


 雷达卡
雷达卡



在人工智能领域,能够同时理解和处理图像与文本的多模态大语言模型(MLLMs)已逐渐成为主流。这类模型可以回答诸如“图中的小狗正在做什么”之类的问题,能为图片生成描述性文字,甚至解析复杂的科学图表。然而,尽管功能强大,它们普遍存在一个显著缺陷:资源消耗过高。
由于图像会被分解成大量“视觉token”——即图像信息的基本单元,导致模型在处理时计算复杂度急剧上升。这种高负载使得大多数普通设备,如手机或边缘计算终端难以承载。为了实现轻量化部署,研究者通常会压缩或减少视觉token的数量。但这一操作往往带来副作用:关键图像细节丢失,模型识别能力下降,出现“看不清”或“理解错”的情况。
如何在降低计算负担的同时,保留模型对图像内容的精准理解?东南大学最新提出的一种名为EM-KD的框架为此提供了高效解决方案。
一、核心挑战:效率与性能的两难抉择
当前多模态模型面临的核心矛盾在于:追求运行效率往往以牺牲准确性为代价。
传统多模态模型:使用大量视觉token(例如每张图拆分为576个),能充分捕捉图像细节,具备较强的语义理解能力。但其高昂的计算开销和延迟(latency)限制了其在资源受限设备上的应用。
高效型多模态模型:通过减少视觉token数量(如压缩至144个)来提升推理速度,却因此丢失部分关键视觉特征,在需要精细判别的任务中表现不佳,比如区分相似物体或读取数据图表。
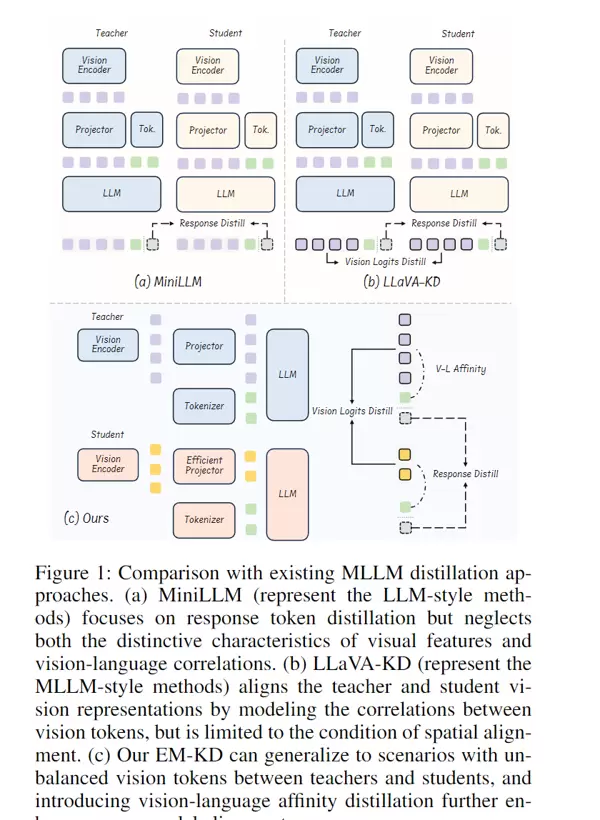
现有知识蒸馏方法的不足:虽然已有研究尝试利用知识蒸馏技术,让小型学生模型从大型教师模型中学习知识,但由于师生模型之间的视觉token数量不一致、空间位置不对齐,导致知识传递不完整,效果有限。
二、方法突破:EM-KD的三阶段协同优化机制
EM-KD(Efficient Multimodal Knowledge Distillation)提出了一套系统性策略,旨在解决视觉token不匹配问题,并实现高质量的知识迁移。整个过程分为三个关键步骤:
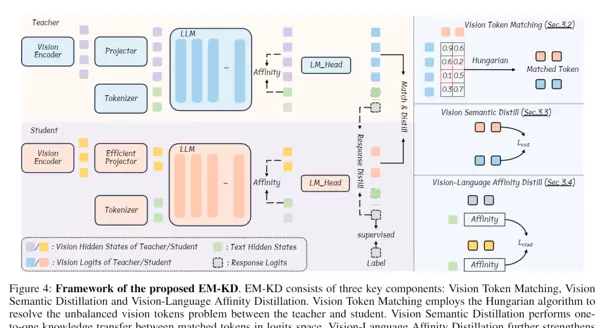
1. 视觉Token对齐:基于匈牙利算法的最优匹配
针对师生模型间视觉token数量不同、结构不对齐的问题,EM-KD引入“匈牙利算法”,实现跨模型token的精准配对:
- 将教师与学生的视觉token转换为“视觉logits”,作为其语义表示;
- 通过曼哈顿距离构建师生token间的相似性矩阵,形成匹配成本表;
- 利用优化算法寻找全局最优的一对一映射关系,确保每个学生token都能对接到最具代表性的教师token,即使总数不同也能完成有效传导。
2. 图像语义蒸馏:反向KL散度驱动深层理解
在完成token对齐后,EM-KD引导学生模型学习教师对图像内容的语义判断逻辑:
- 教师模型将视觉token映射为词汇概率分布(例如,“猫脸”对应“猫”的概率高达90%);
