


 雷达卡
雷达卡



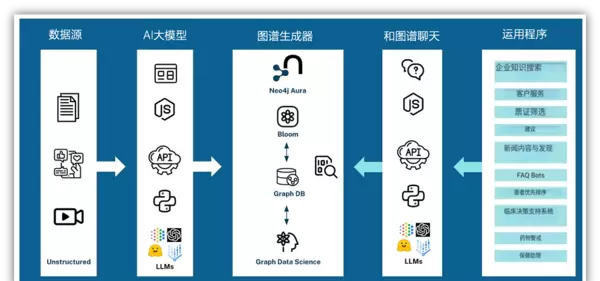 ### 工具简介:什么是大模型知识图谱构建器?
大模型知识图谱构建器是一款基于Web的在线应用,专为简化知识图谱构建过程而设计。它依托机器学习模型,能够自动处理PDF文件、网页内容和YouTube视频等多源数据,从中抽取实体及其相互关系,最终形成结构化的知识图谱。
前端采用React框架开发,基于Needle Starter Kit搭建;后端则由Python FastAPI驱动。核心技术模块采用了Neo4j为LangChain贡献的`llm-graph-transformer`组件,确保了高精度的信息提取能力。
整个使用流程极为流畅,主要包括以下四个步骤:
1. **导入数据**:支持多种格式的数据源,包括PDF文档、维基百科页面以及YouTube视频链接。
2. **识别实体**:借助AI大模型自动分析文本内容,精准识别其中的关键实体及它们之间的语义关系。
3. **构建图谱**:将提取出的实体和关系转换为图结构数据,并存储于Neo4j图数据库中。
4. **使用图谱**:提供直观的图形界面,用户可以轻松上传资料、查看生成的图谱,并通过RAG代理与数据“对话”,实现零代码交互式探索。
### 工具简介:什么是大模型知识图谱构建器?
大模型知识图谱构建器是一款基于Web的在线应用,专为简化知识图谱构建过程而设计。它依托机器学习模型,能够自动处理PDF文件、网页内容和YouTube视频等多源数据,从中抽取实体及其相互关系,最终形成结构化的知识图谱。
前端采用React框架开发,基于Needle Starter Kit搭建;后端则由Python FastAPI驱动。核心技术模块采用了Neo4j为LangChain贡献的`llm-graph-transformer`组件,确保了高精度的信息提取能力。
整个使用流程极为流畅,主要包括以下四个步骤:
1. **导入数据**:支持多种格式的数据源,包括PDF文档、维基百科页面以及YouTube视频链接。
2. **识别实体**:借助AI大模型自动分析文本内容,精准识别其中的关键实体及它们之间的语义关系。
3. **构建图谱**:将提取出的实体和关系转换为图结构数据,并存储于Neo4j图数据库中。
4. **使用图谱**:提供直观的图形界面,用户可以轻松上传资料、查看生成的图谱,并通过RAG代理与数据“对话”,实现零代码交互式探索。
 你可以在Neo4j官网直接访问该应用程序,无需绑定信用卡或配置AI模型密钥,全程免费且无障碍使用。
若希望在本地环境部署此工具,也可前往GitHub仓库获取源码,并按照下文所述步骤进行安装和运行。
---
### 环境准备
在开始使用前,需要先创建一个Neo4j数据库实例。推荐使用Neo4j提供的免费AuraDB服务,具体操作如下:
1. 访问 [https://console.neo4j.io](https://console.neo4j.io),登录或注册账户;
2. 在Instances面板中创建一个新的AuraDB Free数据库;
3. 下载生成的连接凭证文件;
4. 等待数据库实例启动完成。
