


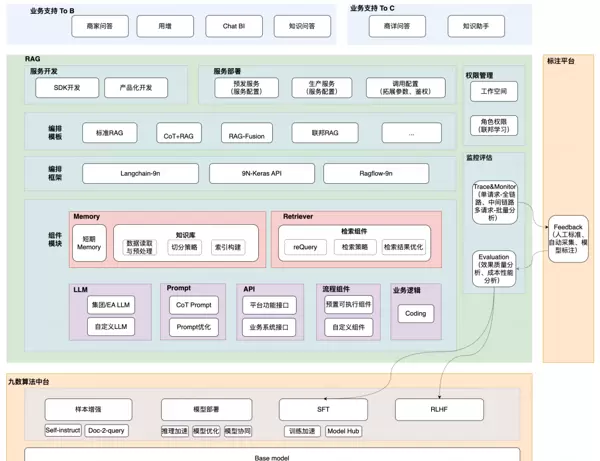
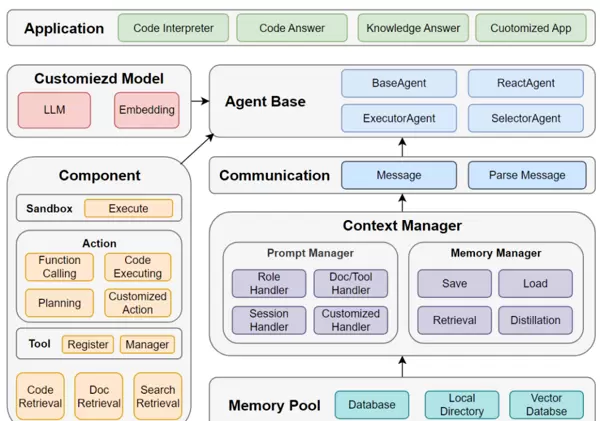
 雷达卡
雷达卡



