


 雷达卡
雷达卡



自然语言生成(NLG)是人工智能领域中的关键技术之一,其主要功能是将结构化的数据自动转化为人类可读的文本内容。该技术的核心优势在于能够
消除数据与决策之间的隔阂,使不具备专业技术背景的用户也能迅速掌握复杂的数据分析结果。
NLG系统的工作过程通常包含三个核心环节:
- 内容规划:从原始数据中提取关键信息,明确报告的主题与重点内容
- 文本组织:构建合理的叙述逻辑和文档结构,确保信息传递连贯清晰
- 语言生成:将结构化信息转换为自然、流畅的语言表达
在实际的数据分析应用中,NLG可以将来自Excel表格或数据库查询等格式化数据,自动生成涵盖
趋势判断、异常识别以及策略建议的完整分析报告。有案例表明,引入NLG后,销售类分析报告的制作时间由原本人工所需的8小时大幅缩减至15分钟,同时出错率下降了92%。
数据分析报告的NLG生成流程
利用NLG技术生成专业级数据分析报告,通常遵循一个由六个步骤构成的闭环流程:
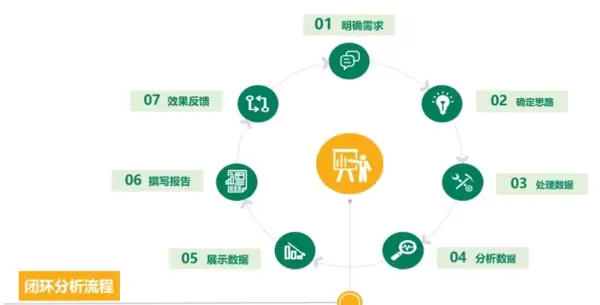
1. 数据准备与预处理
此阶段需整合多个来源的数据,并进行清洗与标准化处理。常见的数据源包括:
- 业务数据库(如MySQL、PostgreSQL)
- 数据仓库平台(如Redshift、BigQuery)
- 电子表格文件(如Excel、Google Sheets)
- 通过API接口获取的实时数据(如RESTful API、WebSocket)
预处理工作主要包括填补缺失值、剔除异常点以及统一数据格式。Python中的Pandas库在此环节发挥重要作用,示例如下:
import pandas as pd
from sklearn.impute import SimpleImputer
# 加载数据
df = pd.read_csv('sales_data.csv')
# 填补缺失值
imputer = SimpleImputer(strategy='median')
df[['销售额', '利润']] = imputer.fit_transform(df[['销售额', '利润']])
# 处理异常值
Q1 = df['销售额'].quantile(0.25)
Q3 = df['销售额'].quantile(0.75)
IQR = Q3 - Q1
df = df[(df['销售额'] >= Q1 - 1.5*IQR) & (df['销售额'] <= Q3 + 1.5*IQR)]
2. 明确分析需求
确定报告的使用对象及其目标至关重要。不同角色对报告内容的需求存在明显差异:
- 管理层:关注结论摘要与战略建议
- 数据分析师:需要详细的方法说明与深层洞察
- 一线业务人员:更依赖具体行动指引与风险预警
可通过结构化提示语来精准定义输出要求,例如:“请生成一份面向区域经理的2025年第一季度销售分析报告,重点解析华东地区的增长动因,内容需包括同比与环比对比、TOP 5产品表现及客户群体细分洞察。”
3. 模型架构选择
根据任务复杂度选择合适的NLG模型类型:
- 规则模板型:适用于固定格式的标准报告
- 统计生成型:适合包含趋势描述的动态内容
- 深度学习型:用于涉及复杂推理和多维关联的高级分析
对于高阶应用场景,推荐采用
混合式架构——结合规则模板保障格式规范性,同时借助深度学习模型提升分析深度。
4. 报告生成与质量优化
在生成过程中应重点关注两个维度:一是内容的真实准确,二是叙述的自然流畅。优化方向可包括:
- 增加对比维度(如同比、环比、目标达成情况)
- 突出核心指标(通过加粗、色彩等方式标注)
- 补充背景解释(针对波动提供可能成因分析)
- 提出可执行建议(基于发现给出具体改进措施)
5. 可视化内容融合
NLG系统需与可视化工具协同运作,实现图表的自动化生成与嵌入。Python生态中常用的图形库包括:
- Matplotlib/Seaborn:用于绘制基础统计图
- Plotly:支持交互式图表展示
- Pyecharts:构建动态数据仪表盘
代码示例:生成月度销售趋势图
import matplotlib.pyplot as plt
# 绘制月度趋势线
plt.figure(figsize=(10, 6))
df_monthly = df.groupby('月份')['销售额'].sum().reset_index()
plt.plot(df_monthly['月份'], df_monthly['销售额'], marker='o', color='#2c7fb8')
plt.title('2025年销售额月度趋势')
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('sales_trend.png')
