


 雷达卡
雷达卡



自然语言处理(Natural Language Processing, NLP)作为人工智能的重要分支,专注于使计算机具备理解、生成和处理人类语言的能力,从而实现人与机器之间的高效语言交互。无论是日常生活中常见的语音助手(如Siri、小爱同学)、机器翻译工具(如Google翻译),还是企业广泛使用的智能客服、文本摘要系统、情感分析平台,NLP技术已深度融入社会的各个领域,涵盖生活、工作与科研等多个层面。
本文将围绕NLP的技术体系展开,从基础理论入手,深入剖析核心算法原理,并结合实际代码示例与可视化图表,全面覆盖关键技术、典型应用场景以及未来发展方向,帮助读者构建系统化的NLP知识结构,实现从入门到进阶的跨越。
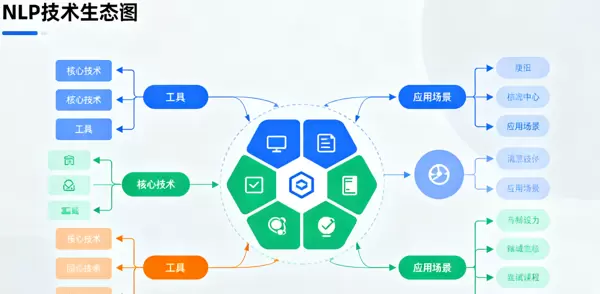
图 1:NLP 技术生态图谱(核心技术、工具与应用场景之间的关联关系)
一、NLP 的技术基础:从语言特性到整体架构
1.1 自然语言的本质特征与NLP面临的主要挑战
人类语言具有四大显著特征:
- 模糊性:例如,“这个苹果很甜”中的“甜”缺乏明确的量化标准;
- 上下文依赖性:比如句子“他喜欢打篮球,也喜欢看它”中,“它”需根据前文判断指代的是“篮球”;
- 多义性:同一个词在不同语境下含义不同,如“银行”既可指金融机构,也可指河岸;
- 文化关联性:成语、俚语等表达方式的理解往往依赖特定的文化背景。
这些特性给自然语言处理带来了三大关键挑战:
- 语义理解:如何将非结构化的自然语言转化为机器可识别和操作的结构化信息;
- 上下文建模:有效捕捉文本中的长距离依赖关系及代词指代问题;
- 泛化能力:确保模型在多样化的场景与领域中保持稳定表现。
1.2 NLP 的技术框架与主要流程
NLP的整体技术流程可以概括为:“输入 → 预处理 → 特征提取 → 模型训练 → 输出 → 应用”。整个链路完整连接了原始文本到最终落地应用的全过程,具体结构如图2所示:
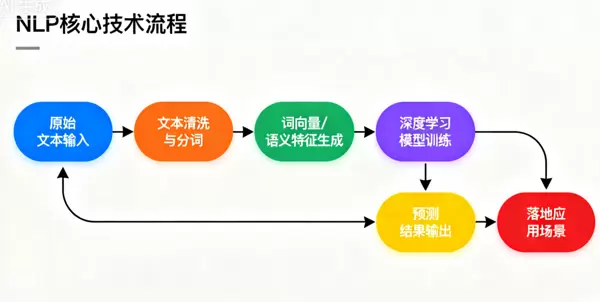
图 2:NLP 核心技术流程(从原始文本到实际应用的全路径)
各阶段的核心任务如下:
- 输入:接收原始文本(如句子、段落或文档)或语音信号(需先转写为文字);
- 预处理:进行文本清洗、分词、词性标注、句法分析等操作,将非结构化数据转换为结构化格式;
- 特征提取:利用TF-IDF、词嵌入(word embedding)等方式将文本映射为数值向量,供模型使用;
- 模型训练:依据任务类型选择合适的模型架构(如分类任务采用CNN,生成任务采用Transformer),并通过数据迭代优化参数;
- 输出:生成结构化结果,如分类标签、翻译内容、摘要文本或问答响应;
- 应用:将模型输出部署至具体场景,如智能客服系统、自动翻译服务、内容审核机制等。
1.3 主流NLP工具与开源资源
在实际开发过程中,借助成熟的开源工具能够显著提升研发效率。以下是当前主流的NLP工具分类及其代表性项目:
| 工具类型 | 代表工具 | 核心功能 |
|---|---|---|
| 基础预处理 | NLTK、spaCy、jieba(中文) | 支持分词、词性标注、句法分析等功能 |
| 词嵌入工具 | Gensim、FastText | 用于训练Word2Vec、FastText等词向量模型 |
| 深度学习框架 | PyTorch、TensorFlow/Keras | 构建和训练复杂的NLP深度学习模型 |
| 预训练模型库 | Hugging Face Transformers | 提供BERT、GPT、T5等先进预训练模型的调用接口 |
| 中文NLP专用工具 | 哈工大LTP、百度飞桨PaddleNLP | 针对中文语言特点优化的分词、命名实体识别、句法分析工具 |
本文将以Python为主要编程语言,综合运用jieba、spaCy、Hugging Face Transformers等工具开展实践演示。
二、NLP 预处理:实现文本的“清洗与结构化”
预处理是自然语言处理的关键前置步骤,其质量直接影响后续模型的表现。该环节的核心目标在于清除噪声、保留关键信息,并将非结构化文本转化为适合机器处理的形式。本节将详细解析预处理的主要步骤并辅以实战代码说明。
2.1 预处理的关键步骤详解
(1)文本清洗:剔除无效内容
原始文本常包含各类干扰信息,如特殊符号、标点、多余空格、URL链接、表情符号等,需先行清理。例如:
- 原始文本:“【重磅】NLP 技术入门!
