


 雷达卡
雷达卡



SimCSE:一种简洁高效的句子嵌入对比学习方法
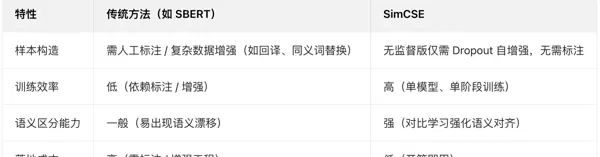
SimCSE(Simple Contrastive Learning of Sentence Embeddings)是一种结构简单但效果卓越的句子表示学习框架,其主要目标是生成高质量的句子向量表达。通过该方法得到的嵌入能够确保语义相近的句子在向量空间中彼此靠近,而语义差异较大的句子则相距较远——这正是现代“基于表示模型的检索”系统(例如向量搜索)所依赖的核心机制。
与传统句子编码技术(如 SBERT)相比,SimCSE 不依赖复杂的数据增强策略或人工标注数据集,而是利用自监督对比学习机制,在无需额外标签的情况下显著提升句子嵌入的语义分辨能力。因此,它已成为当前语义匹配、文本聚类和向量检索任务中的主流选择之一。
相较于早期基于词袋模型或主题建模的方法,SimCSE 所代表的表示学习范式能更深入地捕捉上下文信息,实现更精准的语义理解。
核心原理:自监督 + 对比学习
对比学习的基本思想是:拉近正样本对之间的距离,同时推远负样本对。SimCSE 的关键创新在于,它采用极其简单的方式构建这些样本对,避免了繁琐的人工干预或复杂的增强流程。
无监督版本 SimCSE(应用最广泛)
在无监督设定下,SimCSE 利用模型内部随机性来构造正样本:
- 正样本构建:将同一个句子输入模型两次,借助神经网络中的 Dropout 层引入微小扰动,从而获得两个语义一致但数值略有不同的向量输出。这种策略被称为 “Dropout 增强”,构成了一组有效的正样本对。
- 负样本构建:从当前训练批次中的其他不同句子经编码后所得的向量作为负样本。
- 损失函数:使用 InfoNCE 损失函数,最大化正样本间的相似度,最小化与负样本的相似度。
有监督版本 SimCSE
当存在标注数据时(例如 STS-B 这类语义相似度数据集),可直接使用人工标注的“语义相似句对”作为正样本,其余句子作为负样本进行训练。这种方式进一步提升了模型在特定任务上的表现力。
基于 SimCSE 的向量检索流程
SimCSE 支持典型的“表示型”检索范式,整体流程为:将文本转化为向量,再通过向量相似度完成快速匹配。具体步骤如下:
步骤一:加载或训练 SimCSE 模型
可以直接采用 Hugging Face 提供的预训练 SimCSE 模型,例如:
- 英文模型:
princeton-nlp/sup-simcse-bert-base-uncased - 中文模型:
shibing624/text2vec-base-chinese
也可基于领域专用语料(如医疗、金融文本)对模型进行微调,以增强其在垂直场景下的语义表达能力。
步骤二:建立向量索引库
将文档集合中的每一篇文档或段落输入 SimCSE 模型,转换为固定维度的向量(通常为 768 维)。随后,将这些向量存入向量数据库(如 FAISS、Milvus 或 PGVector),并构建高效索引结构(如 IVF_FLAT、HNSW),以便支持大规模快速检索。
步骤三:执行查询与匹配
用户发起查询时,系统首先将查询语句通过相同的 SimCSE 模型编码成向量;然后在向量库中计算该查询向量与所有文档向量之间的余弦相似度;最后按相似度从高到低排序,返回 Top-K 个最相关的结果。
代码示例
import torch
import faiss
import numpy as np
from typing import List, Tuple
from transformers import AutoTokenizer, AutoModel
# ====================== 1. 配置项 ======================
# 中文 SimCSE 模型(适配中文语义,基于BERT-base)
MODEL_NAME = "shibing624/text2vec-base-chinese"
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
TOP_K = 3 # 检索返回Top-3文档
# ====================== 2. 加载 SimCSE 模型(句子嵌入) ======================
class SimCSEEncoder:
def __init__(self, model_name: str):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name).to(DEVICE)
self.model.eval()
def encode(self, sentences: List[str], batch_size: int = 8) -> np.ndarray:
"""
将句子列表编码为向量(SimCSE 核心:均值池化 + L2归一化)
:param sentences: 待编码的句子列表
:return: 向量矩阵(n_samples × 768)
"""
all_embeddings = []
# 分批编码(避免显存溢出)
for i in range(0, len(sentences), batch_size):
batch_sentences = sentences[i:i+batch_size]
# 编码(禁用梯度)
# SimCSE 文本向量编码逻辑(无梯度推断)
with torch.no_grad():
inputs = self.tokenizer(
batch_sentences,
padding=True,
truncation=True,
max_length=128,
return_tensors="pt"
).to(DEVICE)
outputs = self.model(**inputs)
# 提取 [CLS] token 的隐状态作为句向量
embeddings = outputs.last_hidden_state[:, 0, :] # 取出每句的 CLS 向量