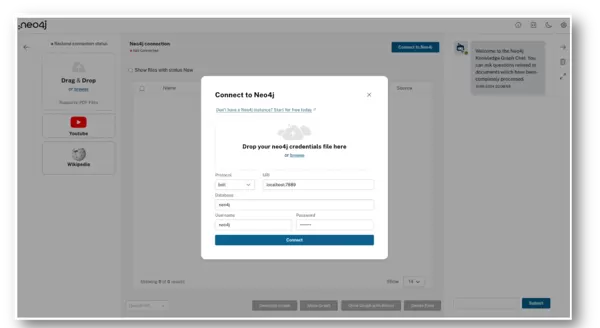
当数据库成功运行并获取凭证后,点击控制台右上角的“Connect to Neo4j”按钮,即可跳转至大模型知识图谱构建器界面。
将之前下载的凭证文件拖入连接弹窗中,系统会自动填充主机地址、用户名和密码等信息。当然,也支持手动输入各项参数完成连接。
---
### 构建知识图谱的实际操作
接下来进入核心环节——知识图谱的创建。首先需导入原始数据,随后系统将调用AI模型自动识别其中的关键实体及其关联。
界面左侧提供了三个输入区域:
- 第一个区域用于上传PDF或其他文档文件(支持拖拽操作);
- 第二个输入框允许粘贴YouTube视频链接(目前仅支持YouTube);
- 第三个输入框可用于输入维基百科页面的URL。
本次演示中,我上传了以下四类资料:
1. 一份供应链企业的内部PDF文档,详细描述其产品体系与运营策略;
2. 一篇来自福布斯的行业新闻文章;
3. 一段关于《企业可持续发展尽职调查指令》(CSDDD)的YouTube讲解视频;
4. 两篇来自维基百科的相关主题文章。
你可以根据需求选择性地上传某一类或多类数据源。
上传过程中,系统会调用LangChain的文档加载器和YouTube解析器,将所有内容解析并以“文档节点”的形式存入图数据库。
所有文件上传完成后,界面将显示如下状态:
你可以在Neo4j官网直接访问该应用程序,无需绑定信用卡或配置AI模型密钥,全程免费且无障碍使用。
若希望在本地环境部署此工具,也可前往GitHub仓库获取源码,并按照下文所述步骤进行安装和运行。
---
### 环境准备
在开始使用前,需要先创建一个Neo4j数据库实例。推荐使用Neo4j提供的免费AuraDB服务,具体操作如下:
1. 访问 [https://console.neo4j.io](https://console.neo4j.io),登录或注册账户;
2. 在Instances面板中创建一个新的AuraDB Free数据库;
3. 下载生成的连接凭证文件;
4. 等待数据库实例启动完成。
当数据库成功运行并获取凭证后,点击控制台右上角的“Connect to Neo4j”按钮,即可跳转至大模型知识图谱构建器界面。
将之前下载的凭证文件拖入连接弹窗中,系统会自动填充主机地址、用户名和密码等信息。当然,也支持手动输入各项参数完成连接。
---
### 构建知识图谱的实际操作
接下来进入核心环节——知识图谱的创建。首先需导入原始数据,随后系统将调用AI模型自动识别其中的关键实体及其关联。
界面左侧提供了三个输入区域:
- 第一个区域用于上传PDF或其他文档文件(支持拖拽操作);
- 第二个输入框允许粘贴YouTube视频链接(目前仅支持YouTube);
- 第三个输入框可用于输入维基百科页面的URL。
本次演示中,我上传了以下四类资料:
1. 一份供应链企业的内部PDF文档,详细描述其产品体系与运营策略;
2. 一篇来自福布斯的行业新闻文章;
3. 一段关于《企业可持续发展尽职调查指令》(CSDDD)的YouTube讲解视频;
4. 两篇来自维基百科的相关主题文章。
你可以根据需求选择性地上传某一类或多类数据源。
