


 雷达卡
雷达卡



2025年12月1日,DeepSeek 发布了其备受瞩目的正式版本——DeepSeek-V3.2 及其高性能变体 DeepSeek-V3.2-Speciale。这一发布不仅标志着技术上的重大跃迁,更象征着中国 AI 在“后训练”时代的全球话语权提升。从拥有685B参数的稀疏架构,到在数学推理上媲美IMO金牌选手的Speciale版本,这场关于AI推理范式的变革正在重塑行业格局。
本文将深入解析 DeepSeek 如何通过创新性的稀疏注意力机制突破长文本处理瓶颈,并揭示 Speciale 版本如何在代码与数学领域达到甚至超越 GPT-5 和 Gemini 3.0 Pro 的表现水平。

进入“后训练”时代:开源模型的新纪元
过去一年,大模型领域陷入了激烈的算力军备竞赛。当 OpenAI 推出 o1 系列并展示“系统2”思维链(Chain of Thought, CoT)的强大能力时,整个行业开始质疑:在闭源巨头的压制下,开源模型是否还有突围的可能?
随着 Scaling Laws(缩放定律)边际效益递减,单纯增加参数已无法带来等比性能提升。OpenAI 与 Google 转而聚焦于 Inference-Time Compute——即让模型“多思考”,以时间换取更高的推理质量。而此刻,DeepSeek 给出了来自中国的回应。
DeepSeek-V3.2 系列的全面上线,宣告了开源模型正式迈入“后训练”(Post-Training)阶段。它不再只是一个知识存储库,而是进化为具备深度逻辑推理能力的智能体。无论是通用版 V3.2 还是高算力特化版 Speciale,这套组合方案不仅在技术上实现了长上下文理解与复杂推理的平衡,更在战略层面首次使开源体系在关键能力上与西方主流闭源模型并驾齐驱。
这不仅是 DeepSeek 的胜利,更是整个开放权重(Open-Weights)生态的重要里程碑。
架构革新:效率与性能的极致融合
DeepSeek 能够同时成为“性价比之王”和“性能强者”,根本原因在于其底层架构的大胆重构。不同于 Llama 系列坚持使用的稠密模型(Dense Model)路线,DeepSeek 深耕混合专家系统(MoE),走出了一条高效且可扩展的技术路径。
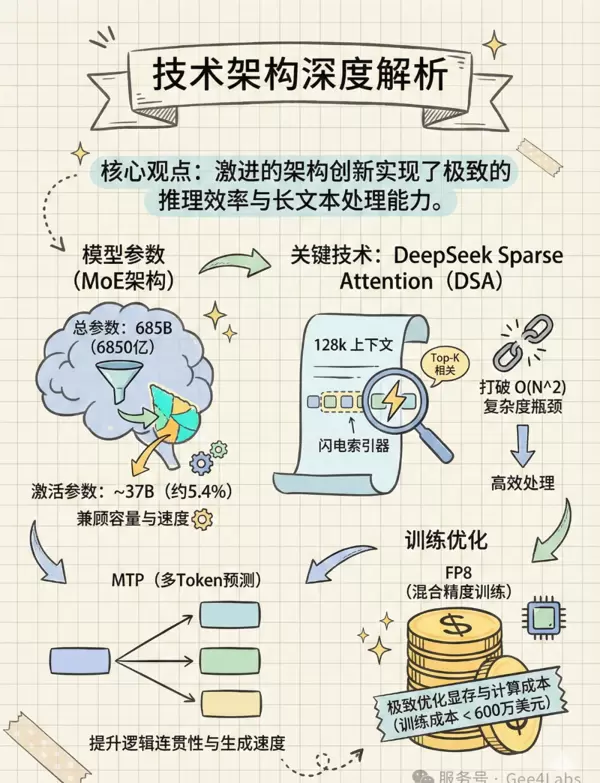
2.1 685B 参数背后的“轻盈舞步”
DeepSeek-V3.2 的总参数量高达 6850 亿(685B),在当前开源模型中属于顶级规模。通常而言,如此庞大的模型意味着高昂的推理成本与缓慢的响应速度。但 DeepSeek 借助 MoE 架构打破了这一固有认知。
- 总参数量:685B(含主模型及多 Token 预测模块)
- 激活参数量:约 37B
这意味着,尽管模型背后有近七千亿参数作为支撑,但在每次推理过程中,仅有约 370 亿参数被实际激活,占比不足 5.4%。这种设计使得 DeepSeek-V3.2 兼具 GPT-4 级别的知识广度,却仅需接近 Llama-3-70B 的计算资源即可运行。