2025年,AI记忆架构迎来关键转折点,Agent记忆与RAG(检索增强生成)逐渐显现出上下文工程中的两种根本路径。本文深入剖析二者在动态演化与静态检索、复杂推理与知识问答等核心维度的本质差异,并结合性能基准与实际工程实践,帮助开发者更精准地选择适配的技术方案。
为何越来越多的复杂AI系统正从RAG转向Agent记忆?这背后不仅是技术演进的结果,更是对“智能”本质理解的深化。
动态演化 vs 静态检索:认知范式的根本对立
当用户提问“我上周提到的项目进度如何?”时,RAG与Agent记忆会表现出截然不同的响应方式。RAG如同图书馆管理员,需翻阅预先归档的资料进行匹配;而Agent记忆则更像一位私人秘书——它不仅记得对话内容,还能关联当时的情境、情绪变化以及后续待办事项。
这种差异源于底层认知模型的不同。RAG依赖的是预构建的语义索引体系,所有文档必须提前分块并转化为向量表示,检索过程本质上是基于相似度的机械匹配。例如某医疗AI案例中,患者描述“胸口像被大象压着”,因训练数据仅包含标准术语“胸痛”,系统竟返回骨科论文,暴露出其对非结构化表达的理解局限。
相比之下,Agent记忆通过运行时持续更新机制,实现记忆结构的动态调整。短期记忆保留最近几轮对话的关键信息,长期记忆则利用“记忆压缩”技术将重要交互转化为可检索的语义向量。Langbase的实践表明,当用户反复提出同类问题时,系统不仅能优化内部记忆组织,甚至主动触发知识补全流程。
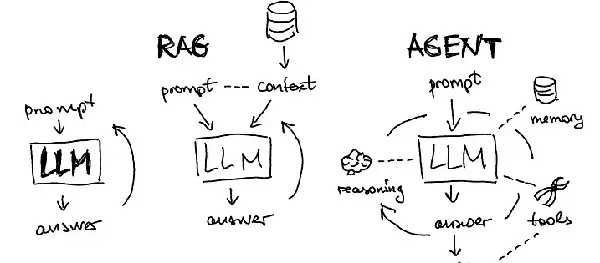
主动学习:从存储到重构的认知跃迁
“Agent记忆的核心竞争力在于:它不是简单存储,而是理解后重构。”
这一能力的关键体现在其主动学习机制上。当用户纠正“不是柯基是柴犬”时,系统不仅修正当前记录,还会实时更新记忆图谱,并自动将该信息链接至“用户偏好”节点,确保后续交互中避免重复错误。这种跨会话的记忆连贯性,是传统RAG难以企及的。
此外,RAG的知识库更新需要重新嵌入全部文档、重建索引,过程耗时且滞后;而Agent记忆支持ADD/UPDATE/DELETE操作,实现毫秒级增量更新。数据表明,在知识频繁变更的场景下,Agent记忆的更新延迟比RAG低80%。
因此,若所需AI是一个能随时间积累经验、不断成长的“同事”,而非仅用于一次性查询的“资料机器”,Agent记忆显然更具优势。
三层记忆架构:模拟人类认知的时间尺度分离
Agent记忆区别于传统检索的核心,在于其分层记忆架构,该设计模拟了人类大脑的记忆编码-巩固-检索流程:
- 短期工作内存:采用KV缓存与注意力汇聚机制(如StreamingLLM),处理即时对话内容,响应迅速但容量有限;
- 中期记忆缓冲区:通过语义聚类与重要性评分筛选关键事件,例如Reflexion框架将失败经历提炼为反思文本,用于未来决策优化;
- 长期持久化记忆:整合多模态编码器与图神经网络,构建结构化知识图谱,支持跨模态、跨会话的信息关联。
Memory-R1的强化学习实验显示,此类分层设计使记忆管理F1指标提升68.9%,显著优于传统启发式策略。在Letta系统中,核心记忆(系统提示)、对话记忆(时间序列日志)和归档记忆(向量数据库)的三重划分,进一步验证了该架构在动态演化能力上的优越性。
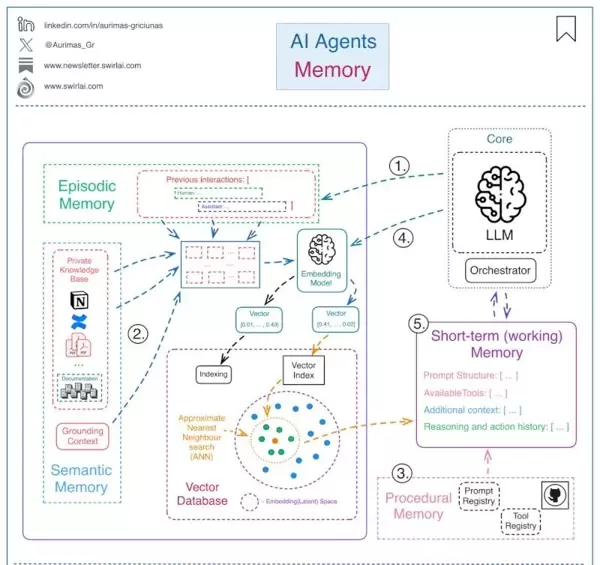
分层即时间尺度的解耦
该架构的本质在于对不同时间尺度任务的分离处理:短期应对即时交互,中期完成信息筛选,长期实现知识沉淀,最终形成一个具备自我修正能力的智能体。没有主动更新机制的记忆系统,本质上只是静态数据库的翻版。
架构对比:线性流程 vs 双代理闭环
RAG遵循典型的线性模块化流程:文档分块 → 向量化编码 → 检索 → 内容生成。这一流程看似清晰,实则存在根本缺陷——检索结果完全依赖预计算的向量相似度,无法根据上下文动态调整。实测发现,在知识快速迭代的场景中,RAG的检索准确率因信息过期而急剧下降。
而Agent记忆常采用双代理架构(如GAM):
- 记忆代理:运用元学习机制(如SELF框架)自主优化记忆存储与提取策略;
- 执行代理:通过工具调用扩展行为边界,实现对外部环境的感知与干预。
Memory-R1实验表明,仅使用152个问答对训练,双代理架构在LOCOMO基准上的BLEU-1得分就超越Mem0基线48%。更重要的是,在多跳推理任务中,RAG的F1得分仅为15.04,而Memory-R1-GRPO达到35.65,差距显著。
架构本质:查得到 vs 想得对
RAG解决的是“能否查到相关信息”的问题,属于被动响应型系统;而Agent记忆致力于“是否能做出正确推断”,构建了“感知-学习-决策”的主动闭环。前者是搜索引擎的延伸,后者才是真正意义上的智能体。
性能边界:复杂推理场景下的代际差距
在长周期、多轮次推理任务中,Agent记忆展现出对RAG的压倒性优势。RULER基准测试结果显示,在涉及10轮以上、需整合分散信息的任务中,Agent记忆系统保持90%以上的准确率,而传统RAG方案则跌至30%以下。
造成这一差距的根本原因在于上下文维护机制的不同。Agent记忆通过动态记忆更新持续追踪任务状态,而RAG每次检索都面临“信息衰减”风险——超过3轮对话后,关键信息丢失率高达60%以上。