- 采用反向KL散度衡量师生之间分布差异,促使学生模仿教师的决策模式;
- 该机制有效缓解因token压缩带来的语义缺失问题,保障图像理解的完整性。
3. 跨模态关联强化:余弦相似度维持图文一致性
多模态理解的关键在于图像与文本之间的联动。EM-KD特别加强了这一环节:
- 计算教师与学生模型中“视觉token”与“文字token”之间的亲和度(affinity),例如“猫”这个词与“猫脸”图像区域的相关性;
- 使用平滑L1损失函数,使学生模型的图文关联模式尽可能贴近教师;
- 避免出现“文字提及猫,却关注狗的图像区域”等语义错位现象,提升整体推理连贯性。
三、实验验证:全面超越现有方案
研究人员在11项主流基准测试上进行了广泛评估,涵盖视觉问答、科学推理及图表解析等多个维度,结果展现出EM-KD的显著优势:
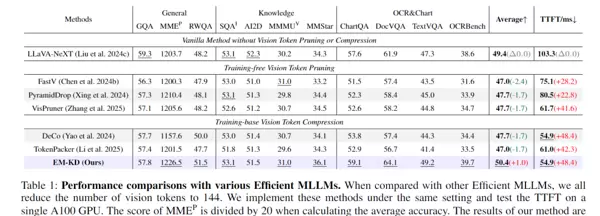
1. 性能领先同类高效模型
- 平均准确率达到50.4%,优于FastV、DeCo等现有高效架构,提升幅度达1~2.7个百分点;
- 在部分任务中甚至超过未压缩token的非高效模型(如LLaVA-NeXT),实现了“更少token,更高性能”的突破。
2. 推理效率大幅提升
- 首词生成延迟(TTFT)由原来的103.3毫秒降至54.9毫秒,提速近一倍;
- 仅保留144个视觉token(相当于传统模型的1/4),仍能维持甚至超越原始性能水平。
3. 蒸馏效果显著优于主流方法
- 相较于MiniLLM、LLaVA-KD等典型蒸馏方案,EM-KD在多项任务中均取得更高得分;
- 平均正确率最高提升0.9个百分点,尤其在细粒度识别和复杂图表理解任务中表现突出。
四、综合评价:优势与局限并存
主要优势
- 直击痛点:首次专门应对师生模型间视觉token数量不平衡问题,实现知识的精准传递;
- 双目标兼顾:既实现高效推理(低token数、低延迟),又提升或多任务性能;
- 兼容性强:无需修改模型结构,可直接集成于现有MLLM框架,便于实际部署;
- 强化跨模态对齐:专门设计图文亲和损失,显著降低图文脱节引发的错误。
当前局限
- 依赖高性能教师模型:若教师模型本身存在偏差或错误,学生模型将继承这些问题;
- 训练阶段开销较大:匈牙利算法匹配与双重蒸馏损失增加了训练时的计算负担,需更多GPU资源支持。
在处理超高清图像或语义极为复杂的任务(如专业医学影像分析)时,现有的token压缩机制仍存在适配不足的问题,可能造成关键细节的丢失。
EM-KD采用“精准token匹配”结合“语义蒸馏”与“图文亲和性双蒸馏”策略,使轻量化多模态模型不仅显著降低计算开销,还能维持甚至提升原有的理解性能,为多模态模型在边缘设备上的高效部署提供了切实可行的技术路径。

 京公网安备 11010802022788号
京公网安备 11010802022788号