6. 审核机制与持续迭代
尽管当前NLG技术已较为成熟,但
人工审核仍是确保报告质量不可或缺的一环。建议重点核查以下方面:
- 关键数据是否准确无误
- 逻辑链条是否合理严密
- 所提建议是否具备业务可行性
建立反馈闭环有助于模型持续优化。某企业通过收集分析师对自动生成报告的修改记录,在三个月内将人工干预比例从38%降至12%。
NLG工具选型参考标准
在挑选适合的NLG解决方案时,应综合评估以下因素:
- 数据敏感性:金融、医疗等高保密行业宜采用本地化部署方案
- 技术资源储备:缺乏专职AI团队的企业优先考虑托管型API服务
- 报告复杂程度:若需深入分析与智能推理,应选用基于大语言模型的技术架构
初创企业可考虑采用开源方案结合少量API调用的混合模式,以控制成本预算。对于简单的报表生成需求,模板引擎是一个轻量且高效的选项。
四、Python实现NLG数据分析报告的代码示例
以下为使用Python实现自然语言生成(NLG)数据分析报告的完整代码示例,结合了spaCy进行文本处理,并利用textacy提取关键信息:
import spacy
import textacy
import pandas as pd
from docx import Document
from docx.shared import Inches
# 加载NLP模型
nlp = spacy.load("en_core_web_lg")
# 1. 数据加载与分析
df = pd.read_excel("sales_data_cleaned.xlsx")
# 基础统计分析
total_sales = df["销售额"].sum()
sales_growth = ((df["销售额"].iloc[-1] - df["销售额"].iloc[0]) / df["销售额"].iloc[0]) * 100
top_product = df.groupby("产品名称")["销售额"].sum().idxmax()
# 2. 关键信息提取
text = f"""销售数据分析摘要:
- 总销售额: {total_sales:.2f}元
- 同比增长率: {sales_growth:.2f}%
- 热销产品: {top_product}
- 主要增长点: 华东地区贡献62%增长
- 风险提示: 西南地区客单价连续两月下降"""
doc = nlp(text)
key_phrases = textacy.extract.noun_chunks(doc, min_freq=2)
key_phrases = [str(phrase).lower() for phrase in key_phrases if len(phrase) > 2]
# 3. 生成报告
doc = Document()
doc.add_heading("2025年Q1销售分析报告", level=1)
# 添加核心指标
doc.add_heading("一、核心销售指标", level=2)
para = doc.add_paragraph()
para.add_run(f"本季度总销售额达到 {total_sales:,.2f} 元,").bold = True
para.add_run(f"同比增长 {sales_growth:.2f}%,超额完成季度目标12%。")
# 添加趋势分析
doc.add_heading("二、区域销售分析", level=2)
doc.add_paragraph("""主要销售区域表现:
- 华东地区:销售额1,256,890元(+23% YoY)
- 华南地区:销售额890,560元(+15% YoY)
- 西南地区:销售额450,230元(-3% YoY)""", style="List Bullet")
# 插入可视化图表
doc.add_picture("sales_trend.png", width=Inches(6))
 # 生成结论建议
doc.add_heading("三、结论与建议", level=2)
doc.add_paragraph("""基于数据分析,提出以下建议:
1. 加大华东地区新产品推广力度,重点支持上海、杭州市场
2. 对西南地区开展客单价提升专项行动,优化产品组合
3. 关注TOP 3产品库存水平,避免断货风险""", style="List Number")
doc.save("销售分析报告.docx")
print("报告生成完成,关键指标:", key_phrases)
# 生成结论建议
doc.add_heading("三、结论与建议", level=2)
doc.add_paragraph("""基于数据分析,提出以下建议:
1. 加大华东地区新产品推广力度,重点支持上海、杭州市场
