。
为了实现这一点,通常需要为数据表设置一个主键(主关键字),用以唯一标识每一行记录。那些仅部分依赖于主键的属性应被提取出来,形成新的关系表,从而消除部分函数依赖。
以员工工资表为例:
(员工编码、岗位) --> (决定) (姓名、年龄、学历、基本工资、绩效工资、奖金)上述关系可进一步分解为以下两个独立的关系结构:
(员工编码) --> (决定) (姓名、年龄、学历)(岗位) --> (决定) (基本工资)第三范式(3NF)则是在满足第二范式的基础上进一步规范化的结果。它要求表中不存在非主键列对候选键的传递函数依赖。
换句话说,所有非主键字段必须直接依赖于主键,而不能通过其他非主键字段间接依赖于主键。此外,一张表不应包含已经在其他表中存在的非主键信息,以避免冗余。
举例如下:
(员工编码) --> (决定) (员工姓名、年龄、部门编码、部门经理)尽管上述关系满足第二范式,但并不符合第三范式。原因在于表内隐含了如下的依赖关系:
(员工编码) --> (决定) (部门) --> (决定) (部门经理)
 京公网安备 11010802022788号
京公网安备 11010802022788号