综上所述,RAG适用于事实明确、查询独立的知识问答场景;而Agent记忆更适合需要持续交互、上下文依赖强、逻辑链条复杂的系统级应用。技术选型不应仅看当前功能需求,更应考量系统的成长潜力与长期适应能力。
实验数据显示,在任务需要关联超过5个分散信息点时,RAG的检索召回率从初始阶段的85%急剧下降至第三轮的22%,而Agent记忆凭借记忆压缩技术,仍能维持78%以上的有效记忆率。
更关键的是,Agent记忆具备推理链自维护能力。在数学证明、代码调试等依赖多步推导的场景中,系统可自动构建并持续维护推理图谱;相比之下,RAG需开发者手动设计提示链结构,且每增加一个推理步骤,错误率便呈指数级上升。
长周期推理并非单纯比拼记忆长度,而是对记忆质量的深度考验——Agent记忆胜在“懂得遗忘”,RAG则败于“无法记住真正重要的内容”。
RAG适用场景:静态知识库查询
Agent记忆适用场景:多轮对话与复杂决策
两者之间存在明显的场景互补性,而非简单的替代关系。在知识目标明确、更新周期较长(如超过24小时)的静态知识场景中——例如产品手册或法规条文查询——RAG展现出显著优势。其F1值达到0.92,响应速度低于500ms,远超Agent记忆的表现。这源于其“搜索引擎思维”的本质:通过向量相似度快速定位已有知识片段。
然而,在面对动态决策需求时,Agent记忆展现出压倒性优势:
- 多轮对话:在客服交互中,Agent记忆能自然关联历史对话内容(如“上次提到的订单问题”),无需额外模块支持;而RAG必须引入独立的对话状态跟踪机制才能实现类似功能。
- 复杂决策:在医疗诊断等需整合患者病史、检验报告及最新研究的场景中,Agent记忆可通过记忆优先级机制动态调整信息权重;RAG则常陷入“信息过载”困境,返回大量冗余结果。
- 主动学习:Agent记忆能够识别自身知识盲区,并主动发起信息获取请求(如“需要补充XX检查报告”);RAG完全依赖预设检索策略,缺乏主动性。
由此可见,RAG是高效的“知识快照”工具,适用于解决“知道什么”的问题;而Agent记忆则是真正的“认知系统”,专注于解决“如何思考”的挑战。选择依据清晰明了:若需模拟思考过程,则使用Agent记忆;若仅需提取已有信息,则RAG更为高效。
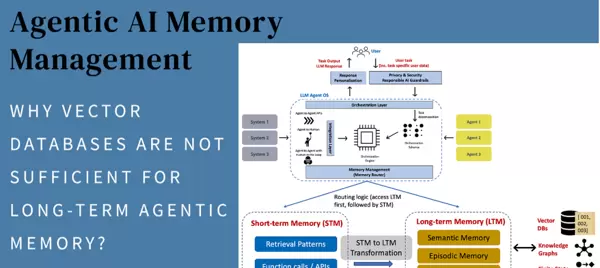
工程实践:混合架构与避坑指南
进入2025年,AI记忆架构正从单一技术路线转向协同融合模式。Agent记忆与RAG不再是对立选项,而是智能系统的两个核心组件——关键在于如何实现职责分明、高效协作。
记忆膨胀与检索漂移:各自的核心挑战
Agent记忆面临“记忆膨胀”问题。随着对话轮次累积,未加筛选的记忆体迅速扩张,导致检索效率骤降。实验证明,连续进行50轮对话后,平均记忆占用高达12k tokens,其中30%为低价值冗余信息。更严重的是,过时记忆可能干扰当前决策,造成“记忆污染”。MemGPT实验表明,缺乏过滤机制的系统运行30天后,检索准确率下降47%。

RAG则陷入“检索漂移”困境。当用户查询涉及多轮对话中的隐含上下文时,向量检索往往返回大量表面相关但实际无关的内容片段。LOCOMO基准测试显示,RAG平均返回60个候选记忆,但仅有不到5个真正有用。在动态知识环境中,该问题尤为突出——某金融客服系统中,因检索算法无法区分新旧政策文档,回答时效性问题的准确率下降了42%。
核心矛盾浮现:Agent记忆因“试图记住一切”而导致性能衰减,RAG则因“无法理解用户真实意图”而偏离目标。二者均暴露出单一技术路径在复杂应用中的局限性。
分层协同方案:AI大脑(Agent记忆) + 自动化肌肉(RAG)
行业领先实践采用功能解耦架构:将Agent记忆作为“AI大脑”负责动态认知处理,RAG作为“自动化肌肉”执行静态知识检索。这种分层设计在DMR基准测试中实现了32%的长期一致性提升,同时降低40%的存储成本。
具体实施依托于三级过滤机制:
- 入口过滤:Agent记忆仅保留关键事件(如用户偏好变更、重大决策),利用轻量级摘要模型将长对话压缩为3-5个核心事实点,减少70%的token消耗。
- 检索增强:基于Agent记忆中的用户画像实时生成检索约束条件。例如,当系统记录用户“关注科技股”,RAG会自动添加行业过滤规则,使准确率从68%提升至89%。
- 双向验证:针对复杂问题,Agent记忆首先根据历史对话生成初步推理,随后由RAG检索外部知识进行交叉验证。某医疗系统应用此方案后,诊断建议的合规性提升了35%。
工程价值体现在精准分工:让Agent记忆专注处理持续演化的认知任务(如用户画像构建、决策逻辑维护),RAG则承担静态知识查询(如产品手册、法规条文)。智能工单系统的实测数据表明,混合架构相较纯RAG方案,处理效率提升3倍,且记忆体规模稳定控制在5k tokens以内。
没有完美的单一解决方案,只有高明的组合策略——让Agent记忆主导决策,RAG负责执行,才是AI记忆系统的终极形态。

 京公网安备 11010802022788号
京公网安备 11010802022788号