https://xxx.com
???? 一起学习 #AI# 自然语言处理” - 清洗后文本:“重磅 NLP 技术入门 一起学习 AI 自然语言处理”
(2)分词:划分语言基本单元
分词旨在将连续的文本切分为独立的语言单位——“词”或“子词”。中文由于缺乏天然分隔符,需专门处理;而英文通常以空格为界,相对简单。例如:
- 原始中文文本:“自然语言处理是人工智能的核心分支”
- 分词结果:“自然语言处理 / 是 / 人工智能 / 的 / 核心分支”
(3)词性标注(POS Tagging):识别词汇语法角色
词性标注为每个词语赋予语法类别标签(如名词、动词、形容词等),有助于提升语义解析精度。例如:
- 分词结果:“自然语言处理 / 是 / 人工智能 / 的 / 核心分支”
- 词性标注结果:“自然语言处理(名词)/ 是(动词)/ 人工智能(名词)/ 的(助词)/ 核心分支(名词)”
(4)停用词去除:过滤低价值词汇
停用词是指出现频率高但语义贡献弱的词语(如“的”、“是”、“在”、“和”等)。移除这类词汇可降低数据维度,提高模型运行效率。
(5)句法分析与命名实体识别(NER):提取深层结构信息
句法分析用于揭示句子内部的语法构成,例如对“他喜欢打篮球”进行分析可得:“主语(他)+ 谓语(喜欢)+ 宾语(打篮球)”;
命名实体识别(NER)是自然语言处理中的关键步骤,用于从文本中抽取出特定类型的实体信息,如人名、地名、机构名和时间等。例如,句子“李白于公元 701 年出生在碎叶城”经过 NER 处理后,可得到如下结果:“李白”为人名,“公元 701 年”为时间,“碎叶城”为地名。
2.2 中文文本预处理实战:结合 jieba 与 哈工大 LTP 工具
中文文本的预处理面临的主要挑战在于分词精度与实体识别效果。为实现高质量的结构化输出,以下采用 jieba(轻量级分词工具)与 哈工大 LTP(高精度自然语言处理平台)相结合的方式,完成包括文本清洗、分词、词性标注及命名实体识别在内的全流程处理。
2.2.1 环境配置说明
# 安装依赖库
pip install jieba ltp pyhanlp pandas numpy2.2.2 完整预处理代码实现(涵盖清洗、分词、词性标注与 NER)
import re
import jieba
import jieba.analyse
from ltp import LTP
import pandas as pd
# 初始化LTP(哈工大中文NLP工具,需下载模型:默认自动下载)
ltp = LTP()
# ---------------------- 1. 文本清洗函数 ----------------------
def clean_text(text):
"""去除噪声,保留中文、英文、数字"""
# 去除URL链接
text = re.sub(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', '', text)
# 去除特殊字符、表情符号(保留中文、英文、数字、空格)
text = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s]', '', text)
# 去除多余空格(连续空格转为单个)
text = re.sub(r'\s+', ' ', text).strip()
return text
# ---------------------- 2. 分词函数(jieba + 自定义词典) ----------------------
def segment_text(text, use_custom_dict=True):
"""分词:支持自定义词典提升精度"""
# 自定义词典(添加领域词汇,如NLP术语)
if use_custom_dict:
jieba.load_userdict('custom_dict.txt') # 格式:词汇 词性 词频(可选)
# 分词(精确模式)
words = jieba.lcut(text, cut_all=False)
return words
# ---------------------- 3. 停用词去除函数 ----------------------
def remove_stopwords(words):