上传过程中,系统会调用LangChain的文档加载器和YouTube解析器,将所有内容解析并以“文档节点”的形式存入图数据库。
所有文件上传完成后,界面将显示如下状态:
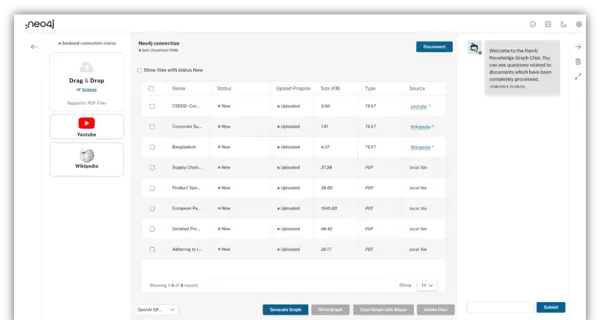 此时只需选择所需的AI模型,然后点击“Generate Graph”按钮,系统便会自动完成后续的所有处理工作。
如果你只想针对部分文件生成图谱,可以在文件列表的第一列勾选目标项,再执行生成操作。
此外,若希望使用预设或自定义的图结构模式,可点击右上角的设置图标,在下拉菜单中选择已有模式。你也可以手动定义节点标签和关系类型,或者从现有Neo4j数据库中提取模式结构。另一种方式是直接粘贴一段文本,让AI模型分析内容并推荐合适的图谱 schema。
---
### 图谱生成的工作原理
整个图谱构建过程的技术实现可分为以下几个阶段:
1. **内容分块**:原始文档被切分为较小的文本片段,以便于模型处理和上下文理解;
2. **实体与关系抽取**:利用AI大模型对每个文本块进行分析,识别其中的实体(如人名、组织、概念等)以及它们之间的语义关系;
3. **图结构转换**:将提取出的实体和关系映射为图数据库中的节点和边,写入Neo4j;
4. **可视化呈现与交互**:通过前端界面展示生成的知识图谱,并启用RAG机制,使用户能用自然语言提问并获得基于图谱的回答。
这一流程实现了从非结构化数据到可交互知识网络的全自动转化,极大降低了知识管理的技术门槛。
此时只需选择所需的AI模型,然后点击“Generate Graph”按钮,系统便会自动完成后续的所有处理工作。
如果你只想针对部分文件生成图谱,可以在文件列表的第一列勾选目标项,再执行生成操作。
此外,若希望使用预设或自定义的图结构模式,可点击右上角的设置图标,在下拉菜单中选择已有模式。你也可以手动定义节点标签和关系类型,或者从现有Neo4j数据库中提取模式结构。另一种方式是直接粘贴一段文本,让AI模型分析内容并推荐合适的图谱 schema。
---
### 图谱生成的工作原理
整个图谱构建过程的技术实现可分为以下几个阶段:
1. **内容分块**:原始文档被切分为较小的文本片段,以便于模型处理和上下文理解;
2. **实体与关系抽取**:利用AI大模型对每个文本块进行分析,识别其中的实体(如人名、组织、概念等)以及它们之间的语义关系;
3. **图结构转换**:将提取出的实体和关系映射为图数据库中的节点和边,写入Neo4j;
4. **可视化呈现与交互**:通过前端界面展示生成的知识图谱,并启用RAG机制,使用户能用自然语言提问并获得基于图谱的回答。
这一流程实现了从非结构化数据到可交互知识网络的全自动转化,极大降低了知识管理的技术门槛。

将小块信息存储在图结构中,并与文档节点及其他小块相互连接,从而支持高级RAG模式的实现。
嵌入向量会被计算并保存,同时建立向量索引,用于高效检索。具有高度相似性的小块之间通过SIMILAR关系相连,构建出K最近邻图结构。
利用llm-graph-transformer或diffbot-graph-transformer工具,从原始文本中抽取实体及其语义关系。这些提取出的实体作为节点存入图数据库,并与它们来源的小块建立关联。