此外,在训练工程方面,DeepSeek 展现了极强的技术掌控力。采用 FP8(F8_E4M3)混合精度训练策略,充分释放 NVIDIA H800 集群的算力潜能。据公开信息显示,基础模型训练耗时不到 300 万 GPU 小时,总成本控制在 600 万美元以内。如此高效的资源利用,正是其敢于推行低价策略、冲击市场的核心底气。
2.2 核心突破:DeepSeek Sparse Attention (DSA)
在 V3.2 版本中,最引人注目的技术升级当属 DeepSeek Sparse Attention(DSA)机制的引入。
长期以来,Transformer 架构面临一个致命瓶颈:随着输入长度增长,注意力计算复杂度呈二次方 $O(N^2)$ 增长。例如,处理 100k tokens 所需的算力并非处理 10k 的十倍,而是百倍以上。
DSA 的解决方案如下:
- 动态路由:在执行完整注意力计算前,模型先进行快速扫描,识别出与当前查询最相关的 Key-Value 对
- Top-K 计算:仅对筛选出的关键 Top-K Tokens 进行高精度运算,其余部分则被有效忽略
- 结果优化:将原本二次方的计算复杂度压缩至接近线性级别
得益于此,DeepSeek-V3.2 实现了稳定支持 128k Token 上下文窗口 的能力。无论是分析数百页的企业财报,还是检索整套代码工程,V3.2 都能在保持响应速度的同时精准捕捉关键信息,彻底摆脱长文本场景下的性能桎梏。
2.3 多 Token 预测(MTP)带来的双重增益
除了 DSA 外,DeepSeek 还进一步强化了多 Token 预测(Multi-Token Prediction, MTP)技术的应用。该机制允许模型在单次前向传播中预测多个后续 token,而非传统的一次一词。
MTP 带来了两方面的显著优势:
- 提升生成效率,减少整体延迟,尤其在长输出任务中效果明显
- 增强语义连贯性,避免逐词生成导致的局部偏差累积
结合 DSA 与 MTP,DeepSeek 在推理速度与生成质量之间找到了新的平衡点,为高吞吐、低延迟的实际应用场景提供了坚实基础。
DeepSeek-V3.2 继承并深化了 V3 版本中引入的多令牌预测(Multi-Token Prediction, MTP)机制。与传统模型仅预测下一个字不同,该技术使模型在训练阶段就能同时推断未来多个连续的文本片段。
从训练角度看,这一机制促使模型掌握更长远的语言结构和逻辑规划能力;而在推理过程中,MTP 支持“投机式解码”(Speculative Decoding),允许模型先快速生成一串候选 Token,并通过后续验证进行修正。这种机制显著提升了每秒生成 Token 的数量(TPS),让用户在实际使用中感受到明显的速度提升。
开启 System 2 推理的新篇章:DeepSeek-V3.2-Speciale
如果说 DeepSeek-V3.2 是一位全能型选手,那么其变体——DeepSeek-V3.2-Speciale,则更像是专为攻克人类顶级难题而打造的特种兵种。
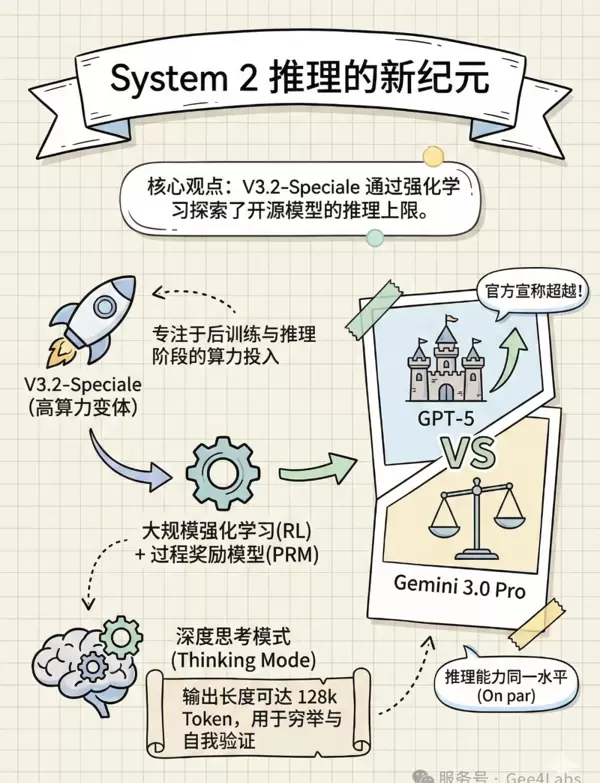
3.1 什么是 Speciale?