"""去除停用词"""
# 加载停用词表(可自定义扩展)
stopwords = set(pd.read_csv('stopwords.txt', sep='\t', header=None)[0].tolist())
# 过滤停用词
filtered_words = [word for word in words if word not in stopwords and len(word) > 1]
return filtered_words
# ---------------------- 4. 词性标注与NER(基于哈工大LTP) ----------------------
def pos_ner_analysis(text):
"""词性标注 + 命名实体识别"""
# LTP处理(分词、词性标注、NER)
outputs = ltp.pipeline([text], tasks=["seg", "pos", "ner"])
seg_result = outputs.seg[0] # 分词结果
pos_result = outputs.pos[0] # 词性标注结果(采用863词性标注集)
ner_result = outputs.ner[0] # NER结果(格式:(实体类型, 起始索引, 结束索引, 实体文本))
# 整理词性标注结果(词-词性映射)
pos_map = dict(zip(seg_result, pos_result))
# 整理NER结果(提取实体类型和文本)
ner_map = []
for ner in ner_result:
ner_type, start, end, ner_text = ner
ner_map.append({"实体类型": ner_type, "实体文本": ner_text})
return pos_map, ner_map
# ---------------------- 5. 完整预处理流程调用 ----------------------
if __name__ == "__main__":
# 原始文本(示例:科技新闻片段)
raw_text = """【NLP技术前沿】百度于2023年发布了ERNIE 4.0大模型,该模型在中文理解、生成任务中表现优异,
支持多轮对话、文本摘要、机器翻译等功能,相关技术论文已发表在AI顶会NeurIPS上。"""
# 步骤1:文本清洗
cleaned_text = clean_text(raw_text)
print("=== 清洗后文本 ===")
print(cleaned_text)
# 输出:NLP技术前沿 百度于2023年发布了ERNIE 4.0大模型 该模型在中文理解 生成任务中表现优异 支持多轮对话 文本摘要 机器翻译等功能 相关技术论文已发表在AI顶会NeurIPS上
# 步骤2:分词
words = segment_text(cleaned_text)
print("\n=== 分词结果 ===")
print("/".join(words))
# 输出:NLP/技术/前沿/百度/于/2023年/发布/了/ERNIE/4.0/大模型/该/模型/在/中文/理解/生成/任务/中/表现/优异/支持/多轮/对话/文本/摘要/机器翻译/等/功能/相关/技术/论文/已/发表/在/AI/顶会/NeurIPS/上
# 步骤3:去除停用词
filtered_words = remove_stopwords(words)
print("\n=== 去除停用词后 ===")
print("/".join(filtered_words))
# 输出:NLP/技术/前沿/百度/2023年/发布/ERNIE/4.0/大模型/模型/中文/理解/生成/任务/表现/优异/支持/多轮/对话/文本/摘要/机器翻译/功能/相关/技术/论文/发表/AI/顶会/NeurIPS
# 步骤4:词性标注与NER
pos_map, ner_map = pos_ner_analysis(cleaned_text)
print("\n=== 词性标注结果 ===")
for word, pos in pos_map.items():
print(f"{word}: {pos}")