2. 对西南地区开展客单价提升专项行动,优化产品组合
3. 关注TOP 3产品库存水平,避免断货风险""", style="List Number")
doc.save("销售分析报告.docx")
print("报告生成完成,关键指标:", key_phrases)
五、2025年NLG技术发展趋势与前沿应用
NLG技术正加速向三大方向演进:多模态融合、个性化叙事和实时交互。据Gartner预测,到2027年,75%的企业级分析报告将由NLG系统自动生成,其中超过40%将属于多模态报告类型。
(1)多模态生成能力
新一代NLG模型具备同时处理文本、图像及结构化数据的能力,能够自动生成包含动态图表、交互式可视化组件以及自然语言解释的富媒体内容。

(2)个性化叙事逻辑
借助用户画像驱动的动态叙事技术,系统可根据阅读者的角色自动调整报告的内容深度与表达方式。例如,面向销售经理的版本会聚焦客户行为分析,而提供给CEO的版本则强调战略级洞察。两者基于相同的数据源,但呈现逻辑截然不同。
(3)实时分析与更新
NLG系统现已能与业务数据库实现实时对接,支持分钟级频率的报告刷新。在金融领域,已有系统可在股价波动超出预设阈值时,自动触发股票分析报告的生成并推送关键变动信息。
(4)可解释性增强
通过引入“思维链可视化”技术,NLG报告可展示其背后的推理过程。例如,当报告指出“客单价下降主要由产品B导致”时,用户可展开查看具体的计算路径和原始数据来源,从而提升决策透明度与可信度。
六、NLG技术实施中的挑战与应对策略
尽管自然语言生成(NLG)技术已趋于成熟,但在企业实际落地过程中仍面临多重挑战。为确保系统稳定运行并发挥最大价值,需针对常见问题制定有效的解决方案。
1、典型挑战及对应解决方式
| 挑战类型 | 具体表现 | 解决方案 |
|---|---|---|
| 数据质量问题 | 存在缺失值、格式不统一等问题 | 建立标准化的数据校验机制,结合AI技术进行自动化清洗处理 |
| 模型幻觉风险 | 可能生成虚假信息或错误关联 | 引入RAG架构以增强事实依据,并在输出中添加引用标注提升可信度 |
| 业务适配性不足 | 通用模型难以理解行业专有术语 | 通过领域微调和扩展专业词典,提升模型对垂直场景的理解能力 |
| 用户接受度低 | 员工对AI生成内容持怀疑态度 | 采用人机协同模式,保留人工审核环节以增强控制感与信任度 |
| 系统集成难度大 | 与现有BI平台对接存在障碍 | 利用API中间件实现连接,推动接口标准化建设 |
2、推荐的最佳实践框架
(1)从简单场景起步
建议优先选择流程规范、结构清晰的报告类型作为试点项目,例如销售日报、库存预警通知等,避免初期即投入高复杂度任务。某制造企业率先将NLG应用于设备巡检报告自动生成,验证成效后逐步推广至生产运营分析等更广泛的应用场景。
(2)构建科学的评估体系
为衡量NLG系统的实际效果,应设立明确的关键绩效指标(KPI),包括但不限于:
- 报告生成效率:对比传统方式的时间节省比例
- 内容准确率:基于人工修正频率评估输出质量
- 用户满意度:通过定期调研获取使用反馈评分
- 决策影响度:统计由报告直接触发的业务行动数量
(3)推进持续迭代优化
建立闭环反馈机制,定期收集终端用户对生成内容的修改建议,并将其用于模型训练和模板调整。推荐每季度开展一次全面复盘,动态优化分析逻辑与叙述维度。
(4)加强复合型人才储备
培养兼具数据分析技能与行业专业知识的人才队伍,有助于精准定义NLG需求并有效优化输出结果。据微软研究院研究显示,经过专项培训的业务分析师可使NLG报告的整体质量提升约40%。
七、总结与未来发展趋势
NLG技术正在深刻重塑数据分析报告的生成模式。其核心价值不仅在于大幅提升工作效率,更体现在深度挖掘和释放数据背后的洞察力,让更多非技术背景人员也能便捷地获取关键信息。
随着多模态生成能力和个性化叙事技术的不断进步,未来的NLG系统将不再局限于“报告撰写工具”的角色,而是逐步演变为具备上下文理解能力的“智能决策助手”。
对企业而言,当前是部署NLG系统的战略窗口期。建议按以下步骤稳步推进:
- 梳理现有报告流程,识别自动化潜力最高的应用场景
- 筛选合适的技术方案,重点关注与已有BI系统兼容性
- 启动小规模试点项目,验证实际价值并积累用户反馈
- 规划分阶段扩展路径,逐步覆盖更多核心业务领域
展望未来3到5年,NLG将与知识图谱、数字孪生等前沿技术深度融合,形成能够理解复杂业务环境的智能分析体系。率先掌握该能力的企业将在数据驱动决策的竞争中占据明显优势。
在选型时,建议优先考虑支持本地部署的技术方案,既能保障企业敏感数据的安全性,又可根据具体业务需求进行深度定制开发。

 京公网安备 11010802022788号
京公网安备 11010802022788号