# 进行 L2 范数归一化,便于后续使用余弦相似度计算
embeddings = torch.nn.functional.normalize(embeddings, p=2, dim=1)
all_embeddings.append(embeddings.cpu().numpy())
# 将所有批次的嵌入向量拼接为完整矩阵
all_embeddings = np.concatenate(all_embeddings, axis=0)
return all_embeddings
# 构建基于 FAISS 的高效向量索引(内积形式)
def build_faiss_index(embeddings: np.ndarray) -> faiss.IndexFlatIP:
"""
使用 FAISS 创建内积索引,适用于已归一化的向量(等价于余弦相似度)
:param embeddings: 输入的文档级嵌入向量集合
:return: 已构建并加载数据的索引实例
"""
dim = embeddings.shape[1] # 获取向量维度(如:768 for base models)
# 初始化 IndexFlatIP:支持精确内积检索
index = faiss.IndexFlatIP(dim)
# 将所有文档向量添加至索引中
index.add(embeddings)
return index
 # 基于 SimCSE 模型实现语义检索的核心流程
def simcse_retrieval(
query: str,
corpus: List[str],
encoder: SimCSEEncoder,
index: faiss.IndexFlatIP,
top_k: int = TOP_K
) -> List[Tuple[str, float]]:
"""
执行基于语义相似度的文本检索任务
:param query: 用户输入的查询语句
:param corpus: 待检索的文档语料库
:param encoder: 预训练 SimCSE 编码器
:param index: 已建立的 FAISS 索引结构
:param top_k: 返回最相关的前 K 个结果
:return: 包含匹配文本及其相似度得分的元组列表
"""
# 对查询语句进行编码,并调整形状以适配单条输入
query_embedding = encoder.encode([query])[0].reshape(1, -1)
# 利用 FAISS 在索引中快速搜索最相似的 top_k 向量
scores, indices = index.search(query_embedding, top_k)
# 组装返回结果:过滤非法索引,保留有效匹配项
results = []
for score, idx in zip(scores[0], indices[0]):
if idx < len(corpus): # 安全检查,防止越界访问
results.append((corpus[idx], float(score)))
return results
# 基于 SimCSE 模型实现语义检索的核心流程
def simcse_retrieval(
query: str,
corpus: List[str],
encoder: SimCSEEncoder,
index: faiss.IndexFlatIP,
top_k: int = TOP_K
) -> List[Tuple[str, float]]:
"""
执行基于语义相似度的文本检索任务
:param query: 用户输入的查询语句
:param corpus: 待检索的文档语料库
:param encoder: 预训练 SimCSE 编码器
:param index: 已建立的 FAISS 索引结构
:param top_k: 返回最相关的前 K 个结果
:return: 包含匹配文本及其相似度得分的元组列表
"""
# 对查询语句进行编码,并调整形状以适配单条输入
query_embedding = encoder.encode([query])[0].reshape(1, -1)
# 利用 FAISS 在索引中快速搜索最相似的 top_k 向量
scores, indices = index.search(query_embedding, top_k)
# 组装返回结果:过滤非法索引,保留有效匹配项
results = []
for score, idx in zip(scores[0], indices[0]):
if idx < len(corpus): # 安全检查,防止越界访问
results.append((corpus[idx], float(score)))
return results
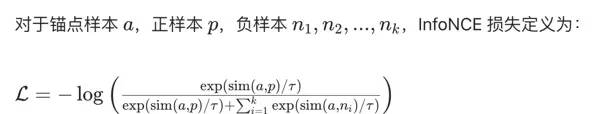 # 示例运行代码:演示从文档编码到语义检索的完整过程
if __name__ == "__main__":
# 构造一个关于儿童肥胖症的小型知识库
corpus = [
"儿童肥胖症预防需控制高糖饮食,每天运动60分钟以上,避免含糖饮料",
"治疗儿童肥胖症不能节食,需均衡饮食+适度运动,极端病例可就医",
"儿童肥胖的危害包括高血压、糖尿病、心理自卑等,需早干预",
"家庭习惯对儿童肥胖影响大,家长应以身作则,减少视屏时间",
"儿童肥胖症的药物治疗仅适用于重度肥胖,需医生全程监督"
]
# 加载预训练的 SimCSE 编码模型
encoder = SimCSEEncoder(MODEL_NAME)
# 对整个语料库进行向量化处理
corpus_embeddings = encoder.encode(corpus)
# 建立对应的 FAISS 检索索引
faiss_index = build_faiss_index(corpus_embeddings)
# 设定用户查询问题
query = "怎样预防小孩肥胖?"