知识图谱的构建与探索
从文档中提取的数据被转化为图形结构:实体成为图中的节点,关系则表现为连接节点的边。Neo4j在处理此类复杂网络方面具备显著优势,能够快速存储和查询图数据,使生成的知识图谱可立即投入实际应用。
在发起基于RAG代理的提问前,用户可以选择一个或多个文档,然后点击“显示图谱(Show Graph)”按钮。系统将展示所选文档中包含的实体;此外,也可在此视图中查看文档节点和文本块节点。
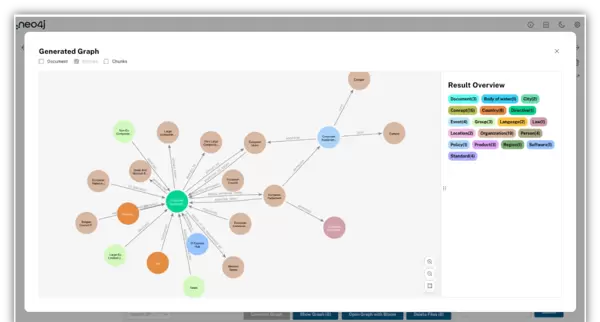
点击“Open Graph with Bloom”按钮可启动Neo4j Bloom,对已构建的知识图谱进行可视化浏览。若需清理数据,可选择“删除文件(Delete files)”,该操作会移除选定文档及其对应文本块,根据设置还可一并清除相关实体。
与上传数据交互:启用RAG代理对话
进入右侧面板后,即可开始使用RAG代理进行对话——这是整个流程的最后一步。
其工作原理如下所示:
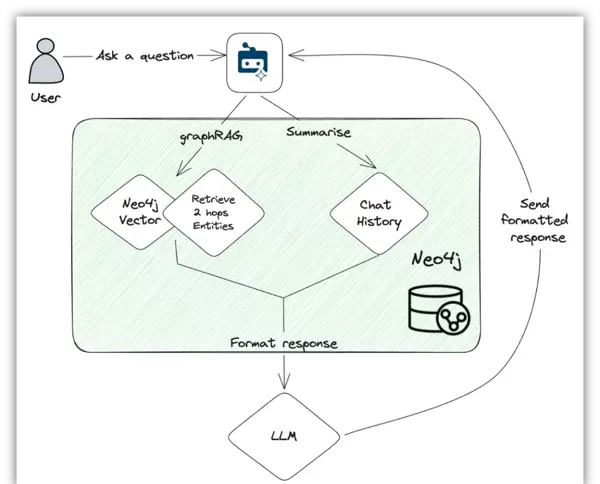
当用户提交问题时,系统首先调用Neo4j的向量索引和检索机制,查找与问题最相关的文本块,并沿图谱扩展最多两跳范围内的关联实体。同时,系统还能汇总当前聊天历史,将其作为上下文的一部分加以利用,以增强回答准确性。
最终,问题本身、向量检索结果以及聊天记录等多源信息将被整合,并传送给指定的大语言模型。借助自定义提示模板,模型能接收到完整的输入背景及资料来源,进而依据这些信息生成格式规范的回答。该提示还包含多项控制指令,例如要求引用出处、禁止在信息不足时猜测答案等。
完整的提示内容和逻辑定义可在项目文件QA_integration.py中找到,具体位置标记为FINAL_PROMPT。
文件路径:https://github.com/neo4j-labs/llm-graph-builder/blob/main/backend/src/QA_integration.py#L59
聊天界面功能说明
在主界面右侧的聊天窗口中,提供三个基础操作按钮:
- ??关闭:隐藏聊天机器人界面
- ??清除聊天记录:清空当前会话的所有对话内容
- ??最大化窗口:以全屏模式展开聊天界面
在RAG代理返回回答之后,用户还可使用以下三项附加功能:
- ??详情:弹出详细信息窗口,展示代理如何获取和利用来源数据,包括文档、文本块及实体信息,同时显示所用AI模型及令牌消耗情况
- ??复制:将当前回答复制到系统剪贴板
- ??文字转语音:朗读回答内容
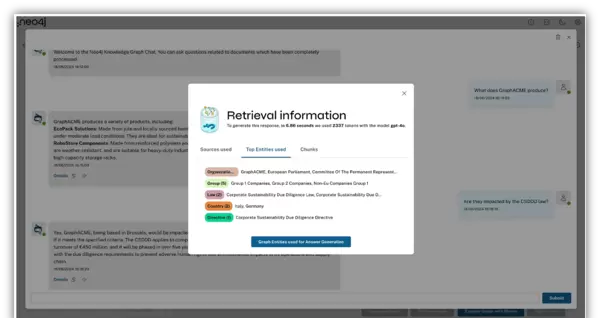
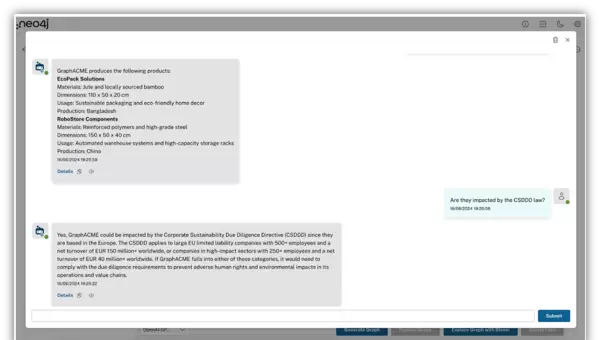
基于知识图谱的问答实践
现在可以针对已上传文档的内容发起查询。例如,可以询问某公司生产的产品列表,进一步了解这些产品是否受到CSDDD法规的影响,以及具体产生哪些合规层面的变化。
结语
如希望深入了解AI大模型驱动的知识图谱构建技术,建议访问对应的GitHub仓库,其中提供了详尽的技术文档、示例代码及完整实现方案。

 京公网安备 11010802022788号
京公网安备 11010802022788号