# 输出示例:NLP: n(名词)/ 技术: n / 前沿: n / 百度: nt(机构名) / 2023年: t(时间)...
print("\n=== 命名实体识别结果 ===")
for ner in ner_map:
print(f"{ner['实体类型']}: {ner['实体文本']}")
# 输出:ORG: 百度 / TIME: 2023年 / ORG: NeurIPS / MODEL: ERNIE 4.02.3 预处理阶段的关键注意事项
- 自定义词典的引入:针对专业领域文本(如医学、法律),标准分词器容易出现切分错误(例如将“深度学习”误分为“深度 / 学习”)。为此,建议添加领域术语至自定义词典以提升准确性。
- 停用词表的灵活调整:不同任务对词语重要性的判断不同。例如,在情感分析任务中,“非常”“极其”等副词具有强烈的情感倾向,应保留在文本中而非作为停用词移除。
- NER 模型的选择策略:对于中文命名实体识别,推荐使用高精度模型如哈工大 LTP 或百度 ERNIE,其识别准确率显著优于通用工具。
- 效率与精度的权衡:在实际应用中需根据数据规模做出取舍——大规模语料可优先选用 jieba 实现快速处理;而对小规模但要求高精度的任务,则更适合使用 LTP 进行精细化分析。

图 3:中文预处理前后对比示意图(左侧为原始未处理文本,右侧为经清洗与结构化后的输出结果)
三、NLP 核心技术 I:词嵌入 —— 实现文本的“数值化革命”
在自然语言处理系统中,机器无法直接理解原始文本,必须将其转化为数值形式才能进行计算。词嵌入(Word Embedding)正是这一转化过程的核心技术。它通过将每个词汇映射到一个低维稠密向量空间中,使得语义相近的词语在向量空间中的距离也更接近。例如,“猫”与“狗”的向量距离通常远小于“猫”与“汽车”之间的距离。
3.1 词嵌入的技术发展历程:从 one-hot 到动态预训练模型
词嵌入技术经历了四个主要发展阶段,各阶段代表性方法及其特点如下表所示:
| 技术类型 | 代表方法 | 核心原理 | 优点 | 缺点 |
|---|---|---|---|---|
| 离散表示 | One-Hot 编码 | 为每个词分配唯一索引,对应位置置 1,其余为 0 | 实现简单、计算高效 | 维度爆炸(如词汇量达10万则向量维数也为10万)、无语义关联(“猫”与“狗”正交) |
| 统计表示 | TF-IDF、LSA | 基于词频统计或矩阵分解,提取全局共现特征 | 缓解高维问题 | 难以捕捉局部上下文信息,语义表达能力有限 |
| 分布式表示 | Word2Vec、GloVe、FastText | 利用神经网络,通过上下文预测学习词向量 | 向量维度低且稠密(通常50–300维),能有效表达语义关系(如“国王 - 男人 + 女人 ≈ 女王”) | 静态向量表示,无法解决一词多义问题 |
| 动态词向量 | ELMo、BERT | 基于深层预训练模型,根据上下文动态生成词向量 | 可区分多义词的不同含义(如“银行”在“去银行存钱”和“河边银行”中向量不同) | 模型复杂,推理成本较高 |
3.2 经典词嵌入模型 Word2Vec:原理详解与中文实战
Word2Vec 是由 Google 于 2013 年提出的一种经典词向量学习模型,其核心思想是通过预测上下文来学习词语的分布式表示。该模型包含两种结构:CBOW(Continuous Bag-of-Words)和Skip-gram,已成为现代 NLP 发展的重要里程碑。
3.2.1 Word2Vec 的基本原理
该模型建立在“分布式假设”基础之上:即拥有相似上下文的词语往往具有相近的语义。其两个主要变体分别为:
- CBOW 模型:输入目标词周围的上下文词向量,用于预测中心词。适用于语料较少的场景。
- Skip-gram 模型:输入中心词的向量,用来预测其上下文词汇。在大规模数据上表现更优,语义捕捉能力更强。
两种模型的结构示意如图 4 所示:
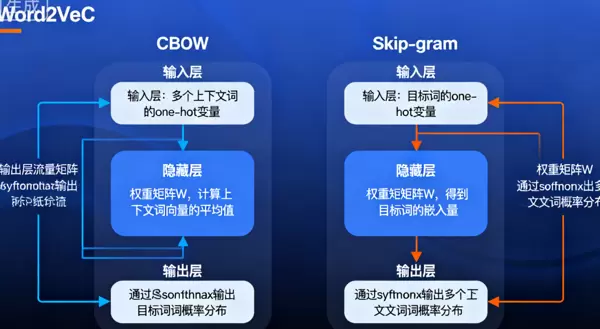
图 4:Word2Vec 中 CBOW 与 Skip-gram 的模型架构对比
为了克服传统 Softmax 层在大规模词汇表下计算开销过大的问题,Word2Vec 引入了负采样(Negative Sampling)和层次 Softmax(Hierarchical Softmax)两种优化策略,大幅提升了训练效率,使其能够应用于海量文本语料。
3.2.2 Word2Vec 中文词向量训练实战(基于 Gensim 库)
以下演示如何使用 Gensim 库训练中文词向量,所用语料为中文维基百科文本(需提前下载并完成预处理)。
(1)数据准备阶段
首先获取中文维基百科原始语料:
https://dumps.wikimedia.org/zhwiki/
下载后需提取纯文本内容,并进行必要的预处理操作(如去除标签、特殊符号、繁体转简体等),以构建适合训练的语料库。

 京公网安备 11010802022788号
京公网安备 11010802022788号