# 示例运行代码:演示从文档编码到语义检索的完整过程
if __name__ == "__main__":
# 构造一个关于儿童肥胖症的小型知识库
corpus = [
"儿童肥胖症预防需控制高糖饮食,每天运动60分钟以上,避免含糖饮料",
"治疗儿童肥胖症不能节食,需均衡饮食+适度运动,极端病例可就医",
"儿童肥胖的危害包括高血压、糖尿病、心理自卑等,需早干预",
"家庭习惯对儿童肥胖影响大,家长应以身作则,减少视屏时间",
"儿童肥胖症的药物治疗仅适用于重度肥胖,需医生全程监督"
]
# 加载预训练的 SimCSE 编码模型
encoder = SimCSEEncoder(MODEL_NAME)
# 对整个语料库进行向量化处理
corpus_embeddings = encoder.encode(corpus)
# 建立对应的 FAISS 检索索引
faiss_index = build_faiss_index(corpus_embeddings)
# 设定用户查询问题
query = "怎样预防小孩肥胖?"
SimCSE 与传统检索的对比 SimCSE 是“基于表示模型的检索”中的核心方法,其主要优势在于: - 利用极简的自监督对比学习机制,生成具有高区分度的句子嵌入 - 实现从传统的“关键词匹配”向更智能的“语义匹配”跃迁,有效应对同义词、句式改写等复杂查询场景 - 具备良好的可扩展性与适应性,易于部署和微调,适用于大多数中文语义检索任务,如智能问答、RAG系统、文档检索等 在实际应用中,推荐优先选用针对中文优化的 SimCSE 模型(例如 text2vec-base-chinese),并结合 BM25 进行混合检索策略,在保证检索效率的同时提升整体准确率。InfoNCE 损失:对比学习的核心机制 InfoNCE(Information Noise Contrastive Estimation)是对比学习中最经典且广泛使用的损失函数。它通过让模型学会区分“正样本”与“负样本”,从而训练出具备强语义分辨能力的特征表示——这正是 SimCSE 能够产出高质量语义向量的关键所在。 该损失函数本质上是一种归一化的交叉熵形式,其数学表达可通过以下逻辑理解: - 当锚点与正样本之间的相似度显著高于所有负样本时,分子接近分母,log 值趋近于 log(1)=0,整体损失趋于最小 - 若锚点与某些负样本的相似度过高,导致分母远大于分子,则 log 值为较大的负数,损失增大,促使模型继续优化 温度系数 τ 在此过程中起关键作用,控制相似度分布的平滑程度。SimCSE 实验表明,τ 取值 0.05 能较好平衡特征的区分性和泛化能力。 此外,τ 是希腊字母表中的第 19 个字母,英文名称为 "tau"。查询:怎样预防小孩肥胖? 检索结果(Top-3): 1. 相似度:0.9258 | 文档:儿童肥胖症预防需控制高糖饮食,每天运动60分钟以上,避免含糖饮料 2. 相似度:0.7845 | 文档:家庭习惯对儿童肥胖影响大,家长应以身作则,减少视屏时间 3. 相似度:0.6521 | 文档:治疗儿童肥胖症不能节食,需均衡饮食+适度运动,极端病例可就医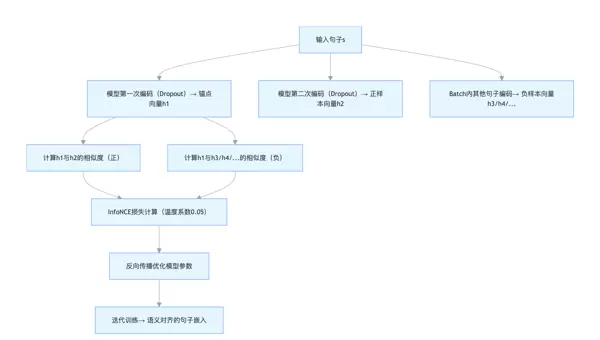
InfoNCE 的工程实现通常借助 batch 内样本互为负例的方式进行高效训练,并可直接转化为标准交叉熵损失进行计算。其核心思想可概括为:“奖励正样本靠近,惩罚负样本干扰”。 SimCSE 无监督版本之所以成功,正是得益于 InfoNCE 损失 + 简单的 Dropout 构造正样本这一组合策略。 SimCSE 检索的关键优化点
- 向量归一化
SimCSE 编码后必须进行 L2 归一化(使用 torch.nn.functional.normalize),原因包括:
- 归一化后,向量内积即等价于余弦相似度,计算更加高效
- 防止句子长度影响向量模长,避免长句天然获得更高相似度得分 - 索引优化
根据文档库规模选择合适的 FAISS 索引策略:
- 小规模库(万级):采用 IndexFlatIP,精度高但速度较慢