根据官方定义,Speciale 属于“高算力变体”(High-Compute Variant)。这里的“高算力”并非指参数规模更大,而是强调在推理阶段投入更多计算资源以实现深度思考。
Speciale 是在后训练阶段,通过大规模强化学习(Reinforcement Learning)精心打磨而成。它不仅学习模仿人类语言,还通过数亿次自我博弈与过程奖励模型(PRM)训练,掌握了类人“思维”的能力,能够自主构建复杂的推理链条。
3.2 深度思考模式(Thinking Mode)
DeepSeek-V3.2 系列首次引入了显式的 <think> 标签,用于控制是否启用深层推理:
- DeepSeek-V3.2 (Chat):默认关闭思考模式,响应迅速,适用于日常对话和简单任务处理。
- DeepSeek-V3.2-Speciale:强制开启深度思考功能,最大输出长度高达 128k Token。
需要特别指出的是,这 128k 指的是输出长度上限。面对一道高难度奥数题或一次大型代码重构工程,Speciale 可生成数万字的中间推理过程。它会尝试多种路径、持续自我反思,在发现错误时主动回溯修正,直至得出最优解答。这种“以时间换取智能”的策略,正是 System 2 类人工智能的核心体现。
3.3 与 GPT-5 和 Gemini 3.0 的对标表现
DeepSeek 在技术报告中明确表示:
- Speciale 在多项推理基准测试中超越 GPT-5-High 版本;
- 与 Google DeepMind 的Gemini-3.0-Pro 处于同一水平。
这种对齐不仅仅是分数上的接近,更体现在处理逻辑陷阱、多步因果推理等复杂“智商挑战”任务中的真实能力匹配。
智能体能力升级:思维与行动的深度融合
仅有强大的思维能力是不够的,还需具备执行能力。为此,DeepSeek-V3.2 在智能体(Agent)功能方面进行了全面增强。
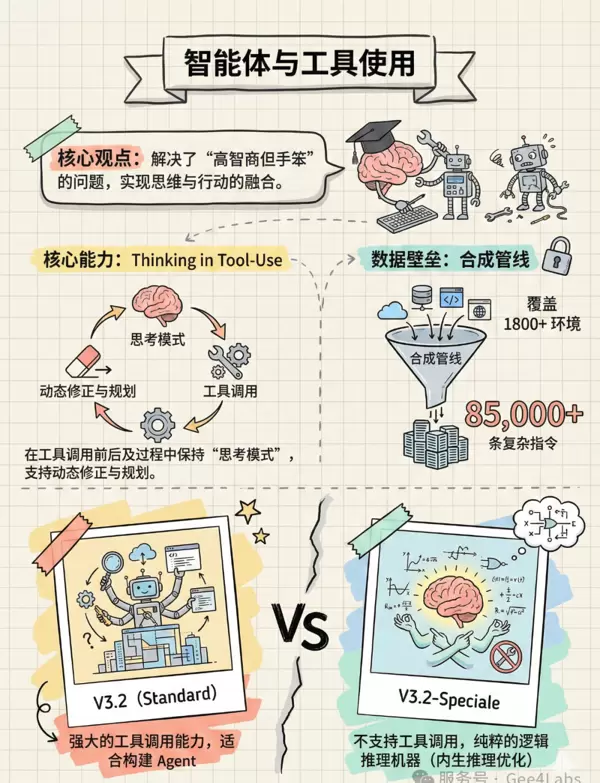
4.1 工具使用中的持续思考(Thinking in Tool-Use)
这是 V3.2 最具突破性的创新之一。
传统的 Agent 通常遵循“思考 → 调用工具 → 执行 → 观察结果 → 再思考”的线性流程,各环节彼此割裂。而 DeepSeek-V3.2 实现了在调用工具的过程中保持连贯思考,形成闭环反馈。
动态调整示例:
- 模型初步判断:“我需要读取这个 CSV 文件,但不确定编码格式,应优先尝试 UTF-8。”
- 执行相应代码;
- 系统返回解码失败错误;
- 模型继续推理:“报错表明可能为 GBK 编码,需修改参数重新尝试。”
- 自动更新指令并再次执行。
此类基于环境反馈实时调整策略的能力,使得智能体不再是机械执行脚本的程序,而是一个具备适应性和决策力的“智慧实体”。
4.2 覆盖 1800+ 环境的合成数据管道
为了充分训练上述能力,DeepSeek 构建了一套高度复杂的“大规模智能体任务合成管线”。该系统生成了超过 85,000 条多样化复杂指令,涵盖 1800 多个真实与模拟环境,包括 Jupyter Notebook、各类 API 接口、网页浏览场景等。
这一庞大训练集赋予了 V3.2 极强的泛化能力,即使面对未曾接触过的工具,也能快速理解并有效运用。
4.3 Speciale 的“专注设定”
值得注意的是,目前 DeepSeek-V3.2-Speciale 并不支持工具调用功能。
这是一种有意的设计取舍。Speciale 被定位为纯粹的逻辑推理引擎,类似于一位被隔离研究难题的数学家。引入外部工具可能会干扰其经过强化学习建立的精密推理链路。因此,若用户需要联网查询、运行代码等功能,建议使用标准版 V3.2;若目标是解决如黎曼猜想级别的理论问题,则 Speciale 是更优选择。
性能评测:金牌实力的实证
数据是最有力的证明。DeepSeek-V3.2-Speciale 的基准测试成绩足以令同行感到压力。
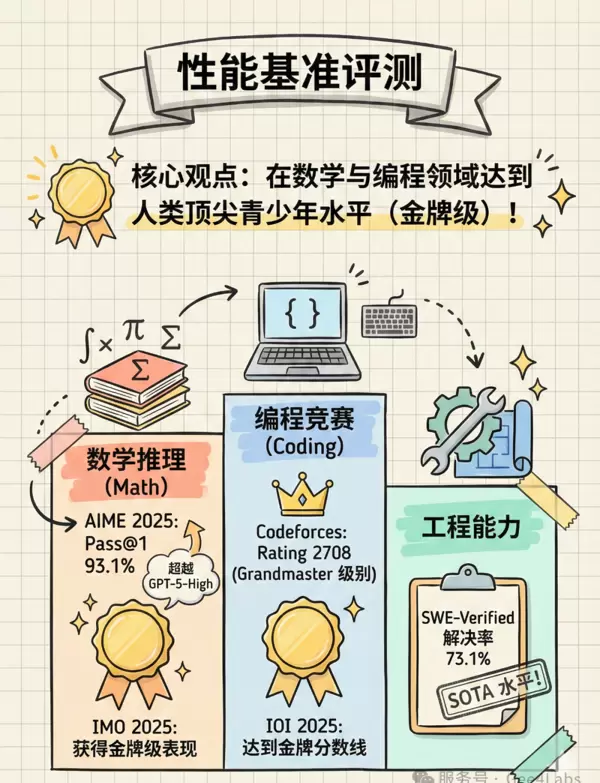
5.1 数学领域:IMO 2025 金牌水准
在数学推理方面,Speciale 表现出绝对的统治级实力,成功达到国际数学奥林匹克竞赛(IMO)2025 年金牌水平,展示了其在符号推理、定理证明与复杂建模方面的顶尖能力。
5.2 编程能力:Codeforces Grandmaster 级表现
在国际知名的编程竞赛平台 Codeforces 上,Speciale 的模拟评级达到了 2708 分。
这一分数已进入“红名”级别,即 Grandmaster 段位,标志着其在算法设计与数据结构应用方面具备顶尖水平。作为对比,Gemini-3.0-Pro 的评分为约 2537 分,明显低于 Speciale。这意味着 DeepSeek 在复杂编程任务的处理上,已经超越了绝大多数人类顶级程序员。
5.3 工程实践能力:SWE-Verified 高解决率
在评估真实软件工程 Bug 解决能力的 SWE-Verified 榜单中,Speciale 实现了 73.1% 的问题解决率。值得注意的是,该成绩是在不支持工具调用的前提下达成的——模型仅通过生成补丁代码完成修复。这种纯文本输出方式下的高准确率,充分体现了其强大的代码理解与生成能力,展现出远超常规水平的工程实用性。
AIME 2025 与 IMO 2025 数学竞赛突破
在 AIME 2025(美国数学邀请赛)测试中,Speciale 的 Pass@1 准确率达到 93.1%,部分实验甚至达到 99.2%。相比之下,GPT-5-High 为 90.8%,Gemini-3.0-Pro 为 90.2%,均略逊一筹。
而在 IMO 2025(国际数学奥林匹克)中,官方宣布 Speciale 达到金牌级水平。这不仅意味着它能够解答高难度数学题,更关键的是,它可以构造出逻辑严密、形式规范的完整数学证明,展现了真正的系统性推理能力。

6.1 经济学视角:缓存感知定价策略
DeepSeek 最具颠覆性的并非技术本身,而是其推动 AI 商品化的决心。其推出的缓存感知定价机制(Cache-Aware Pricing),直接挑战现有市场成本结构。
具体定价如下:
- Cache Hit(缓存命中): $0.028 / 1M Token(约合人民币 0.20 元/百万词)
- Cache Miss(未命中): $0.28 / 1M Token
- Output(输出): $0.42 / 1M Token
对于企业级应用场景,如基于大规模知识库的 RAG 系统,一旦背景信息被缓存,后续查询的输入成本可降至 GPT-4o 的百分之一甚至千分之一。这使得高频次、大体量的智能服务边际成本趋近于零,极大降低了落地门槛。
6.2 Speciale 的“亏本公测”战略
令人震惊的是,高性能版本 Speciale 的价格与普通版 V3.2 完全相同。考虑到 Speciale 在推理过程中需执行大量思维链(CoT)计算,GPU 资源消耗显著高于标准模型,此定价显然处于亏损状态。
目前该服务通过一个“临时端点”提供,有效期至 2025 年 12 月 15 日,本质上是一场全球范围的限时公测。DeepSeek 的真实意图在于:以极低价格吸引全球开发者使用并测试其极限能力,从而收集高质量的复杂任务 Prompt 和人类反馈数据。这些数据将成为训练下一代模型 V4 的核心资源,形成闭环迭代优势。
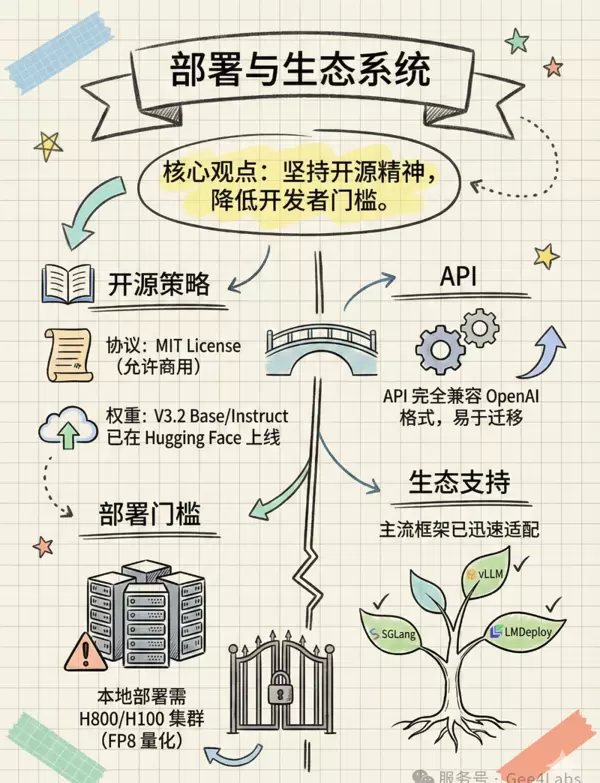
开源生态建设:坚守开放精神
在闭源模型主导市场的背景下,DeepSeek 始终坚持开源路线,展现出独特的行业责任感。
关键开源信息包括:
- 授权协议: MIT License,允许免费商用、修改和微调,无法律风险
- 模型权重: DeepSeek-V3.2 Base 与 Instruct 版本均已发布于 Hugging Face 平台
- 部署建议: 尽管开源,但其 685B 参数规模决定了本地运行门槛极高。推荐配置为至少 8 卡 H100 或 H800 组成的集群,并结合 vLLM 或 SGLang 等推理框架进行 FP8 量化部署。对大多数中小型开发者而言,调用 API 仍是更高效的选择

结论与展望:重塑 AI 行业规则
DeepSeek-V3.2 与 Speciale 在 2025 年末的发布,是中国 AI 产业交出的一份里程碑式答卷。它验证了三个重要趋势:
- 架构创新的价值: 通过 MoE(混合专家)与 DSA(动态稀疏激活)等技术,超大规模模型得以突破传统 Scaling Laws 的效率瓶颈,在性能与成本之间实现更优平衡;
- 开源模型的潜力: 借助强化学习与高质量数据训练,开源体系完全有能力在逻辑推理(System 2 思维)领域追平乃至超越闭源 SOTA 模型;
- 性价比驱动变革: 极致的成本控制正在重构 AI 应用的经济模型,“万物皆可智能化”正从愿景走向现实。
如今 Speciale 所展现的“深度思考”能力,未来将逐步内化为标准模型的基础功能。当其他厂商仍将高端智能锁定于高价云端时,DeepSeek 已经通过几毛钱一次的 API,将同等水平的智能能力输送至全球开发者的手中。
这不仅是技术上的胜利,更是开放、共享精神的胜利。

 京公网安备 11010802022788号
京公网安备 11010802022788号