- 大规模库(百万至千万级):推荐使用 IndexIVFIP(聚类索引)或 HNSW(图结构索引),在检索速度与准确性之间取得良好平衡 - 领域适配
通用 SimCSE 模型在垂直领域(如医疗、法律)表现有限,建议使用特定领域语料进行微调。
微调核心:构建对比学习样本 + 使用 InfoNCE 损失函数
参考项目地址:https://github.com/princeton-nlp/SimCSE - 混合检索策略
结合 BM25(关键词匹配)与 SimCSE(语义匹配)的优势,利用 RRF(Reciprocal Rank Fusion)对两路结果进行融合,显著提升召回率。
示例代码:
from rrf_fusion import rrf_fusion
bm25_results = ... # BM25 检索输出
simcse_results = ... # SimCSE 检索输出
fused_results = rrf_fusion([bm25_results, simcse_results])
# ====================== 测试示例(SimCSE场景) ======================
# 模拟参数:batch_size=4,hidden_dim=768,num_negatives=3(batch内其他3个样本)
batch_size = 4
hidden_dim = 768
temperature = 0.05
# 模拟锚点、正样本、负样本向量(已归一化)
anchor = F.normalize(torch.randn(batch_size, hidden_dim), p=2, dim=-1)
positive = F.normalize(torch.randn(batch_size, hidden_dim), p=2, dim=-1)
negatives = F.normalize(torch.randn(batch_size, batch_size - 1, hidden_dim), p=2, dim=-1)
# 计算InfoNCE损失
loss = info_nce_loss(anchor, positive, negatives, temperature)
print(f"InfoNCE损失值:{loss.item():.4f}")
"""
:param negatives: 负样本向量 (batch_size, num_negatives, hidden_dim)
:param temperature: 温度系数
:return: 平均损失值
"""
# 步骤1:计算锚点与正样本的相似度(使用内积,因向量已做L2归一化)
sim_pos = torch.sum(anchor * positive, dim=-1) / temperature # 结果维度:(batch_size,)
# 步骤2:计算锚点与全部负样本之间的相似度
sim_neg = torch.matmul(anchor, negatives.transpose(1, 2)) / temperature # 结果维度:(batch_size, num_negatives)
# 步骤3:将正样本和负样本的相似度拼接,构建分类任务所需的logits
logits = torch.cat([sim_pos.unsqueeze(1), sim_neg], dim=1) # 形状变为:(batch_size, 1 + num_negatives)
# 创建标签张量,所有样本中仅正样本位于首位,因此目标类别为0
labels = torch.zeros(logits.shape[0], dtype=torch.long).to(anchor.device)
# 使用交叉熵损失函数进行优化,其形式等价于InfoNCE损失
loss = F.cross_entropy(logits, labels)
return loss

 京公网安备 11010802022788号
京公网安备 11010802022788号







